 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining-Free Image Editing with Visual Context Integration and Concept Alignment
Apr 06, 2026In image editing, it is essential to incorporate a context image to convey the user's precise requirements, such as subject appearance or image style. Existing training-based visual context-aware editing methods incur data collection effort and training cost. On the other hand, the training-free alternatives are typically established on diffusion inversion, which struggles with consistency and flexibility. In this work, we propose VicoEdit, a training-free and inversion-free method to inject the visual context into the pretrained text-prompted editing model. More specifically, VicoEdit directly transforms the source image into the target one based on the visual context, thereby eliminating the need for inversion that can lead to deviated trajectories. Moreover, we design a posterior sampling approach guided by concept alignment to enhance the editing consistency. Empirical results demonstrate that our training-free method achieves even better editing performance than the state-of-the-art training-based models.
Unified Multimodal Understanding and Generation Models: Advances, Challenges, and Opportunities
May 05, 2025

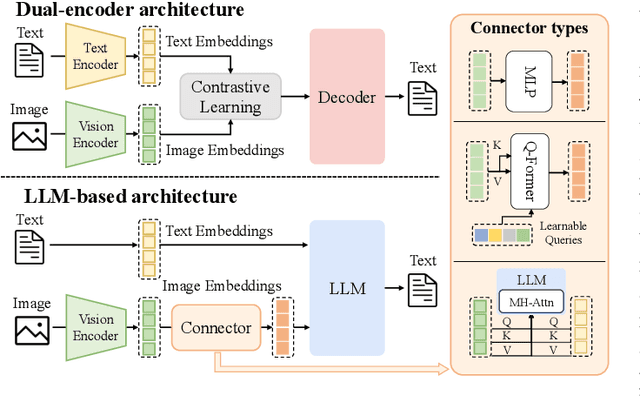

Recent years have seen remarkable progress in both multimodal understanding models and image generation models. Despite their respective successes, these two domains have evolved independently, leading to distinct architectural paradigms: While autoregressive-based architectures have dominated multimodal understanding, diffusion-based models have become the cornerstone of image generation. Recently, there has been growing interest in developing unified frameworks that integrate these tasks. The emergence of GPT-4o's new capabilities exemplifies this trend, highlighting the potential for unification. However, the architectural differences between the two domains pose significant challenges. To provide a clear overview of current efforts toward unification, we present a comprehensive survey aimed at guiding future research. First, we introduce the foundational concepts and recent advancements in multimodal understanding and text-to-image generation models. Next, we review existing unified models, categorizing them into three main architectural paradigms: diffusion-based, autoregressive-based, and hybrid approaches that fuse autoregressive and diffusion mechanisms. For each category, we analyze the structural designs and innovations introduced by related works. Additionally, we compile datasets and benchmarks tailored for unified models, offering resources for future exploration. Finally, we discuss the key challenges facing this nascent field, including tokenization strategy, cross-modal attention, and data. As this area is still in its early stages, we anticipate rapid advancements and will regularly update this survey. Our goal is to inspire further research and provide a valuable reference for the community. The references associated with this survey will be available on GitHub soon.
CHATS: Combining Human-Aligned Optimization and Test-Time Sampling for Text-to-Image Generation
Feb 18, 2025



Diffusion models have emerged as a dominant approach for text-to-image generation. Key components such as the human preference alignment and classifier-free guidance play a crucial role in ensuring generation quality. However, their independent application in current text-to-image models continues to face significant challenges in achieving strong text-image alignment, high generation quality, and consistency with human aesthetic standards. In this work, we for the first time, explore facilitating the collaboration of human performance alignment and test-time sampling to unlock the potential of text-to-image models. Consequently, we introduce CHATS (Combining Human-Aligned optimization and Test-time Sampling), a novel generative framework that separately models the preferred and dispreferred distributions and employs a proxy-prompt-based sampling strategy to utilize the useful information contained in both distributions. We observe that CHATS exhibits exceptional data efficiency, achieving strong performance with only a small, high-quality funetuning dataset. Extensive experiments demonstrate that CHATS surpasses traditional preference alignment methods, setting new state-of-the-art across various standard benchmarks.
Evaluating Image Caption via Cycle-consistent Text-to-Image Generation
Jan 08, 2025



