 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSkillEvolBench: Benchmarking the Evolution from Episodic Experience to Procedural Skills
May 22, 2026Large language model (LLM) agents accumulate rich episodic trajectories while solving real-world tasks, but it remains unclear whether such experience can be distilled into reusable procedural skills. We introduce SkillEvolBench, a diagnostic benchmark for evaluating this step from experience reuse to skill formation. It contains 180 tasks across six real-world agent environments, organized into role-conditioned task families with shared latent procedures. Agents learn from acquisition tasks, update an external skill library using compacted trajectories and verifier feedback, and then face frozen deployment tasks testing context shift, adversarial shortcuts, and composition. By comparing self-generated and curated-start skill evolution against no-skill and raw-trajectory controls, SkillEvolBench separates procedural abstraction from base capability, curated prior knowledge, and direct reuse of episodic traces. Across ten model configurations and three agent harnesses, we find that current agents often adapt locally but rarely form robust reusable skills. Skill-based conditions can improve acquisition or replay, and individual models sometimes gain on specific deployment axes, but these gains are unstable under frozen deployment. Raw-trajectory reuse frequently outperforms distilled skills, suggesting that current abstraction procedures discard contextual and procedural cues that remain useful for future tasks. Capacity and cost analyses further show that writing more skills or larger Tier-3 resource libraries is not sufficient: additional updates can improve coverage while introducing episode-specific drift and procedural clutter. These findings position SkillEvolBench as a testbed for measuring when one-off experience becomes durable procedural knowledge rather than task-local memory.
OmniShow: Unifying Multimodal Conditions for Human-Object Interaction Video Generation
Apr 13, 2026In this work, we study Human-Object Interaction Video Generation (HOIVG), which aims to synthesize high-quality human-object interaction videos conditioned on text, reference images, audio, and pose. This task holds significant practical value for automating content creation in real-world applications, such as e-commerce demonstrations, short video production, and interactive entertainment. However, existing approaches fail to accommodate all these requisite conditions. We present OmniShow, an end-to-end framework tailored for this practical yet challenging task, capable of harmonizing multimodal conditions and delivering industry-grade performance. To overcome the trade-off between controllability and quality, we introduce Unified Channel-wise Conditioning for efficient image and pose injection, and Gated Local-Context Attention to ensure precise audio-visual synchronization. To effectively address data scarcity, we develop a Decoupled-Then-Joint Training strategy that leverages a multi-stage training process with model merging to efficiently harness heterogeneous sub-task datasets. Furthermore, to fill the evaluation gap in this field, we establish HOIVG-Bench, a dedicated and comprehensive benchmark for HOIVG. Extensive experiments demonstrate that OmniShow achieves overall state-of-the-art performance across various multimodal conditioning settings, setting a solid standard for the emerging HOIVG task.
HiFi-Inpaint: Towards High-Fidelity Reference-Based Inpainting for Generating Detail-Preserving Human-Product Images
Mar 03, 2026Human-product images, which showcase the integration of humans and products, play a vital role in advertising, e-commerce, and digital marketing. The essential challenge of generating such images lies in ensuring the high-fidelity preservation of product details. Among existing paradigms, reference-based inpainting offers a targeted solution by leveraging product reference images to guide the inpainting process. However, limitations remain in three key aspects: the lack of diverse large-scale training data, the struggle of current models to focus on product detail preservation, and the inability of coarse supervision for achieving precise guidance. To address these issues, we propose HiFi-Inpaint, a novel high-fidelity reference-based inpainting framework tailored for generating human-product images. HiFi-Inpaint introduces Shared Enhancement Attention (SEA) to refine fine-grained product features and Detail-Aware Loss (DAL) to enforce precise pixel-level supervision using high-frequency maps. Additionally, we construct a new dataset, HP-Image-40K, with samples curated from self-synthesis data and processed with automatic filtering. Experimental results show that HiFi-Inpaint achieves state-of-the-art performance, delivering detail-preserving human-product images.
