 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHaze-Aware Attention Network for Single-Image Dehazing
Jul 16, 2024



Single-image dehazing is a pivotal challenge in computer vision that seeks to remove haze from images and restore clean background details. Recognizing the limitations of traditional physical model-based methods and the inefficiencies of current attention-based solutions, we propose a new dehazing network combining an innovative Haze-Aware Attention Module (HAAM) with a Multiscale Frequency Enhancement Module (MFEM). The HAAM is inspired by the atmospheric scattering model, thus skillfully integrating physical principles into high-dimensional features for targeted dehazing. It picks up on latent features during the image restoration process, which gives a significant boost to the metrics, while the MFEM efficiently enhances high-frequency details, thus sidestepping wavelet or Fourier transform complexities. It employs multiscale fields to extract and emphasize key frequency components with minimal parameter overhead. Integrated into a simple U-Net framework, our Haze-Aware Attention Network (HAA-Net) for single-image dehazing significantly outperforms existing attention-based and transformer models in efficiency and effectiveness. Tested across various public datasets, the HAA-Net sets new performance benchmarks. Our work not only advances the field of image dehazing but also offers insights into the design of attention mechanisms for broader applications in computer vision.
Parallel Cross Strip Attention Network for Single Image Dehazing
May 09, 2024



The objective of single image dehazing is to restore hazy images and produce clear, high-quality visuals. Traditional convolutional models struggle with long-range dependencies due to their limited receptive field size. While Transformers excel at capturing such dependencies, their quadratic computational complexity in relation to feature map resolution makes them less suitable for pixel-to-pixel dense prediction tasks. Moreover, fixed kernels or tokens in most models do not adapt well to varying blur sizes, resulting in suboptimal dehazing performance. In this study, we introduce a novel dehazing network based on Parallel Stripe Cross Attention (PCSA) with a multi-scale strategy. PCSA efficiently integrates long-range dependencies by simultaneously capturing horizontal and vertical relationships, allowing each pixel to capture contextual cues from an expanded spatial domain. To handle different sizes and shapes of blurs flexibly, We employs a channel-wise design with varying convolutional kernel sizes and strip lengths in each PCSA to capture context information at different scales.Additionally, we incorporate a softmax-based adaptive weighting mechanism within PCSA to prioritize and leverage more critical features.
Sparse Sampling Transformer with Uncertainty-Driven Ranking for Unified Removal of Raindrops and Rain Streaks
Aug 27, 2023In the real world, image degradations caused by rain often exhibit a combination of rain streaks and raindrops, thereby increasing the challenges of recovering the underlying clean image. Note that the rain streaks and raindrops have diverse shapes, sizes, and locations in the captured image, and thus modeling the correlation relationship between irregular degradations caused by rain artifacts is a necessary prerequisite for image deraining. This paper aims to present an efficient and flexible mechanism to learn and model degradation relationships in a global view, thereby achieving a unified removal of intricate rain scenes. To do so, we propose a Sparse Sampling Transformer based on Uncertainty-Driven Ranking, dubbed UDR-S2Former. Compared to previous methods, our UDR-S2Former has three merits. First, it can adaptively sample relevant image degradation information to model underlying degradation relationships. Second, explicit application of the uncertainty-driven ranking strategy can facilitate the network to attend to degradation features and understand the reconstruction process. Finally, experimental results show that our UDR-S2Former clearly outperforms state-of-the-art methods for all benchmarks.
NightHazeFormer: Single Nighttime Haze Removal Using Prior Query Transformer
May 16, 2023



