 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMME-CoF-Pro: Evaluating Reasoning Coherence in Video Generative Models with Text and Visual Hints
Mar 20, 2026Video generative models show emerging reasoning behaviors. It is essential to ensure that generated events remain causally consistent across frames for reliable deployment, a property we define as reasoning coherence. To bridge the gap in literature for missing reasoning coherence evaluation, we propose MME-CoF-Pro, a comprehensive video reasoning benchmark to assess reasoning coherence in video models. Specifically, MME-CoF-Pro contains 303 samples across 16 categories, ranging from visual logical to scientific reasoning. It introduces Reasoning Score as evaluation metric for assessing process-level necessary intermediate reasoning steps, and includes three evaluation settings, (a) no hint (b) text hint and (c) visual hint, enabling a controlled investigation into the underlying mechanisms of reasoning hint guidance. Evaluation results in 7 open and closed-source video models reveals insights including: (1) Video generative models exhibit weak reasoning coherence, decoupled from generation quality. (2) Text hints boost apparent correctness but often cause inconsistency and hallucinated reasoning (3) Visual hints benefit structured perceptual tasks but struggle with fine-grained perception. Website: https://video-reasoning-coherence.github.io/
GENIUS: Generative Fluid Intelligence Evaluation Suite
Feb 11, 2026Unified Multimodal Models (UMMs) have shown remarkable progress in visual generation. Yet, existing benchmarks predominantly assess $\textit{Crystallized Intelligence}$, which relies on recalling accumulated knowledge and learned schemas. This focus overlooks $\textit{Generative Fluid Intelligence (GFI)}$: the capacity to induce patterns, reason through constraints, and adapt to novel scenarios on the fly. To rigorously assess this capability, we introduce $\textbf{GENIUS}$ ($\textbf{GEN}$ Fluid $\textbf{I}$ntelligence Eval$\textbf{U}$ation $\textbf{S}$uite). We formalize $\textit{GFI}$ as a synthesis of three primitives. These include $\textit{Inducing Implicit Patterns}$ (e.g., inferring personalized visual preferences), $\textit{Executing Ad-hoc Constraints}$ (e.g., visualizing abstract metaphors), and $\textit{Adapting to Contextual Knowledge}$ (e.g., simulating counter-intuitive physics). Collectively, these primitives challenge models to solve problems grounded entirely in the immediate context. Our systematic evaluation of 12 representative models reveals significant performance deficits in these tasks. Crucially, our diagnostic analysis disentangles these failure modes. It demonstrates that deficits stem from limited context comprehension rather than insufficient intrinsic generative capability. To bridge this gap, we propose a training-free attention intervention strategy. Ultimately, $\textbf{GENIUS}$ establishes a rigorous standard for $\textit{GFI}$, guiding the field beyond knowledge utilization toward dynamic, general-purpose reasoning. Our dataset and code will be released at: $\href{https://github.com/arctanxarc/GENIUS}{https://github.com/arctanxarc/GENIUS}$.
Are Video Models Ready as Zero-Shot Reasoners? An Empirical Study with the MME-CoF Benchmark
Oct 30, 2025Recent video generation models can produce high-fidelity, temporally coherent videos, indicating that they may encode substantial world knowledge. Beyond realistic synthesis, they also exhibit emerging behaviors indicative of visual perception, modeling, and manipulation. Yet, an important question still remains: Are video models ready to serve as zero-shot reasoners in challenging visual reasoning scenarios? In this work, we conduct an empirical study to comprehensively investigate this question, focusing on the leading and popular Veo-3. We evaluate its reasoning behavior across 12 dimensions, including spatial, geometric, physical, temporal, and embodied logic, systematically characterizing both its strengths and failure modes. To standardize this study, we curate the evaluation data into MME-CoF, a compact benchmark that enables in-depth and thorough assessment of Chain-of-Frame (CoF) reasoning. Our findings reveal that while current video models demonstrate promising reasoning patterns on short-horizon spatial coherence, fine-grained grounding, and locally consistent dynamics, they remain limited in long-horizon causal reasoning, strict geometric constraints, and abstract logic. Overall, they are not yet reliable as standalone zero-shot reasoners, but exhibit encouraging signs as complementary visual engines alongside dedicated reasoning models. Project page: https://video-cof.github.io
Quantization Meets dLLMs: A Systematic Study of Post-training Quantization for Diffusion LLMs
Aug 20, 2025Recent advances in diffusion large language models (dLLMs) have introduced a promising alternative to autoregressive (AR) LLMs for natural language generation tasks, leveraging full attention and denoising-based decoding strategies. However, the deployment of these models on edge devices remains challenging due to their massive parameter scale and high resource demands. While post-training quantization (PTQ) has emerged as a widely adopted technique for compressing AR LLMs, its applicability to dLLMs remains largely unexplored. In this work, we present the first systematic study on quantizing diffusion-based language models. We begin by identifying the presence of activation outliers, characterized by abnormally large activation values that dominate the dynamic range. These outliers pose a key challenge to low-bit quantization, as they make it difficult to preserve precision for the majority of values. More importantly, we implement state-of-the-art PTQ methods and conduct a comprehensive evaluation across multiple task types and model variants. Our analysis is structured along four key dimensions: bit-width, quantization method, task category, and model type. Through this multi-perspective evaluation, we offer practical insights into the quantization behavior of dLLMs under different configurations. We hope our findings provide a foundation for future research in efficient dLLM deployment. All codes and experimental setups will be released to support the community.