DSDR: Dual-Scale Diversity Regularization for Exploration in LLM Reasoning
Feb 23, 2026Reinforcement learning with verifiers (RLVR) is a central paradigm for improving large language model (LLM) reasoning, yet existing methods often suffer from limited exploration. Policies tend to collapse onto a few reasoning patterns and prematurely stop deep exploration, while conventional entropy regularization introduces only local stochasticity and fails to induce meaningful path-level diversity, leading to weak and unstable learning signals in group-based policy optimization. We propose DSDR, a Dual-Scale Diversity Regularization reinforcement learning framework that decomposes diversity in LLM reasoning into global and coupling components. Globally, DSDR promotes diversity among correct reasoning trajectories to explore distinct solution modes. Locally, it applies a length-invariant, token-level entropy regularization restricted to correct trajectories, preventing entropy collapse within each mode while preserving correctness. The two scales are coupled through a global-to-local allocation mechanism that emphasizes local regularization for more distinctive correct trajectories. We provide theoretical support showing that DSDR preserves optimal correctness under bounded regularization, sustains informative learning signals in group-based optimization, and yields a principled global-to-local coupling rule. Experiments on multiple reasoning benchmarks demonstrate consistent improvements in accuracy and pass@k, highlighting the importance of dual-scale diversity for deep exploration in RLVR. Code is available at https://github.com/SUSTechBruce/DSDR.
MMDeepResearch-Bench: A Benchmark for Multimodal Deep Research Agents
Jan 18, 2026Deep Research Agents (DRAs) generate citation-rich reports via multi-step search and synthesis, yet existing benchmarks mainly target text-only settings or short-form multimodal QA, missing end-to-end multimodal evidence use. We introduce MMDeepResearch-Bench (MMDR-Bench), a benchmark of 140 expert-crafted tasks across 21 domains, where each task provides an image-text bundle to evaluate multimodal understanding and citation-grounded report generation. Compared to prior setups, MMDR-Bench emphasizes report-style synthesis with explicit evidence use, where models must connect visual artifacts to sourced claims and maintain consistency across narrative, citations, and visual references. We further propose a unified, interpretable evaluation pipeline: Formula-LLM Adaptive Evaluation (FLAE) for report quality, Trustworthy Retrieval-Aligned Citation Evaluation (TRACE) for citation-grounded evidence alignment, and Multimodal Support-Aligned Integrity Check (MOSAIC) for text-visual integrity, each producing fine-grained signals that support error diagnosis beyond a single overall score. Experiments across 25 state-of-the-art models reveal systematic trade-offs between generation quality, citation discipline, and multimodal grounding, highlighting that strong prose alone does not guarantee faithful evidence use and that multimodal integrity remains a key bottleneck for deep research agents.
IdentityStory: Taming Your Identity-Preserving Generator for Human-Centric Story Generation
Dec 29, 2025Recent visual generative models enable story generation with consistent characters from text, but human-centric story generation faces additional challenges, such as maintaining detailed and diverse human face consistency and coordinating multiple characters across different images. This paper presents IdentityStory, a framework for human-centric story generation that ensures consistent character identity across multiple sequential images. By taming identity-preserving generators, the framework features two key components: Iterative Identity Discovery, which extracts cohesive character identities, and Re-denoising Identity Injection, which re-denoises images to inject identities while preserving desired context. Experiments on the ConsiStory-Human benchmark demonstrate that IdentityStory outperforms existing methods, particularly in face consistency, and supports multi-character combinations. The framework also shows strong potential for applications such as infinite-length story generation and dynamic character composition.
