 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMasked Generative Transformer Is What You Need for Image Editing
May 11, 2026Diffusion models dominate image editing, yet their global denoising mechanism entangles edited regions with surrounding context, causing modifications to propagate into areas that should remain intact. We propose a fundamentally different approach by leveraging Masked Generative Transformers (MGTs), whose localized token-prediction paradigm naturally confines changes to intended regions. We present EditMGT, an MGT-based editing framework that is the first of its kind. Our approach employs multi-layer attention consolidation to aggregate cross-attention maps into precise edit localization signals, and region-hold sampling to explicitly prevent token flipping in non-target areas. To support training, we construct CrispEdit-2M, a 2M-sample high-resolution (>1024) editing dataset spanning seven categories. With only 960M parameters, EditMGT achieves state-of-the-art image similarity on multiple benchmarks while delivering 6x faster editing, demonstrating that MGTs offer a compelling alternative to diffusion-based editing.
Threshold-Guided Optimization for Visual Generative Models
May 06, 2026Aligning large visual generative models with human feedback is often performed through pairwise preference optimization. While such approaches are conceptually simple, they fundamentally rely on annotated pairs, limiting scalability in settings where feedback is collected as independent scalar ratings. In this work, we revisit the KL-regularized alignment objective and show that the optimal policy implicitly compares each sample's reward to an instance-specific baseline that is generally intractable. We propose a threshold-guided alignment framework that replaces this oracle baseline with a data-driven global threshold estimated from empirical score statistics. This formulation turns alignment into a binary decision task on unpaired data, enabling effective optimization directly from scalar feedback. We also incorporate a confidence weighting term to emphasize samples whose scores deviate strongly from the threshold, improving sample efficiency. Experiments across both diffusion and masked generative paradigms, spanning three test sets and five reward models, show that our method consistently improves preference alignment over previous methods. These results position our threshold-guided framework as a simple yet principled alternative for aligning visual generative models without paired comparisons.
Rethinking the Design Space of Reinforcement Learning for Diffusion Models: On the Importance of Likelihood Estimation Beyond Loss Design
Feb 04, 2026Reinforcement learning has been widely applied to diffusion and flow models for visual tasks such as text-to-image generation. However, these tasks remain challenging because diffusion models have intractable likelihoods, which creates a barrier for directly applying popular policy-gradient type methods. Existing approaches primarily focus on crafting new objectives built on already heavily engineered LLM objectives, using ad hoc estimators for likelihood, without a thorough investigation into how such estimation affects overall algorithmic performance. In this work, we provide a systematic analysis of the RL design space by disentangling three factors: i) policy-gradient objectives, ii) likelihood estimators, and iii) rollout sampling schemes. We show that adopting an evidence lower bound (ELBO) based model likelihood estimator, computed only from the final generated sample, is the dominant factor enabling effective, efficient, and stable RL optimization, outweighing the impact of the specific policy-gradient loss functional. We validate our findings across multiple reward benchmarks using SD 3.5 Medium, and observe consistent trends across all tasks. Our method improves the GenEval score from 0.24 to 0.95 in 90 GPU hours, which is $4.6\times$ more efficient than FlowGRPO and $2\times$ more efficient than the SOTA method DiffusionNFT without reward hacking.
Prism: Efficient Test-Time Scaling via Hierarchical Search and Self-Verification for Discrete Diffusion Language Models
Feb 02, 2026Inference-time compute has re-emerged as a practical way to improve LLM reasoning. Most test-time scaling (TTS) algorithms rely on autoregressive decoding, which is ill-suited to discrete diffusion language models (dLLMs) due to their parallel decoding over the entire sequence. As a result, developing effective and efficient TTS methods to unlock dLLMs' full generative potential remains an underexplored challenge. To address this, we propose Prism (Pruning, Remasking, and Integrated Self-verification Method), an efficient TTS framework for dLLMs that (i) performs Hierarchical Trajectory Search (HTS) which dynamically prunes and reallocates compute in an early-to-mid denoising window, (ii) introduces Local branching with partial remasking to explore diverse implementations while preserving high-confidence tokens, and (iii) replaces external verifiers with Self-Verified Feedback (SVF) obtained via self-evaluation prompts on intermediate completions. Across four mathematical reasoning and code generation benchmarks on three dLLMs, including LLaDA 8B Instruct, Dream 7B Instruct, and LLaDA 2.0-mini, our Prism achieves a favorable performance-efficiency trade-off, matching best-of-N performance with substantially fewer function evaluations (NFE). The code is released at https://github.com/viiika/Prism.