Nighttime image dehazing is a challenging task due to the presence of multiple types of adverse degrading effects including glow, haze, blurry, noise, color distortion, and so on. However, most previous studies mainly focus on daytime image dehazing or partial degradations presented in nighttime hazy scenes, which may lead to unsatisfactory restoration results. In this paper, we propose an end-to-end transformer-based framework for nighttime haze removal, called NightHazeFormer. Our proposed approach consists of two stages: supervised pre-training and semi-supervised fine-tuning. During the pre-training stage, we introduce two powerful priors into the transformer decoder to generate the non-learnable prior queries, which guide the model to extract specific degradations. For the fine-tuning, we combine the generated pseudo ground truths with input real-world nighttime hazy images as paired images and feed into the synthetic domain to fine-tune the pre-trained model. This semi-supervised fine-tuning paradigm helps improve the generalization to real domain. In addition, we also propose a large-scale synthetic dataset called UNREAL-NH, to simulate the real-world nighttime haze scenarios comprehensively. Extensive experiments on several synthetic and real-world datasets demonstrate the superiority of our NightHazeFormer over state-of-the-art nighttime haze removal methods in terms of both visually and quantitatively.
Five A$^{+}$ Network: You Only Need 9K Parameters for Underwater Image Enhancement
May 15, 2023A lightweight underwater image enhancement network is of great significance for resource-constrained platforms, but balancing model size, computational efficiency, and enhancement performance has proven difficult for previous approaches. In this work, we propose the Five A$^{+}$ Network (FA$^{+}$Net), a highly efficient and lightweight real-time underwater image enhancement network with only $\sim$ 9k parameters and $\sim$ 0.01s processing time. The FA$^{+}$Net employs a two-stage enhancement structure. The strong prior stage aims to decompose challenging underwater degradations into sub-problems, while the fine-grained stage incorporates multi-branch color enhancement module and pixel attention module to amplify the network's perception of details. To the best of our knowledge, FA$^{+}$Net is the only network with the capability of real-time enhancement of 1080P images. Thorough extensive experiments and comprehensive visual comparison, we show that FA$^{+}$Net outperforms previous approaches by obtaining state-of-the-art performance on multiple datasets while significantly reducing both parameter count and computational complexity. The code is open source at https://github.com/Owen718/FiveAPlus-Network.
DEHRFormer: Real-time Transformer for Depth Estimation and Haze Removal from Varicolored Haze Scenes
Mar 13, 2023



Varicolored haze caused by chromatic casts poses haze removal and depth estimation challenges. Recent learning-based depth estimation methods are mainly targeted at dehazing first and estimating depth subsequently from haze-free scenes. This way, the inner connections between colored haze and scene depth are lost. In this paper, we propose a real-time transformer for simultaneous single image Depth Estimation and Haze Removal (DEHRFormer). DEHRFormer consists of a single encoder and two task-specific decoders. The transformer decoders with learnable queries are designed to decode coupling features from the task-agnostic encoder and project them into clean image and depth map, respectively. In addition, we introduce a novel learning paradigm that utilizes contrastive learning and domain consistency learning to tackle weak-generalization problem for real-world dehazing, while predicting the same depth map from the same scene with varicolored haze. Experiments demonstrate that DEHRFormer achieves significant performance improvement across diverse varicolored haze scenes over previous depth estimation networks and dehazing approaches.
RSFDM-Net: Real-time Spatial and Frequency Domains Modulation Network for Underwater Image Enhancement
Feb 23, 2023



Underwater images typically experience mixed degradations of brightness and structure caused by the absorption and scattering of light by suspended particles. To address this issue, we propose a Real-time Spatial and Frequency Domains Modulation Network (RSFDM-Net) for the efficient enhancement of colors and details in underwater images. Specifically, our proposed conditional network is designed with Adaptive Fourier Gating Mechanism (AFGM) and Multiscale Convolutional Attention Module (MCAM) to generate vectors carrying low-frequency background information and high-frequency detail features, which effectively promote the network to model global background information and local texture details. To more precisely correct the color cast and low saturation of the image, we introduce a Three-branch Feature Extraction (TFE) block in the primary net that processes images pixel by pixel to integrate the color information extended by the same channel (R, G, or B). This block consists of three small branches, each of which has its own weights. Extensive experiments demonstrate that our network significantly outperforms over state-of-the-art methods in both visual quality and quantitative metrics.
Dual-former: Hybrid Self-attention Transformer for Efficient Image Restoration
Oct 03, 2022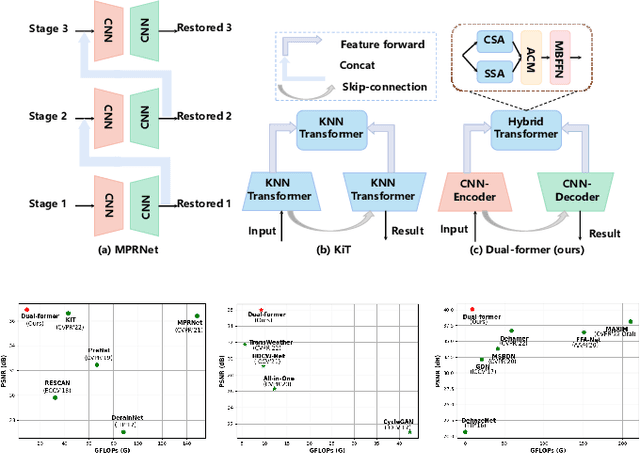