StereoPilot: Learning Unified and Efficient Stereo Conversion via Generative Priors
Dec 18, 2025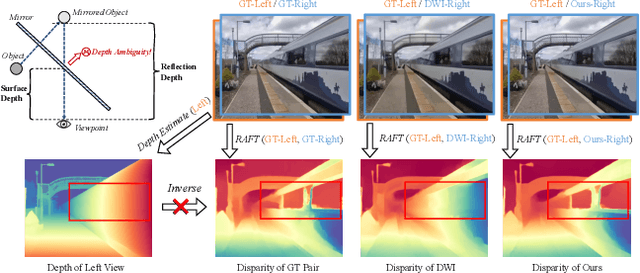

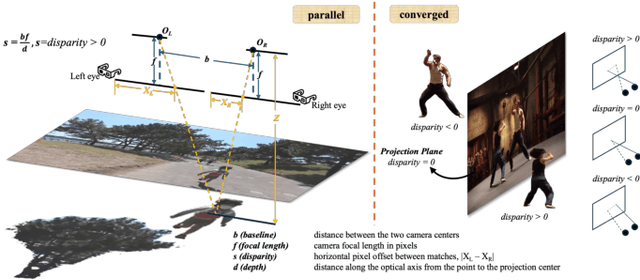

The rapid growth of stereoscopic displays, including VR headsets and 3D cinemas, has led to increasing demand for high-quality stereo video content. However, producing 3D videos remains costly and complex, while automatic Monocular-to-Stereo conversion is hindered by the limitations of the multi-stage ``Depth-Warp-Inpaint'' (DWI) pipeline. This paradigm suffers from error propagation, depth ambiguity, and format inconsistency between parallel and converged stereo configurations. To address these challenges, we introduce UniStereo, the first large-scale unified dataset for stereo video conversion, covering both stereo formats to enable fair benchmarking and robust model training. Building upon this dataset, we propose StereoPilot, an efficient feed-forward model that directly synthesizes the target view without relying on explicit depth maps or iterative diffusion sampling. Equipped with a learnable domain switcher and a cycle consistency loss, StereoPilot adapts seamlessly to different stereo formats and achieves improved consistency. Extensive experiments demonstrate that StereoPilot significantly outperforms state-of-the-art methods in both visual fidelity and computational efficiency. Project page: https://hit-perfect.github.io/StereoPilot/.
SceneDecorator: Towards Scene-Oriented Story Generation with Scene Planning and Scene Consistency
Oct 27, 2025Recent text-to-image models have revolutionized image generation, but they still struggle with maintaining concept consistency across generated images. While existing works focus on character consistency, they often overlook the crucial role of scenes in storytelling, which restricts their creativity in practice. This paper introduces scene-oriented story generation, addressing two key challenges: (i) scene planning, where current methods fail to ensure scene-level narrative coherence by relying solely on text descriptions, and (ii) scene consistency, which remains largely unexplored in terms of maintaining scene consistency across multiple stories. We propose SceneDecorator, a training-free framework that employs VLM-Guided Scene Planning to ensure narrative coherence across different scenes in a ``global-to-local'' manner, and Long-Term Scene-Sharing Attention to maintain long-term scene consistency and subject diversity across generated stories. Extensive experiments demonstrate the superior performance of SceneDecorator, highlighting its potential to unleash creativity in the fields of arts, films, and games.
