 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Intent to Evidence: A Categorical Approach for Structural Evaluation of Deep Research Agents
Mar 26, 2026Although deep research agents (DRAs) have emerged as a promising paradigm for complex information synthesis, their evaluation remains constrained by ad hoc empirical benchmarks. These heuristic approaches do not rigorously model agent behavior or adequately stress-test long-horizon synthesis and ambiguity resolution. To bridge this gap, we formalize DRA behavior through the lens of category theory, modeling deep research workflow as a composition of structure-preserving maps (functors). Grounded in this theoretical framework, we introduce a novel mechanism-aware benchmark with 296 questions designed to stress-test agents along four interpretable axes: traversing sequential connectivity chains, verifying intersections within V-structure pullbacks, imposing topological ordering on retrieved substructures, and performing ontological falsification via the Yoneda Probe. Our rigorous evaluation of 11 leading models establishes a persistently low baseline, with the state-of-the-art achieving only a 19.9\% average accuracy, exposing the difficulty of formal structural stress-testing. Furthermore, our findings reveal a stark dichotomy in the current AI capabilities. While advanced deep research pipelines successfully redefine dynamic topological re-ordering and exhibit robust ontological verification -- matching pure reasoning models in falsifying hallucinated premises -- they almost universally collapse on multi-hop structural synthesis. Crucially, massive performance variance across tasks exposes a lingering reliance on brittle heuristics rather than a systemic understanding. Ultimately, this work demonstrates that while top-tier autonomous agents can now organically unify search and reasoning, achieving a generalized mastery over complex structural information remains a formidable open challenge.\footnote{Our implementation will be available at https://github.com/tzq1999/CDR.
The Label Horizon Paradox: Rethinking Supervision Targets in Financial Forecasting
Feb 03, 2026While deep learning has revolutionized financial forecasting through sophisticated architectures, the design of the supervision signal itself is rarely scrutinized. We challenge the canonical assumption that training labels must strictly mirror inference targets, uncovering the Label Horizon Paradox: the optimal supervision signal often deviates from the prediction goal, shifting across intermediate horizons governed by market dynamics. We theoretically ground this phenomenon in a dynamic signal-noise trade-off, demonstrating that generalization hinges on the competition between marginal signal realization and noise accumulation. To operationalize this insight, we propose a bi-level optimization framework that autonomously identifies the optimal proxy label within a single training run. Extensive experiments on large-scale financial datasets demonstrate consistent improvements over conventional baselines, thereby opening new avenues for label-centric research in financial forecasting.
Spatial-Spectral Chromatic Coding of Interference Signatures in SAR Imagery: Signal Modeling and Physical-Visual Interpretation
Sep 10, 2025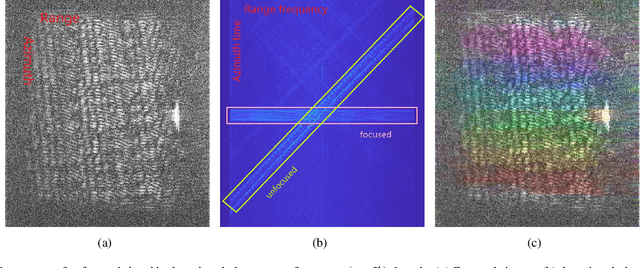
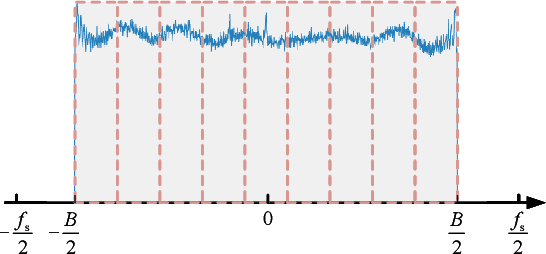
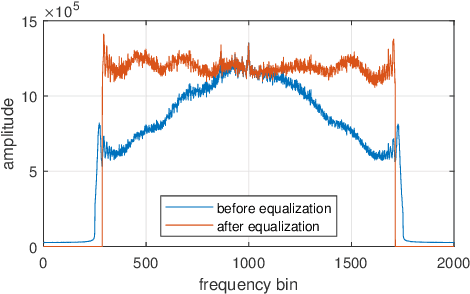
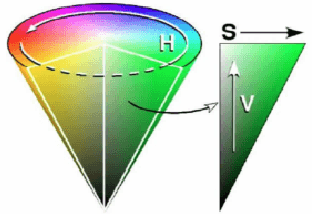