Perceive Anything: Recognize, Explain, Caption, and Segment Anything in Images and Videos
Jun 05, 2025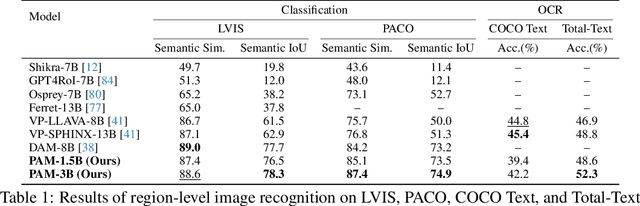
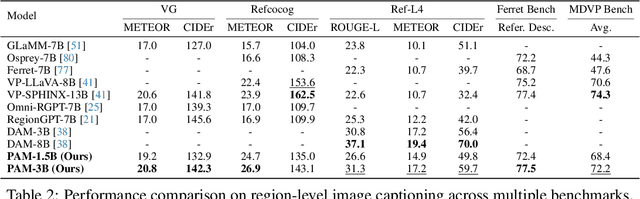
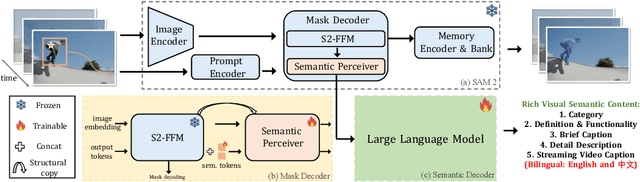
We present Perceive Anything Model (PAM), a conceptually straightforward and efficient framework for comprehensive region-level visual understanding in images and videos. Our approach extends the powerful segmentation model SAM 2 by integrating Large Language Models (LLMs), enabling simultaneous object segmentation with the generation of diverse, region-specific semantic outputs, including categories, label definition, functional explanations, and detailed captions. A key component, Semantic Perceiver, is introduced to efficiently transform SAM 2's rich visual features, which inherently carry general vision, localization, and semantic priors into multi-modal tokens for LLM comprehension. To support robust multi-granularity understanding, we also develop a dedicated data refinement and augmentation pipeline, yielding a high-quality dataset of 1.5M image and 0.6M video region-semantic annotations, including novel region-level streaming video caption data. PAM is designed for lightweightness and efficiency, while also demonstrates strong performance across a diverse range of region understanding tasks. It runs 1.2-2.4x faster and consumes less GPU memory than prior approaches, offering a practical solution for real-world applications. We believe that our effective approach will serve as a strong baseline for future research in region-level visual understanding.
Adaptive Classifier-Free Guidance via Dynamic Low-Confidence Masking
May 26, 2025Classifier-Free Guidance (CFG) significantly enhances controllability in generative models by interpolating conditional and unconditional predictions. However, standard CFG often employs a static unconditional input, which can be suboptimal for iterative generation processes where model uncertainty varies dynamically. We introduce Adaptive Classifier-Free Guidance (A-CFG), a novel method that tailors the unconditional input by leveraging the model's instantaneous predictive confidence. At each step of an iterative (masked) diffusion language model, A-CFG identifies tokens in the currently generated sequence for which the model exhibits low confidence. These tokens are temporarily re-masked to create a dynamic, localized unconditional input. This focuses CFG's corrective influence precisely on areas of ambiguity, leading to more effective guidance. We integrate A-CFG into a state-of-the-art masked diffusion language model and demonstrate its efficacy. Experiments on diverse language generation benchmarks show that A-CFG yields substantial improvements over standard CFG, achieving, for instance, a 3.9 point gain on GPQA. Our work highlights the benefit of dynamically adapting guidance mechanisms to model uncertainty in iterative generation.