Evaluating image captions typically relies on reference captions, which are costly to obtain and exhibit significant diversity and subjectivity. While reference-free evaluation metrics have been proposed, most focus on cross-modal evaluation between captions and images. Recent research has revealed that the modality gap generally exists in the representation of contrastive learning-based multi-modal systems, undermining the reliability of cross-modality metrics like CLIPScore. In this paper, we propose CAMScore, a cyclic reference-free automatic evaluation metric for image captioning models. To circumvent the aforementioned modality gap, CAMScore utilizes a text-to-image model to generate images from captions and subsequently evaluates these generated images against the original images. Furthermore, to provide fine-grained information for a more comprehensive evaluation, we design a three-level evaluation framework for CAMScore that encompasses pixel-level, semantic-level, and objective-level perspectives. Extensive experiment results across multiple benchmark datasets show that CAMScore achieves a superior correlation with human judgments compared to existing reference-based and reference-free metrics, demonstrating the effectiveness of the framework.
Dense Vision Transformer Compression with Few Samples
Mar 27, 2024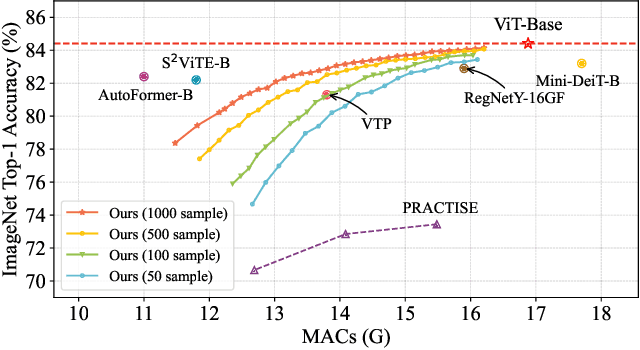
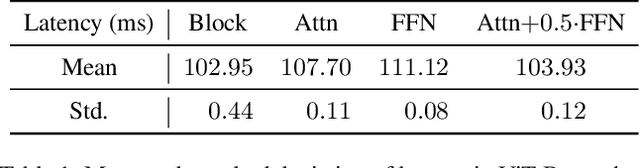
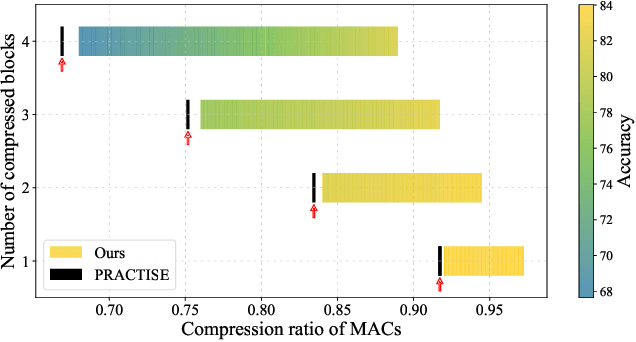
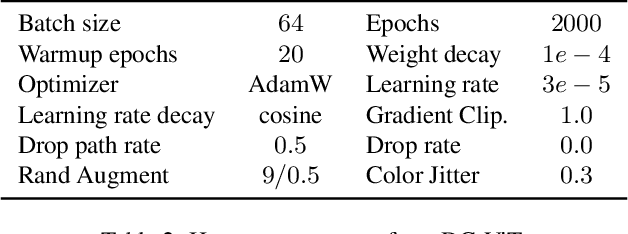
Few-shot model compression aims to compress a large model into a more compact one with only a tiny training set (even without labels). Block-level pruning has recently emerged as a leading technique in achieving high accuracy and low latency in few-shot CNN compression. But, few-shot compression for Vision Transformers (ViT) remains largely unexplored, which presents a new challenge. In particular, the issue of sparse compression exists in traditional CNN few-shot methods, which can only produce very few compressed models of different model sizes. This paper proposes a novel framework for few-shot ViT compression named DC-ViT. Instead of dropping the entire block, DC-ViT selectively eliminates the attention module while retaining and reusing portions of the MLP module. DC-ViT enables dense compression, which outputs numerous compressed models that densely populate the range of model complexity. DC-ViT outperforms state-of-the-art few-shot compression methods by a significant margin of 10 percentage points, along with lower latency in the compression of ViT and its variants.
Practical Network Acceleration with Tiny Sets: Hypothesis, Theory, and Algorithm
Mar 02, 2023



Due to data privacy issues, accelerating networks with tiny training sets has become a critical need in practice. Previous methods achieved promising results empirically by filter-level pruning. In this paper, we both study this problem theoretically and propose an effective algorithm aligning well with our theoretical results. First, we propose the finetune convexity hypothesis to explain why recent few-shot compression algorithms do not suffer from overfitting problems. Based on it, a theory is further established to explain these methods for the first time. Compared to naively finetuning a pruned network, feature mimicking is proved to achieve a lower variance of parameters and hence enjoys easier optimization. With our theoretical conclusions, we claim dropping blocks is a fundamentally superior few-shot compression scheme in terms of more convex optimization and a higher acceleration ratio. To choose which blocks to drop, we propose a new metric, recoverability, to effectively measure the difficulty of recovering the compressed network. Finally, we propose an algorithm named PRACTISE to accelerate networks using only tiny training sets. PRACTISE outperforms previous methods by a significant margin. For 22% latency reduction, it surpasses previous methods by on average 7 percentage points on ImageNet-1k. It also works well under data-free or out-of-domain data settings. Our code is at https://github.com/DoctorKey/Practise
EVC: Towards Real-Time Neural Image Compression with Mask Decay
Feb 10, 2023