Synthetic Aperture Radar (SAR) images are conventionally visualized as grayscale amplitude representations, which often fail to explicitly reveal interference characteristics caused by external radio emitters and unfocused signals. This paper proposes a novel spatial-spectral chromatic coding method for visual analysis of interference patterns in single-look complex (SLC) SAR imagery. The method first generates a series of spatial-spectral images via spectral subband decomposition that preserve both spatial structures and spectral signatures. These images are subsequently chromatically coded into a color representation using RGB/HSV dual-space coding, using a set of specifically designed color palette. This method intrinsically encodes the spatial-spectral properties of interference into visually discernible patterns, enabling rapid visual interpretation without additional processing. To facilitate physical interpretation, mathematical models are established to theoretically analyze the physical mechanisms of responses to various interference types. Experiments using real datasets demonstrate that the method effectively highlights interference regions and unfocused echo or signal responses (e.g., blurring, ambiguities, and moving target effects), providing analysts with a practical tool for visual interpretation, quality assessment, and data diagnosis in SAR imagery.
Universal Dynamics with Globally Controlled Analog Quantum Simulators
Aug 26, 2025


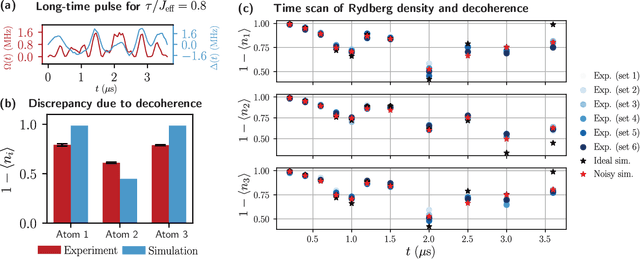
Analog quantum simulators with global control fields have emerged as powerful platforms for exploring complex quantum phenomena. Recent breakthroughs, such as the coherent control of thousands of atoms, highlight the growing potential for quantum applications at scale. Despite these advances, a fundamental theoretical question remains unresolved: to what extent can such systems realize universal quantum dynamics under global control? Here we establish a necessary and sufficient condition for universal quantum computation using only global pulse control, proving that a broad class of analog quantum simulators is, in fact, universal. We further extend this framework to fermionic and bosonic systems, including modern platforms such as ultracold atoms in optical superlattices. Crucially, to connect the theoretical possibility with experimental reality, we introduce a new control technique into the experiment - direct quantum optimal control. This method enables the synthesis of complex effective Hamiltonians and allows us to incorporate realistic hardware constraints. To show its practical power, we experimentally engineer three-body interactions outside the blockade regime and demonstrate topological dynamics on a Rydberg atom array. Using the new control framework, we overcome key experimental challenges, including hardware limitations and atom position fluctuations in the non-blockade regime, by identifying smooth, short-duration pulses that achieve high-fidelity dynamics. Experimental measurements reveal dynamical signatures of symmetry-protected-topological edge modes, confirming both the expressivity and feasibility of our approach. Our work opens a new avenue for quantum simulation beyond native hardware Hamiltonians, enabling the engineering of effective multi-body interactions and advancing the frontier of quantum information processing with globally-controlled analog platforms.
