 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeResearch on World Models Is Not Merely Injecting World Knowledge into Specific Tasks
Feb 02, 2026World models have emerged as a critical frontier in AI research, aiming to enhance large models by infusing them with physical dynamics and world knowledge. The core objective is to enable agents to understand, predict, and interact with complex environments. However, current research landscape remains fragmented, with approaches predominantly focused on injecting world knowledge into isolated tasks, such as visual prediction, 3D estimation, or symbol grounding, rather than establishing a unified definition or framework. While these task-specific integrations yield performance gains, they often lack the systematic coherence required for holistic world understanding. In this paper, we analyze the limitations of such fragmented approaches and propose a unified design specification for world models. We suggest that a robust world model should not be a loose collection of capabilities but a normative framework that integrally incorporates interaction, perception, symbolic reasoning, and spatial representation. This work aims to provide a structured perspective to guide future research toward more general, robust, and principled models of the world.
CoF-T2I: Video Models as Pure Visual Reasoners for Text-to-Image Generation
Jan 15, 2026Recent video generation models have revealed the emergence of Chain-of-Frame (CoF) reasoning, enabling frame-by-frame visual inference. With this capability, video models have been successfully applied to various visual tasks (e.g., maze solving, visual puzzles). However, their potential to enhance text-to-image (T2I) generation remains largely unexplored due to the absence of a clearly defined visual reasoning starting point and interpretable intermediate states in the T2I generation process. To bridge this gap, we propose CoF-T2I, a model that integrates CoF reasoning into T2I generation via progressive visual refinement, where intermediate frames act as explicit reasoning steps and the final frame is taken as output. To establish such an explicit generation process, we curate CoF-Evol-Instruct, a dataset of CoF trajectories that model the generation process from semantics to aesthetics. To further improve quality and avoid motion artifacts, we enable independent encoding operation for each frame. Experiments show that CoF-T2I significantly outperforms the base video model and achieves competitive performance on challenging benchmarks, reaching 0.86 on GenEval and 7.468 on Imagine-Bench. These results indicate the substantial promise of video models for advancing high-quality text-to-image generation.
Scone: Bridging Composition and Distinction in Subject-Driven Image Generation via Unified Understanding-Generation Modeling
Dec 14, 2025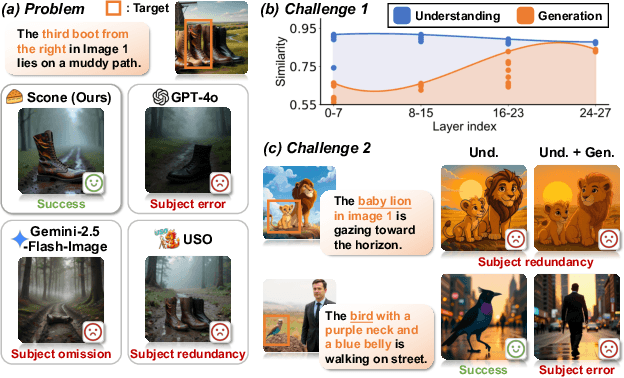

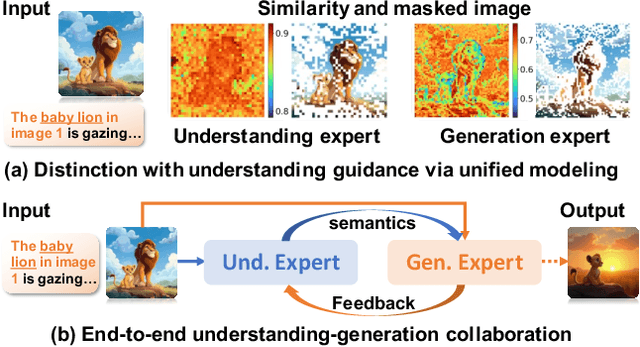
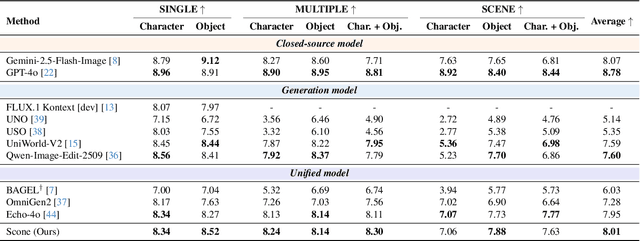
Subject-driven image generation has advanced from single- to multi-subject composition, while neglecting distinction, the ability to identify and generate the correct subject when inputs contain multiple candidates. This limitation restricts effectiveness in complex, realistic visual settings. We propose Scone, a unified understanding-generation method that integrates composition and distinction. Scone enables the understanding expert to act as a semantic bridge, conveying semantic information and guiding the generation expert to preserve subject identity while minimizing interference. A two-stage training scheme first learns composition, then enhances distinction through semantic alignment and attention-based masking. We also introduce SconeEval, a benchmark for evaluating both composition and distinction across diverse scenarios. Experiments demonstrate that Scone outperforms existing open-source models in composition and distinction tasks on two benchmarks. Our model, benchmark, and training data are available at: https://github.com/Ryann-Ran/Scone.