dMLLM-TTS: Self-Verified and Efficient Test-Time Scaling for Diffusion Multi-Modal Large Language Models
Dec 22, 2025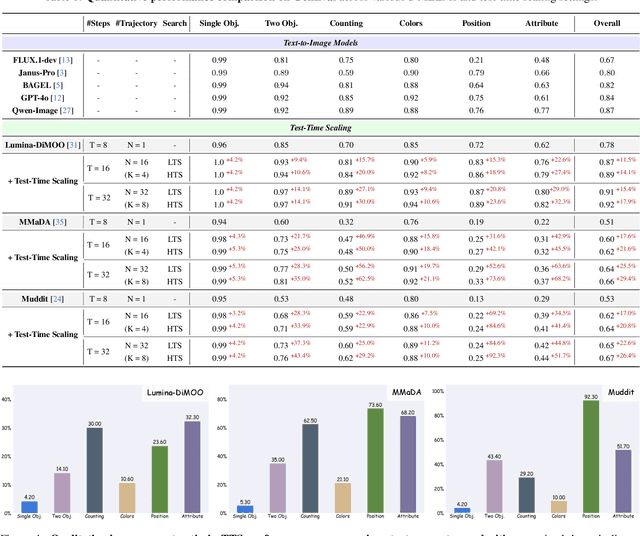

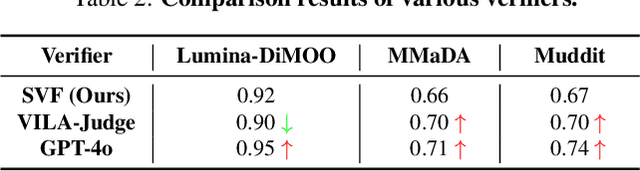
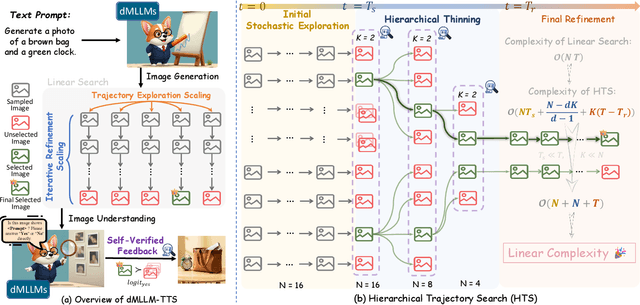
Diffusion Multi-modal Large Language Models (dMLLMs) have recently emerged as a novel architecture unifying image generation and understanding. However, developing effective and efficient Test-Time Scaling (TTS) methods to unlock their full generative potential remains an underexplored challenge. To address this, we propose dMLLM-TTS, a novel framework operating on two complementary scaling axes: (1) trajectory exploration scaling to enhance the diversity of generated hypotheses, and (2) iterative refinement scaling for stable generation. Conventional TTS approaches typically perform linear search across these two dimensions, incurring substantial computational costs of O(NT) and requiring an external verifier for best-of-N selection. To overcome these limitations, we propose two innovations. First, we design an efficient hierarchical search algorithm with O(N+T) complexity that adaptively expands and prunes sampling trajectories. Second, we introduce a self-verified feedback mechanism that leverages the dMLLMs' intrinsic image understanding capabilities to assess text-image alignment, eliminating the need for external verifier. Extensive experiments on the GenEval benchmark across three representative dMLLMs (e.g., Lumina-DiMOO, MMaDA, Muddit) show that our framework substantially improves generation quality while achieving up to 6x greater efficiency than linear search. Project page: https://github.com/Alpha-VLLM/Lumina-DiMOO.
RecTok: Reconstruction Distillation along Rectified Flow
Dec 17, 2025Visual tokenizers play a crucial role in diffusion models. The dimensionality of latent space governs both reconstruction fidelity and the semantic expressiveness of the latent feature. However, a fundamental trade-off is inherent between dimensionality and generation quality, constraining existing methods to low-dimensional latent spaces. Although recent works have leveraged vision foundation models to enrich the semantics of visual tokenizers and accelerate convergence, high-dimensional tokenizers still underperform their low-dimensional counterparts. In this work, we propose RecTok, which overcomes the limitations of high-dimensional visual tokenizers through two key innovations: flow semantic distillation and reconstruction--alignment distillation. Our key insight is to make the forward flow in flow matching semantically rich, which serves as the training space of diffusion transformers, rather than focusing on the latent space as in previous works. Specifically, our method distills the semantic information in VFMs into the forward flow trajectories in flow matching. And we further enhance the semantics by introducing a masked feature reconstruction loss. Our RecTok achieves superior image reconstruction, generation quality, and discriminative performance. It achieves state-of-the-art results on the gFID-50K under both with and without classifier-free guidance settings, while maintaining a semantically rich latent space structure. Furthermore, as the latent dimensionality increases, we observe consistent improvements. Code and model are available at https://shi-qingyu.github.io/rectok.github.io.