Neural image compression has surpassed state-of-the-art traditional codecs (H.266/VVC) for rate-distortion (RD) performance, but suffers from large complexity and separate models for different rate-distortion trade-offs. In this paper, we propose an Efficient single-model Variable-bit-rate Codec (EVC), which is able to run at 30 FPS with 768x512 input images and still outperforms VVC for the RD performance. By further reducing both encoder and decoder complexities, our small model even achieves 30 FPS with 1920x1080 input images. To bridge the performance gap between our different capacities models, we meticulously design the mask decay, which transforms the large model's parameters into the small model automatically. And a novel sparsity regularization loss is proposed to mitigate shortcomings of $L_p$ regularization. Our algorithm significantly narrows the performance gap by 50% and 30% for our medium and small models, respectively. At last, we advocate the scalable encoder for neural image compression. The encoding complexity is dynamic to meet different latency requirements. We propose decaying the large encoder multiple times to reduce the residual representation progressively. Both mask decay and residual representation learning greatly improve the RD performance of our scalable encoder. Our code is at https://github.com/microsoft/DCVC.
How to Reduce Change Detection to Semantic Segmentation
Jun 15, 2022
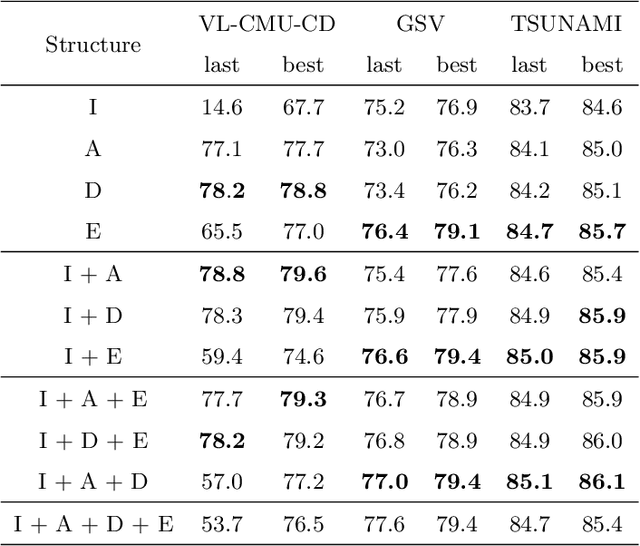
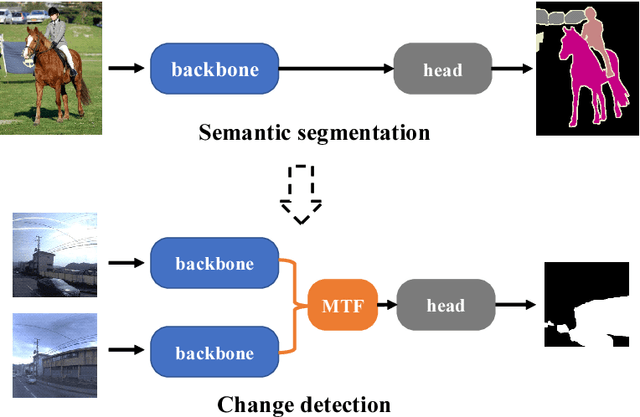
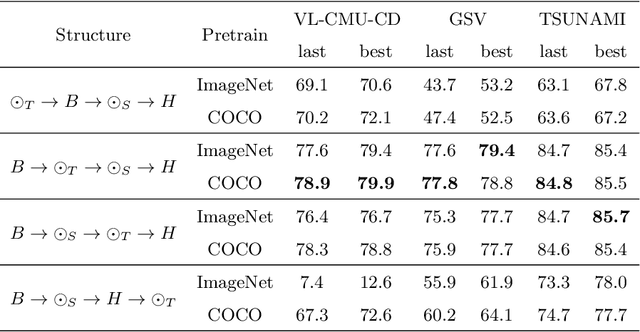
Change detection (CD) aims to identify changes that occur in an image pair taken different times. Prior methods devise specific networks from scratch to predict change masks in pixel-level, and struggle with general segmentation problems. In this paper, we propose a new paradigm that reduces CD to semantic segmentation which means tailoring an existing and powerful semantic segmentation network to solve CD. This new paradigm conveniently enjoys the mainstream semantic segmentation techniques to deal with general segmentation problems in CD. Hence we can concentrate on studying how to detect changes. We propose a novel and importance insight that different change types exist in CD and they should be learned separately. Based on it, we devise a module named MTF to extract the change information and fuse temporal features. MTF enjoys high interpretability and reveals the essential characteristic of CD. And most segmentation networks can be adapted to solve the CD problems with our MTF module. Finally, we propose C-3PO, a network to detect changes at pixel-level. C-3PO achieves state-of-the-art performance without bells and whistles. It is simple but effective and can be considered as a new baseline in this field. Our code will be available.
R2-D2: Repetitive Reprediction Deep Decipher for Semi-Supervised Deep Learning
Feb 18, 2022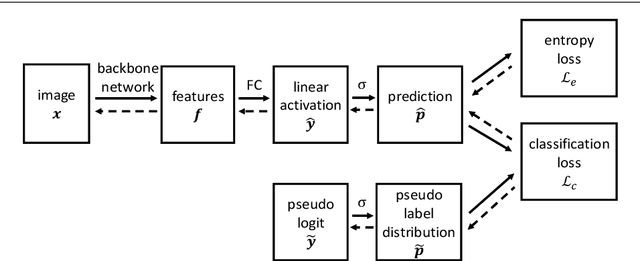
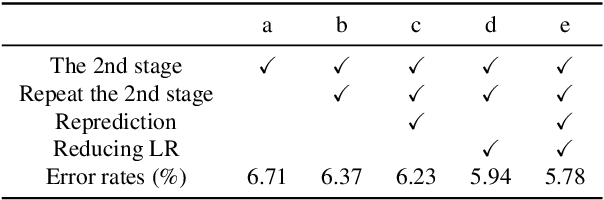