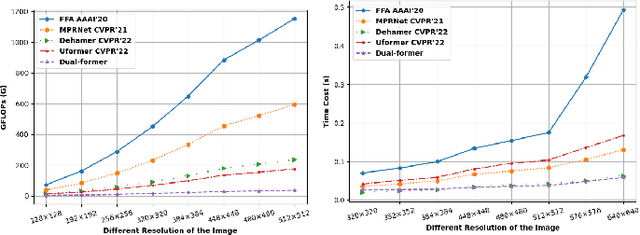
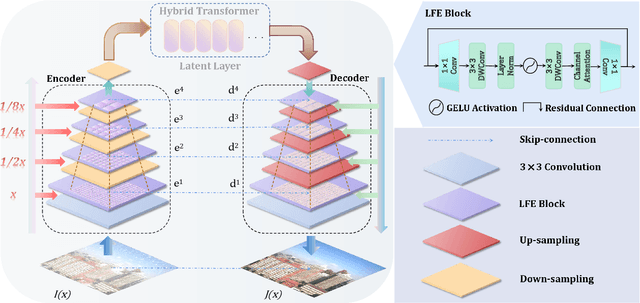
Recently, image restoration transformers have achieved comparable performance with previous state-of-the-art CNNs. However, how to efficiently leverage such architectures remains an open problem. In this work, we present Dual-former whose critical insight is to combine the powerful global modeling ability of self-attention modules and the local modeling ability of convolutions in an overall architecture. With convolution-based Local Feature Extraction modules equipped in the encoder and the decoder, we only adopt a novel Hybrid Transformer Block in the latent layer to model the long-distance dependence in spatial dimensions and handle the uneven distribution between channels. Such a design eliminates the substantial computational complexity in previous image restoration transformers and achieves superior performance on multiple image restoration tasks. Experiments demonstrate that Dual-former achieves a 1.91dB gain over the state-of-the-art MAXIM method on the Indoor dataset for single image dehazing while consuming only 4.2% GFLOPs as MAXIM. For single image deraining, it exceeds the SOTA method by 0.1dB PSNR on the average results of five datasets with only 21.5% GFLOPs. Dual-former also substantially surpasses the latest desnowing method on various datasets, with fewer parameters.
SnowFormer: Scale-aware Transformer via Context Interaction for Single Image Desnowing
Aug 23, 2022
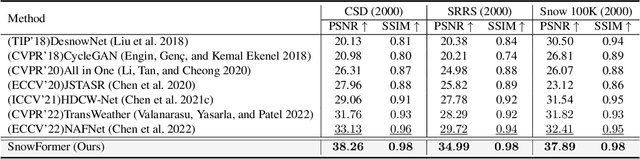
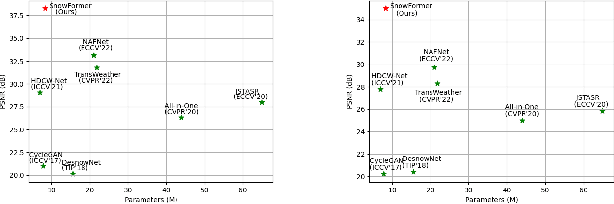
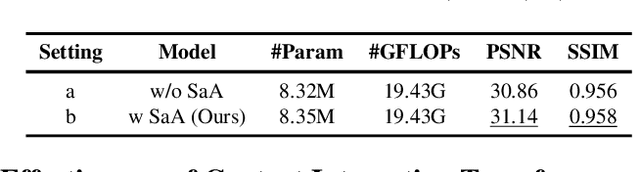
Single image desnowing is a common yet challenging task. The complex snow degradations and diverse degradation scales demand strong representation ability. In order for the desnowing network to see various snow degradations and model the context interaction of local details and global information, we propose a powerful architecture dubbed as SnowFormer. First, it performs Scale-aware Feature Aggregation in the encoder to capture rich snow information of various degradations. Second, in order to tackle with large-scale degradation, it uses a novel Context Interaction Transformer Block in the decoder, which conducts context interaction of local details and global information from previous scale-aware feature aggregation in global context interaction. And the introduction of local context interaction improves recovery of scene details. Third, we devise a Heterogeneous Feature Projection Head which progressively fuse features from both the encoder and decoder and project the refined feature into the clean image. Extensive experiments demonstrate that the proposed SnowFormer achieves significant improvements over other SOTA methods. Compared with SOTA single image desnowing method HDCW-Net, it boosts the PSNR metric by 9.2dB on the CSD testset. Moreover, it also achieves a 5.13dB increase in PSNR compared with general image restoration architecture NAFNet, which verifies the strong representation ability of our SnowFormer for snow removal task. The code is released in \url{https://github.com/Ephemeral182/SnowFormer}.
MSP-Former: Multi-Scale Projection Transformer for Single Image Desnowing
Jul 17, 2022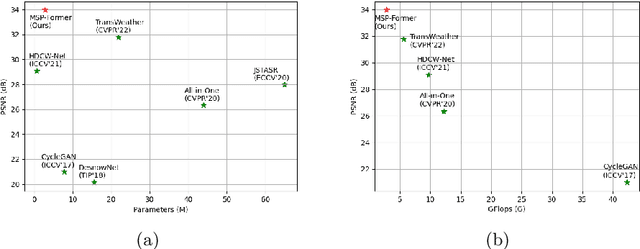
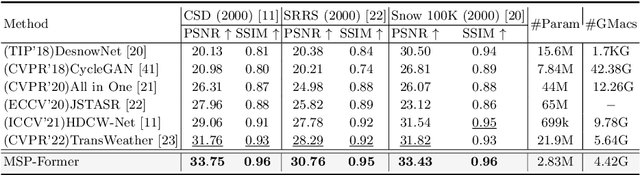