CrossLMM: Decoupling Long Video Sequences from LMMs via Dual Cross-Attention Mechanisms
May 22, 2025The advent of Large Multimodal Models (LMMs) has significantly enhanced Large Language Models (LLMs) to process and interpret diverse data modalities (e.g., image and video). However, as input complexity increases, particularly with long video sequences, the number of required tokens has grown significantly, leading to quadratically computational costs. This has made the efficient compression of video tokens in LMMs, while maintaining performance integrity, a pressing research challenge. In this paper, we introduce CrossLMM, decoupling long video sequences from LMMs via a dual cross-attention mechanism, which substantially reduces visual token quantity with minimal performance degradation. Specifically, we first implement a significant token reduction from pretrained visual encoders through a pooling methodology. Then, within LLM layers, we employ a visual-to-visual cross-attention mechanism, wherein the pooled visual tokens function as queries against the original visual token set. This module enables more efficient token utilization while retaining fine-grained informational fidelity. In addition, we introduce a text-to-visual cross-attention mechanism, for which the text tokens are enhanced through interaction with the original visual tokens, enriching the visual comprehension of the text tokens. Comprehensive empirical evaluation demonstrates that our approach achieves comparable or superior performance across diverse video-based LMM benchmarks, despite utilizing substantially fewer computational resources.
Delving into RL for Image Generation with CoT: A Study on DPO vs. GRPO
May 22, 2025Recent advancements underscore the significant role of Reinforcement Learning (RL) in enhancing the Chain-of-Thought (CoT) reasoning capabilities of large language models (LLMs). Two prominent RL algorithms, Direct Preference Optimization (DPO) and Group Relative Policy Optimization (GRPO), are central to these developments, showcasing different pros and cons. Autoregressive image generation, also interpretable as a sequential CoT reasoning process, presents unique challenges distinct from LLM-based CoT reasoning. These encompass ensuring text-image consistency, improving image aesthetic quality, and designing sophisticated reward models, rather than relying on simpler rule-based rewards. While recent efforts have extended RL to this domain, these explorations typically lack an in-depth analysis of the domain-specific challenges and the characteristics of different RL strategies. To bridge this gap, we provide the first comprehensive investigation of the GRPO and DPO algorithms in autoregressive image generation, evaluating their in-domain performance and out-of-domain generalization, while scrutinizing the impact of different reward models on their respective capabilities. Our findings reveal that GRPO and DPO exhibit distinct advantages, and crucially, that reward models possessing stronger intrinsic generalization capabilities potentially enhance the generalization potential of the applied RL algorithms. Furthermore, we systematically explore three prevalent scaling strategies to enhance both their in-domain and out-of-domain proficiency, deriving unique insights into efficiently scaling performance for each paradigm. We hope our study paves a new path for inspiring future work on developing more effective RL algorithms to achieve robust CoT reasoning in the realm of autoregressive image generation. Code is released at https://github.com/ZiyuGuo99/Image-Generation-CoT
UniCTokens: Boosting Personalized Understanding and Generation via Unified Concept Tokens
May 20, 2025Personalized models have demonstrated remarkable success in understanding and generating concepts provided by users. However, existing methods use separate concept tokens for understanding and generation, treating these tasks in isolation. This may result in limitations for generating images with complex prompts. For example, given the concept $\langle bo\rangle$, generating "$\langle bo\rangle$ wearing its hat" without additional textual descriptions of its hat. We call this kind of generation personalized knowledge-driven generation. To address the limitation, we present UniCTokens, a novel framework that effectively integrates personalized information into a unified vision language model (VLM) for understanding and generation. UniCTokens trains a set of unified concept tokens to leverage complementary semantics, boosting two personalized tasks. Moreover, we propose a progressive training strategy with three stages: understanding warm-up, bootstrapping generation from understanding, and deepening understanding from generation to enhance mutual benefits between both tasks. To quantitatively evaluate the unified VLM personalization, we present UnifyBench, the first benchmark for assessing concept understanding, concept generation, and knowledge-driven generation. Experimental results on UnifyBench indicate that UniCTokens shows competitive performance compared to leading methods in concept understanding, concept generation, and achieving state-of-the-art results in personalized knowledge-driven generation. Our research demonstrates that enhanced understanding improves generation, and the generation process can yield valuable insights into understanding. Our code and dataset will be released at: \href{https://github.com/arctanxarc/UniCTokens}{https://github.com/arctanxarc/UniCTokens}.
T2I-R1: Reinforcing Image Generation with Collaborative Semantic-level and Token-level CoT
May 01, 2025Recent advancements in large language models have demonstrated how chain-of-thought (CoT) and reinforcement learning (RL) can improve performance. However, applying such reasoning strategies to the visual generation domain remains largely unexplored. In this paper, we present T2I-R1, a novel reasoning-enhanced text-to-image generation model, powered by RL with a bi-level CoT reasoning process. Specifically, we identify two levels of CoT that can be utilized to enhance different stages of generation: (1) the semantic-level CoT for high-level planning of the prompt and (2) the token-level CoT for low-level pixel processing during patch-by-patch generation. To better coordinate these two levels of CoT, we introduce BiCoT-GRPO with an ensemble of generation rewards, which seamlessly optimizes both generation CoTs within the same training step. By applying our reasoning strategies to the baseline model, Janus-Pro, we achieve superior performance with 13% improvement on T2I-CompBench and 19% improvement on the WISE benchmark, even surpassing the state-of-the-art model FLUX.1. Code is available at: https://github.com/CaraJ7/T2I-R1