 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMoEGCL: Mixture of Ego-Graphs Contrastive Representation Learning for Multi-View Clustering
Nov 08, 2025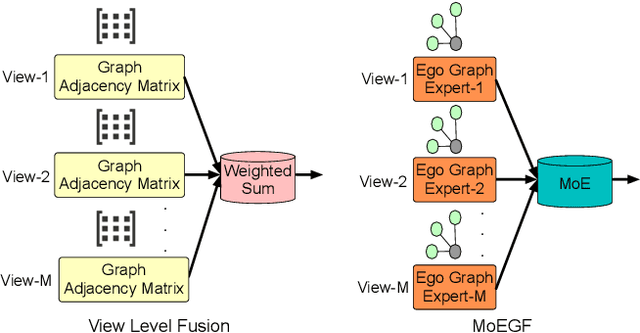
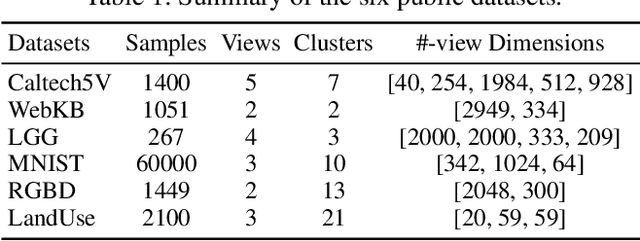
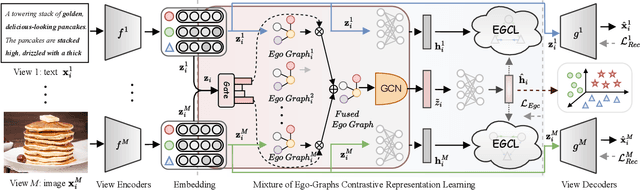
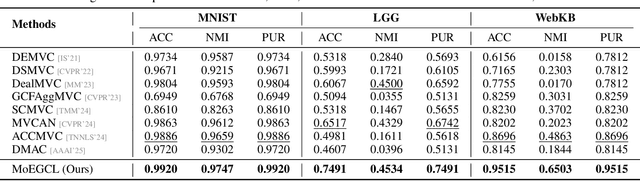
In recent years, the advancement of Graph Neural Networks (GNNs) has significantly propelled progress in Multi-View Clustering (MVC). However, existing methods face the problem of coarse-grained graph fusion. Specifically, current approaches typically generate a separate graph structure for each view and then perform weighted fusion of graph structures at the view level, which is a relatively rough strategy. To address this limitation, we present a novel Mixture of Ego-Graphs Contrastive Representation Learning (MoEGCL). It mainly consists of two modules. In particular, we propose an innovative Mixture of Ego-Graphs Fusion (MoEGF), which constructs ego graphs and utilizes a Mixture-of-Experts network to implement fine-grained fusion of ego graphs at the sample level, rather than the conventional view-level fusion. Additionally, we present the Ego Graph Contrastive Learning (EGCL) module to align the fused representation with the view-specific representation. The EGCL module enhances the representation similarity of samples from the same cluster, not merely from the same sample, further boosting fine-grained graph representation. Extensive experiments demonstrate that MoEGCL achieves state-of-the-art results in deep multi-view clustering tasks. The source code is publicly available at https://github.com/HackerHyper/MoEGCL.
Generative Diffusion Contrastive Network for Multi-View Clustering
Sep 11, 2025In recent years, Multi-View Clustering (MVC) has been significantly advanced under the influence of deep learning. By integrating heterogeneous data from multiple views, MVC enhances clustering analysis, making multi-view fusion critical to clustering performance. However, there is a problem of low-quality data in multi-view fusion. This problem primarily arises from two reasons: 1) Certain views are contaminated by noisy data. 2) Some views suffer from missing data. This paper proposes a novel Stochastic Generative Diffusion Fusion (SGDF) method to address this problem. SGDF leverages a multiple generative mechanism for the multi-view feature of each sample. It is robust to low-quality data. Building on SGDF, we further present the Generative Diffusion Contrastive Network (GDCN). Extensive experiments show that GDCN achieves the state-of-the-art results in deep MVC tasks. The source code is publicly available at https://github.com/HackerHyper/GDCN.