Can ChatGPT Overcome Behavioral Biases in the Financial Sector? Classify-and-Rethink: Multi-Step Zero-Shot Reasoning in the Gold Investment
Nov 19, 2024



Large Language Models (LLMs) have achieved remarkable success recently, displaying exceptional capabilities in creating understandable and organized text. These LLMs have been utilized in diverse fields, such as clinical research, where domain-specific models like Med-Palm have achieved human-level performance. Recently, researchers have employed advanced prompt engineering to enhance the general reasoning ability of LLMs. Despite the remarkable success of zero-shot Chain-of-Thoughts (CoT) in solving general reasoning tasks, the potential of these methods still remains paid limited attention in the financial reasoning task.To address this issue, we explore multiple prompt strategies and incorporated semantic news information to improve LLMs' performance on financial reasoning tasks.To the best of our knowledge, we are the first to explore this important issue by applying ChatGPT to the gold investment.In this work, our aim is to investigate the financial reasoning capabilities of LLMs and their capacity to generate logical and persuasive investment opinions. We will use ChatGPT, one of the most powerful LLMs recently, and prompt engineering to achieve this goal. Our research will focus on understanding the ability of LLMs in sophisticated analysis and reasoning within the context of investment decision-making. Our study finds that ChatGPT with CoT prompt can provide more explainable predictions and overcome behavioral biases, which is crucial in finance-related tasks and can achieve higher investment returns.
Haze-Aware Attention Network for Single-Image Dehazing
Jul 16, 2024



Single-image dehazing is a pivotal challenge in computer vision that seeks to remove haze from images and restore clean background details. Recognizing the limitations of traditional physical model-based methods and the inefficiencies of current attention-based solutions, we propose a new dehazing network combining an innovative Haze-Aware Attention Module (HAAM) with a Multiscale Frequency Enhancement Module (MFEM). The HAAM is inspired by the atmospheric scattering model, thus skillfully integrating physical principles into high-dimensional features for targeted dehazing. It picks up on latent features during the image restoration process, which gives a significant boost to the metrics, while the MFEM efficiently enhances high-frequency details, thus sidestepping wavelet or Fourier transform complexities. It employs multiscale fields to extract and emphasize key frequency components with minimal parameter overhead. Integrated into a simple U-Net framework, our Haze-Aware Attention Network (HAA-Net) for single-image dehazing significantly outperforms existing attention-based and transformer models in efficiency and effectiveness. Tested across various public datasets, the HAA-Net sets new performance benchmarks. Our work not only advances the field of image dehazing but also offers insights into the design of attention mechanisms for broader applications in computer vision.
Vision Transformer with Key-select Routing Attention for Single Image Dehazing
Jun 28, 2024



We present Ksformer, utilizing Multi-scale Key-select Routing Attention (MKRA) for intelligent selection of key areas through multi-channel, multi-scale windows with a top-k operator, and Lightweight Frequency Processing Module (LFPM) to enhance high-frequency features, outperforming other dehazing methods in tests.
Parallel Cross Strip Attention Network for Single Image Dehazing
May 09, 2024



The objective of single image dehazing is to restore hazy images and produce clear, high-quality visuals. Traditional convolutional models struggle with long-range dependencies due to their limited receptive field size. While Transformers excel at capturing such dependencies, their quadratic computational complexity in relation to feature map resolution makes them less suitable for pixel-to-pixel dense prediction tasks. Moreover, fixed kernels or tokens in most models do not adapt well to varying blur sizes, resulting in suboptimal dehazing performance. In this study, we introduce a novel dehazing network based on Parallel Stripe Cross Attention (PCSA) with a multi-scale strategy. PCSA efficiently integrates long-range dependencies by simultaneously capturing horizontal and vertical relationships, allowing each pixel to capture contextual cues from an expanded spatial domain. To handle different sizes and shapes of blurs flexibly, We employs a channel-wise design with varying convolutional kernel sizes and strip lengths in each PCSA to capture context information at different scales.Additionally, we incorporate a softmax-based adaptive weighting mechanism within PCSA to prioritize and leverage more critical features.