Most recent semi-supervised deep learning (deep SSL) methods used a similar paradigm: use network predictions to update pseudo-labels and use pseudo-labels to update network parameters iteratively. However, they lack theoretical support and cannot explain why predictions are good candidates for pseudo-labels in the deep learning paradigm. In this paper, we propose a principled end-to-end framework named deep decipher (D2) for SSL. Within the D2 framework, we prove that pseudo-labels are related to network predictions by an exponential link function, which gives a theoretical support for using predictions as pseudo-labels. Furthermore, we demonstrate that updating pseudo-labels by network predictions will make them uncertain. To mitigate this problem, we propose a training strategy called repetitive reprediction (R2). Finally, the proposed R2-D2 method is tested on the large-scale ImageNet dataset and outperforms state-of-the-art methods by 5 percentage points.
PENCIL: Deep Learning with Noisy Labels
Feb 17, 2022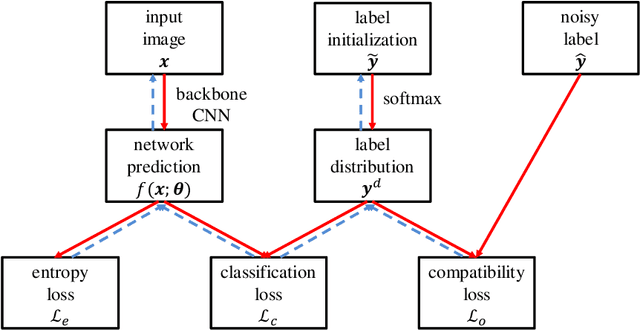
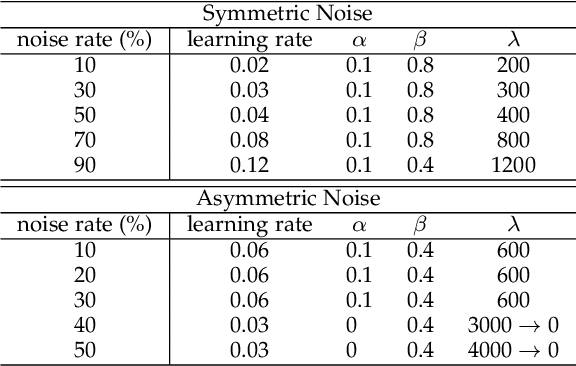

Deep learning has achieved excellent performance in various computer vision tasks, but requires a lot of training examples with clean labels. It is easy to collect a dataset with noisy labels, but such noise makes networks overfit seriously and accuracies drop dramatically. To address this problem, we propose an end-to-end framework called PENCIL, which can update both network parameters and label estimations as label distributions. PENCIL is independent of the backbone network structure and does not need an auxiliary clean dataset or prior information about noise, thus it is more general and robust than existing methods and is easy to apply. PENCIL can even be used repeatedly to obtain better performance. PENCIL outperforms previous state-of-the-art methods by large margins on both synthetic and real-world datasets with different noise types and noise rates. And PENCIL is also effective in multi-label classification tasks through adding a simple attention structure on backbone networks. Experiments show that PENCIL is robust on clean datasets, too.