SignVTCL: Multi-Modal Continuous Sign Language Recognition Enhanced by Visual-Textual Contrastive Learning
Jan 22, 2024Sign language recognition (SLR) plays a vital role in facilitating communication for the hearing-impaired community. SLR is a weakly supervised task where entire videos are annotated with glosses, making it challenging to identify the corresponding gloss within a video segment. Recent studies indicate that the main bottleneck in SLR is the insufficient training caused by the limited availability of large-scale datasets. To address this challenge, we present SignVTCL, a multi-modal continuous sign language recognition framework enhanced by visual-textual contrastive learning, which leverages the full potential of multi-modal data and the generalization ability of language model. SignVTCL integrates multi-modal data (video, keypoints, and optical flow) simultaneously to train a unified visual backbone, thereby yielding more robust visual representations. Furthermore, SignVTCL contains a visual-textual alignment approach incorporating gloss-level and sentence-level alignment to ensure precise correspondence between visual features and glosses at the level of individual glosses and sentence. Experimental results conducted on three datasets, Phoenix-2014, Phoenix-2014T, and CSL-Daily, demonstrate that SignVTCL achieves state-of-the-art results compared with previous methods.
DPPMask: Masked Image Modeling with Determinantal Point Processes
Mar 25, 2023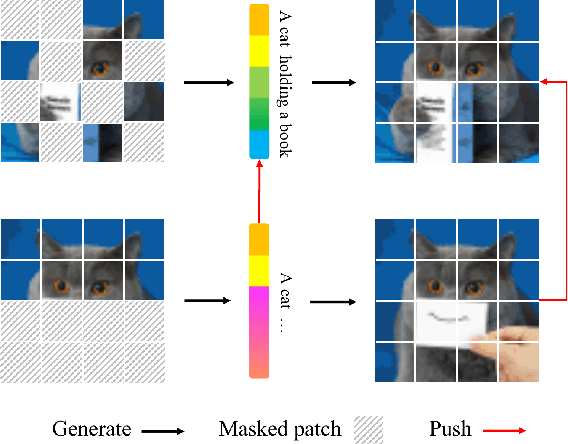
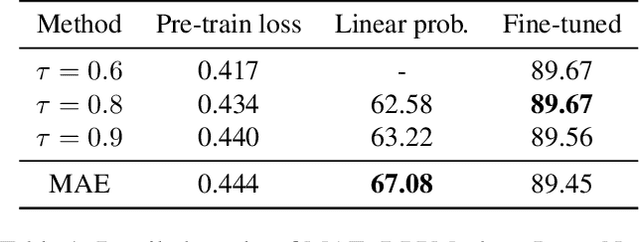
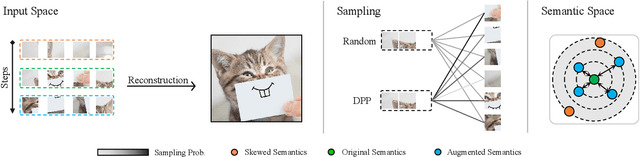
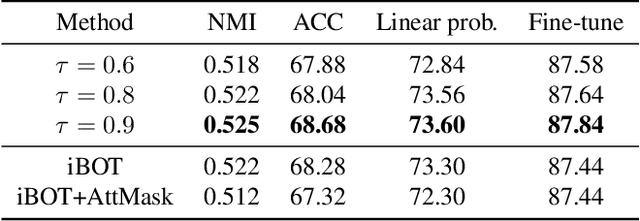
Masked Image Modeling (MIM) has achieved impressive representative performance with the aim of reconstructing randomly masked images. Despite the empirical success, most previous works have neglected the important fact that it is unreasonable to force the model to reconstruct something beyond recovery, such as those masked objects. In this work, we show that uniformly random masking widely used in previous works unavoidably loses some key objects and changes original semantic information, resulting in a misalignment problem and hurting the representative learning eventually. To address this issue, we augment MIM with a new masking strategy namely the DPPMask by substituting the random process with Determinantal Point Process (DPPs) to reduce the semantic change of the image after masking. Our method is simple yet effective and requires no extra learnable parameters when implemented within various frameworks. In particular, we evaluate our method on two representative MIM frameworks, MAE and iBOT. We show that DPPMask surpassed random sampling under both lower and higher masking ratios, indicating that DPPMask makes the reconstruction task more reasonable. We further test our method on the background challenge and multi-class classification tasks, showing that our method is more robust at various tasks.