Delving into RL for Image Generation with CoT: A Study on DPO vs. GRPO
May 22, 2025Recent advancements underscore the significant role of Reinforcement Learning (RL) in enhancing the Chain-of-Thought (CoT) reasoning capabilities of large language models (LLMs). Two prominent RL algorithms, Direct Preference Optimization (DPO) and Group Relative Policy Optimization (GRPO), are central to these developments, showcasing different pros and cons. Autoregressive image generation, also interpretable as a sequential CoT reasoning process, presents unique challenges distinct from LLM-based CoT reasoning. These encompass ensuring text-image consistency, improving image aesthetic quality, and designing sophisticated reward models, rather than relying on simpler rule-based rewards. While recent efforts have extended RL to this domain, these explorations typically lack an in-depth analysis of the domain-specific challenges and the characteristics of different RL strategies. To bridge this gap, we provide the first comprehensive investigation of the GRPO and DPO algorithms in autoregressive image generation, evaluating their in-domain performance and out-of-domain generalization, while scrutinizing the impact of different reward models on their respective capabilities. Our findings reveal that GRPO and DPO exhibit distinct advantages, and crucially, that reward models possessing stronger intrinsic generalization capabilities potentially enhance the generalization potential of the applied RL algorithms. Furthermore, we systematically explore three prevalent scaling strategies to enhance both their in-domain and out-of-domain proficiency, deriving unique insights into efficiently scaling performance for each paradigm. We hope our study paves a new path for inspiring future work on developing more effective RL algorithms to achieve robust CoT reasoning in the realm of autoregressive image generation. Code is released at https://github.com/ZiyuGuo99/Image-Generation-CoT
Can We Generate Images with CoT? Let's Verify and Reinforce Image Generation Step by Step
Jan 23, 2025



Chain-of-Thought (CoT) reasoning has been extensively explored in large models to tackle complex understanding tasks. However, it still remains an open question whether such strategies can be applied to verifying and reinforcing image generation scenarios. In this paper, we provide the first comprehensive investigation of the potential of CoT reasoning to enhance autoregressive image generation. We focus on three techniques: scaling test-time computation for verification, aligning model preferences with Direct Preference Optimization (DPO), and integrating these techniques for complementary effects. Our results demonstrate that these approaches can be effectively adapted and combined to significantly improve image generation performance. Furthermore, given the pivotal role of reward models in our findings, we propose the Potential Assessment Reward Model (PARM) and PARM++, specialized for autoregressive image generation. PARM adaptively assesses each generation step through a potential assessment approach, merging the strengths of existing reward models, and PARM++ further introduces a reflection mechanism to self-correct the generated unsatisfactory image. Using our investigated reasoning strategies, we enhance a baseline model, Show-o, to achieve superior results, with a significant +24% improvement on the GenEval benchmark, surpassing Stable Diffusion 3 by +15%. We hope our study provides unique insights and paves a new path for integrating CoT reasoning with autoregressive image generation. Code and models are released at https://github.com/ZiyuGuo99/Image-Generation-CoT
SAM2Point: Segment Any 3D as Videos in Zero-shot and Promptable Manners
Aug 29, 2024



We introduce SAM2Point, a preliminary exploration adapting Segment Anything Model 2 (SAM 2) for zero-shot and promptable 3D segmentation. SAM2Point interprets any 3D data as a series of multi-directional videos, and leverages SAM 2 for 3D-space segmentation, without further training or 2D-3D projection. Our framework supports various prompt types, including 3D points, boxes, and masks, and can generalize across diverse scenarios, such as 3D objects, indoor scenes, outdoor environments, and raw sparse LiDAR. Demonstrations on multiple 3D datasets, e.g., Objaverse, S3DIS, ScanNet, Semantic3D, and KITTI, highlight the robust generalization capabilities of SAM2Point. To our best knowledge, we present the most faithful implementation of SAM in 3D, which may serve as a starting point for future research in promptable 3D segmentation. Online Demo: https://huggingface.co/spaces/ZiyuG/SAM2Point . Code: https://github.com/ZiyuGuo99/SAM2Point .