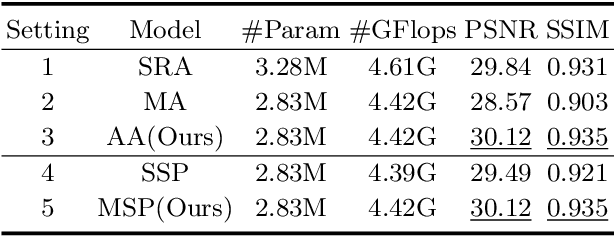
Image restoration of snow scenes in severe weather is a difficult task. Snow images have complex degradations and are cluttered over clean images, changing the distribution of clean images. The previous methods based on CNNs are challenging to remove perfectly in restoring snow scenes due to their local inductive biases' lack of a specific global modeling ability. In this paper, we apply the vision transformer to the task of snow removal from a single image. Specifically, we propose a parallel network architecture split along the channel, performing local feature refinement and global information modeling separately. We utilize a channel shuffle operation to combine their respective strengths to enhance network performance. Second, we propose the MSP module, which utilizes multi-scale avgpool to aggregate information of different sizes and simultaneously performs multi-scale projection self-attention on multi-head self-attention to improve the representation ability of the model under different scale degradations. Finally, we design a lightweight and simple local capture module, which can refine the local capture capability of the model. In the experimental part, we conduct extensive experiments to demonstrate the superiority of our method. We compared the previous snow removal methods on three snow scene datasets. The experimental results show that our method surpasses the state-of-the-art methods with fewer parameters and computation. We achieve substantial growth by 1.99dB and SSIM 0.03 on the CSD test dataset. On the SRRS and Snow100K datasets, we also increased PSNR by 2.47dB and 1.62dB compared with the Transweather approach and improved by 0.03 in SSIM. In the visual comparison section, our MSP-Former also achieves better visual effects than existing methods, proving the usability of our method.