EditMGT: Unleashing Potentials of Masked Generative Transformers in Image Editing
Dec 12, 2025Recent advances in diffusion models (DMs) have achieved exceptional visual quality in image editing tasks. However, the global denoising dynamics of DMs inherently conflate local editing targets with the full-image context, leading to unintended modifications in non-target regions. In this paper, we shift our attention beyond DMs and turn to Masked Generative Transformers (MGTs) as an alternative approach to tackle this challenge. By predicting multiple masked tokens rather than holistic refinement, MGTs exhibit a localized decoding paradigm that endows them with the inherent capacity to explicitly preserve non-relevant regions during the editing process. Building upon this insight, we introduce the first MGT-based image editing framework, termed EditMGT. We first demonstrate that MGT's cross-attention maps provide informative localization signals for localizing edit-relevant regions and devise a multi-layer attention consolidation scheme that refines these maps to achieve fine-grained and precise localization. On top of these adaptive localization results, we introduce region-hold sampling, which restricts token flipping within low-attention areas to suppress spurious edits, thereby confining modifications to the intended target regions and preserving the integrity of surrounding non-target areas. To train EditMGT, we construct CrispEdit-2M, a high-resolution dataset spanning seven diverse editing categories. Without introducing additional parameters, we adapt a pre-trained text-to-image MGT into an image editing model through attention injection. Extensive experiments across four standard benchmarks demonstrate that, with fewer than 1B parameters, our model achieves similarity performance while enabling 6 times faster editing. Moreover, it delivers comparable or superior editing quality, with improvements of 3.6% and 17.6% on style change and style transfer tasks, respectively.
From Masks to Worlds: A Hitchhiker's Guide to World Models
Oct 23, 2025This is not a typical survey of world models; it is a guide for those who want to build worlds. We do not aim to catalog every paper that has ever mentioned a ``world model". Instead, we follow one clear road: from early masked models that unified representation learning across modalities, to unified architectures that share a single paradigm, then to interactive generative models that close the action-perception loop, and finally to memory-augmented systems that sustain consistent worlds over time. We bypass loosely related branches to focus on the core: the generative heart, the interactive loop, and the memory system. We show that this is the most promising path towards true world models.
Muddit: Liberating Generation Beyond Text-to-Image with a Unified Discrete Diffusion Model
May 29, 2025Unified generation models aim to handle diverse tasks across modalities -- such as text generation, image generation, and vision-language reasoning -- within a single architecture and decoding paradigm. Autoregressive unified models suffer from slow inference due to sequential decoding, and non-autoregressive unified models suffer from weak generalization due to limited pretrained backbones. We introduce Muddit, a unified discrete diffusion transformer that enables fast and parallel generation across both text and image modalities. Unlike prior unified diffusion models trained from scratch, Muddit integrates strong visual priors from a pretrained text-to-image backbone with a lightweight text decoder, enabling flexible and high-quality multimodal generation under a unified architecture. Empirical results show that Muddit achieves competitive or superior performance compared to significantly larger autoregressive models in both quality and efficiency. The work highlights the potential of purely discrete diffusion, when equipped with strong visual priors, as a scalable and effective backbone for unified generation.
Conditional Panoramic Image Generation via Masked Autoregressive Modeling
May 22, 2025
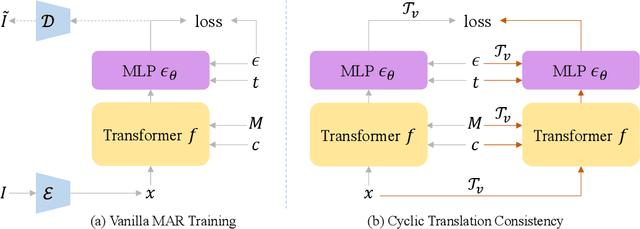
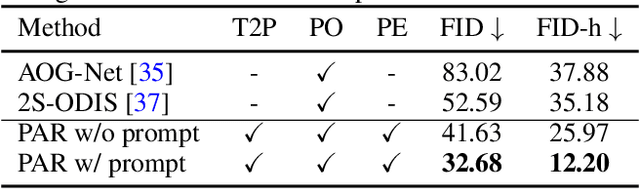

Recent progress in panoramic image generation has underscored two critical limitations in existing approaches. First, most methods are built upon diffusion models, which are inherently ill-suited for equirectangular projection (ERP) panoramas due to the violation of the identically and independently distributed (i.i.d.) Gaussian noise assumption caused by their spherical mapping. Second, these methods often treat text-conditioned generation (text-to-panorama) and image-conditioned generation (panorama outpainting) as separate tasks, relying on distinct architectures and task-specific data. In this work, we propose a unified framework, Panoramic AutoRegressive model (PAR), which leverages masked autoregressive modeling to address these challenges. PAR avoids the i.i.d. assumption constraint and integrates text and image conditioning into a cohesive architecture, enabling seamless generation across tasks. To address the inherent discontinuity in existing generative models, we introduce circular padding to enhance spatial coherence and propose a consistency alignment strategy to improve generation quality. Extensive experiments demonstrate competitive performance in text-to-image generation and panorama outpainting tasks while showcasing promising scalability and generalization capabilities.