Zero-shot Medical Image Translation via Frequency-Guided Diffusion Models
Apr 05, 2023



Recently, the diffusion model has emerged as a superior generative model that can produce high-quality images with excellent realism. There is a growing interest in applying diffusion models to image translation tasks. However, for medical image translation, the existing diffusion models are deficient in accurately retaining structural information since the structure details of source domain images are lost during the forward diffusion process and cannot be fully recovered through learned reverse diffusion, while the integrity of anatomical structures is extremely important in medical images. Training and conditioning diffusion models using paired source and target images with matching anatomy can help. However, such paired data are very difficult and costly to obtain, and may also reduce the robustness of the developed model to out-of-distribution testing data. We propose a frequency-guided diffusion model (FGDM) that employs frequency-domain filters to guide the diffusion model for structure-preserving image translation. Based on its design, FGDM allows zero-shot learning, as it can be trained solely on the data from the target domain, and used directly for source-to-target domain translation without any exposure to the source-domain data during training. We trained FGDM solely on the head-and-neck CT data, and evaluated it on both head-and-neck and lung cone-beam CT (CBCT)-to-CT translation tasks. FGDM outperformed the state-of-the-art methods (GAN-based, VAE-based, and diffusion-based) in all metrics, showing its significant advantages in zero-shot medical image translation.
Conditional Variational Autoencoder with Balanced Pre-training for Generative Adversarial Networks
Jan 13, 2022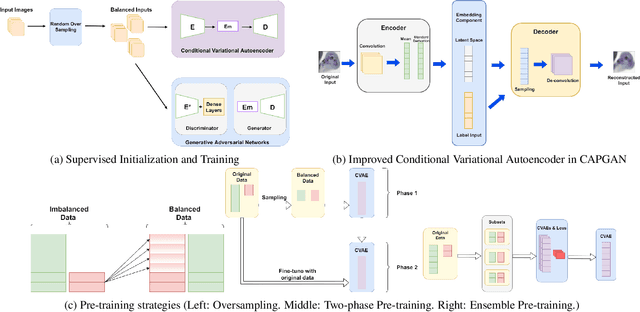
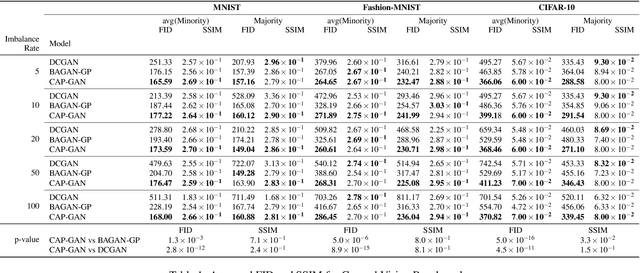
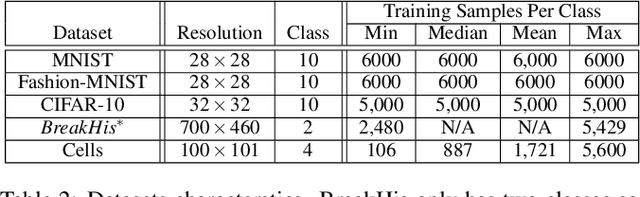
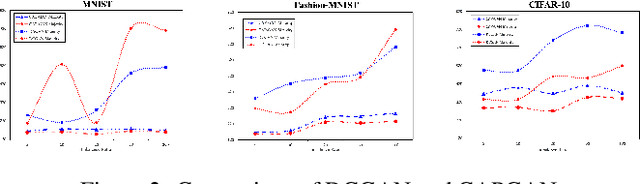
Class imbalance occurs in many real-world applications, including image classification, where the number of images in each class differs significantly. With imbalanced data, the generative adversarial networks (GANs) leans to majority class samples. The two recent methods, Balancing GAN (BAGAN) and improved BAGAN (BAGAN-GP), are proposed as an augmentation tool to handle this problem and restore the balance to the data. The former pre-trains the autoencoder weights in an unsupervised manner. However, it is unstable when the images from different categories have similar features. The latter is improved based on BAGAN by facilitating supervised autoencoder training, but the pre-training is biased towards the majority classes. In this work, we propose a novel Conditional Variational Autoencoder with Balanced Pre-training for Generative Adversarial Networks (CAPGAN) as an augmentation tool to generate realistic synthetic images. In particular, we utilize a conditional convolutional variational autoencoder with supervised and balanced pre-training for the GAN initialization and training with gradient penalty. Our proposed method presents a superior performance of other state-of-the-art methods on the highly imbalanced version of MNIST, Fashion-MNIST, CIFAR-10, and two medical imaging datasets. Our method can synthesize high-quality minority samples in terms of Fr\'echet inception distance, structural similarity index measure and perceptual quality.