MAVIS: Mathematical Visual Instruction Tuning
Jul 11, 2024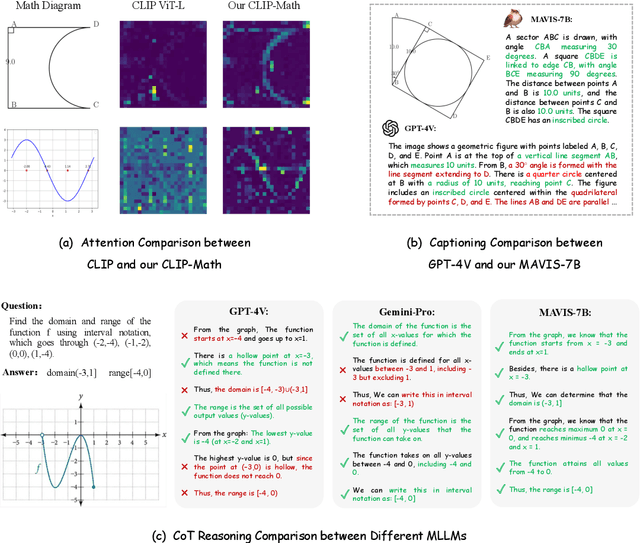
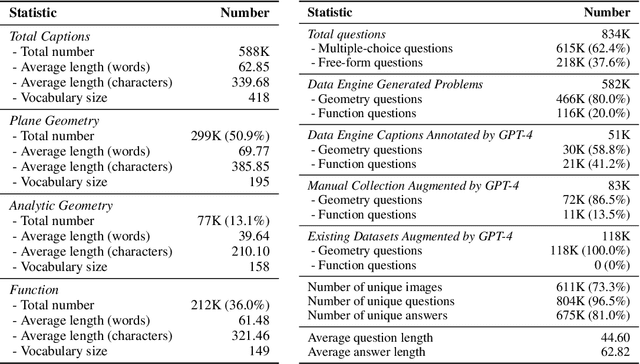
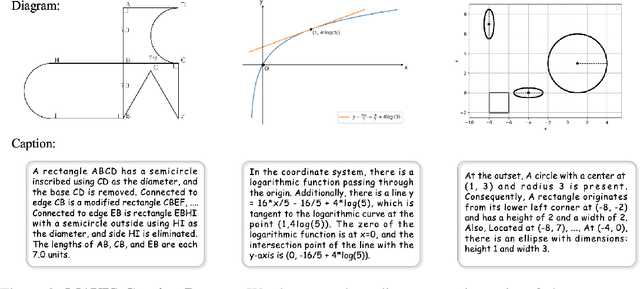

Multi-modal Large Language Models (MLLMs) have recently emerged as a significant focus in academia and industry. Despite their proficiency in general multi-modal scenarios, the mathematical problem-solving capabilities in visual contexts remain insufficiently explored. We identify three key areas within MLLMs that need to be improved: visual encoding of math diagrams, diagram-language alignment, and mathematical reasoning skills. This draws forth an urgent demand for large-scale, high-quality data and training pipelines in visual mathematics. In this paper, we propose MAVIS, the first MAthematical VISual instruction tuning paradigm for MLLMs, involving a series of mathematical visual datasets and specialized MLLMs. Targeting the three issues, MAVIS contains three progressive training stages from scratch. First, we curate MAVIS-Caption, consisting of 558K diagram-caption pairs, to fine-tune a math-specific vision encoder (CLIP-Math) through contrastive learning, tailored for improved diagram visual encoding. Second, we utilize MAVIS-Caption to align the CLIP-Math with a large language model (LLM) by a projection layer, enhancing vision-language alignment in mathematical domains. Third, we introduce MAVIS-Instruct, including 900K meticulously collected and annotated visual math problems, which is adopted to finally instruct-tune the MLLM for robust mathematical reasoning skills. In MAVIS-Instruct, we incorporate complete chain-of-thought (CoT) rationales for each problem, and minimize textual redundancy, thereby concentrating the model towards the visual elements. Data and Models are released at https://github.com/ZrrSkywalker/MAVIS