DisCo-Layout: Disentangling and Coordinating Semantic and Physical Refinement in a Multi-Agent Framework for 3D Indoor Layout Synthesis
Oct 02, 2025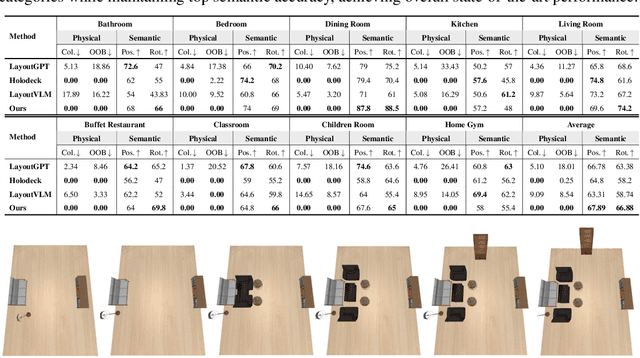
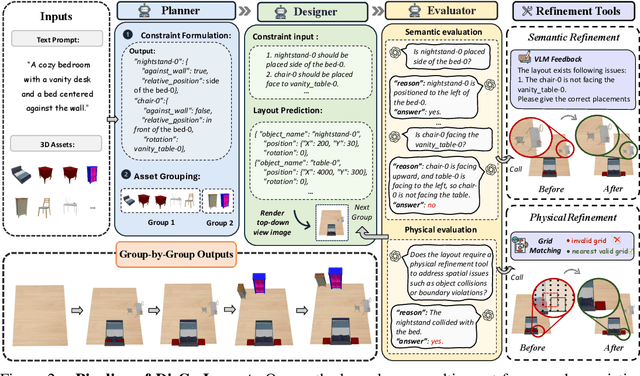
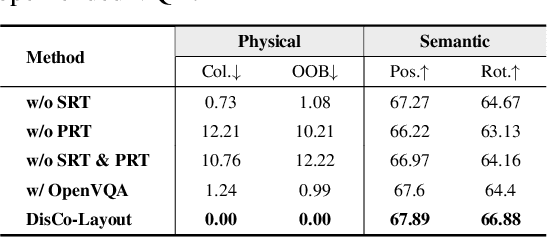
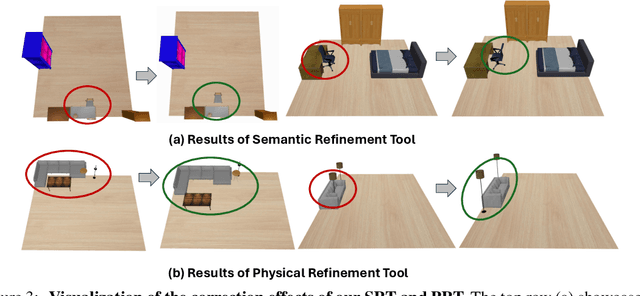
3D indoor layout synthesis is crucial for creating virtual environments. Traditional methods struggle with generalization due to fixed datasets. While recent LLM and VLM-based approaches offer improved semantic richness, they often lack robust and flexible refinement, resulting in suboptimal layouts. We develop DisCo-Layout, a novel framework that disentangles and coordinates physical and semantic refinement. For independent refinement, our Semantic Refinement Tool (SRT) corrects abstract object relationships, while the Physical Refinement Tool (PRT) resolves concrete spatial issues via a grid-matching algorithm. For collaborative refinement, a multi-agent framework intelligently orchestrates these tools, featuring a planner for placement rules, a designer for initial layouts, and an evaluator for assessment. Experiments demonstrate DisCo-Layout's state-of-the-art performance, generating realistic, coherent, and generalizable 3D indoor layouts. Our code will be publicly available.
HERO: Hierarchical Extrapolation and Refresh for Efficient World Models
Aug 25, 2025
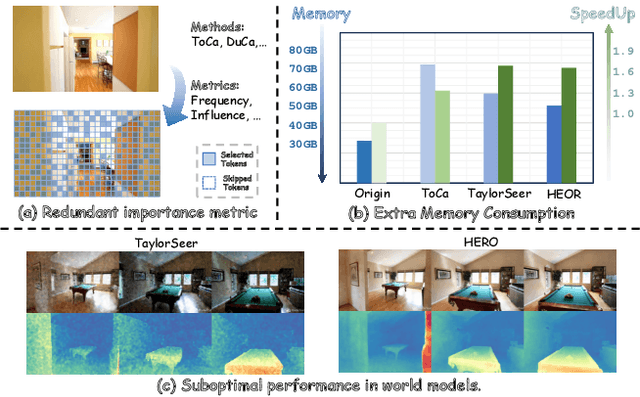
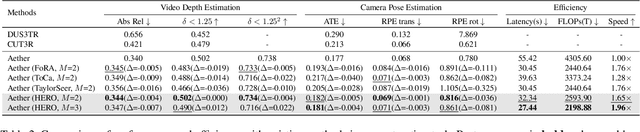

Generation-driven world models create immersive virtual environments but suffer slow inference due to the iterative nature of diffusion models. While recent advances have improved diffusion model efficiency, directly applying these techniques to world models introduces limitations such as quality degradation. In this paper, we present HERO, a training-free hierarchical acceleration framework tailored for efficient world models. Owing to the multi-modal nature of world models, we identify a feature coupling phenomenon, wherein shallow layers exhibit high temporal variability, while deeper layers yield more stable feature representations. Motivated by this, HERO adopts hierarchical strategies to accelerate inference: (i) In shallow layers, a patch-wise refresh mechanism efficiently selects tokens for recomputation. With patch-wise sampling and frequency-aware tracking, it avoids extra metric computation and remain compatible with FlashAttention. (ii) In deeper layers, a linear extrapolation scheme directly estimates intermediate features. This completely bypasses the computations in attention modules and feed-forward networks. Our experiments show that HERO achieves a 1.73$\times$ speedup with minimal quality degradation, significantly outperforming existing diffusion acceleration methods.