 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMind-Brush: Integrating Agentic Cognitive Search and Reasoning into Image Generation
Feb 02, 2026While text-to-image generation has achieved unprecedented fidelity, the vast majority of existing models function fundamentally as static text-to-pixel decoders. Consequently, they often fail to grasp implicit user intentions. Although emerging unified understanding-generation models have improved intent comprehension, they still struggle to accomplish tasks involving complex knowledge reasoning within a single model. Moreover, constrained by static internal priors, these models remain unable to adapt to the evolving dynamics of the real world. To bridge these gaps, we introduce Mind-Brush, a unified agentic framework that transforms generation into a dynamic, knowledge-driven workflow. Simulating a human-like 'think-research-create' paradigm, Mind-Brush actively retrieves multimodal evidence to ground out-of-distribution concepts and employs reasoning tools to resolve implicit visual constraints. To rigorously evaluate these capabilities, we propose Mind-Bench, a comprehensive benchmark comprising 500 distinct samples spanning real-time news, emerging concepts, and domains such as mathematical and Geo-Reasoning. Extensive experiments demonstrate that Mind-Brush significantly enhances the capabilities of unified models, realizing a zero-to-one capability leap for the Qwen-Image baseline on Mind-Bench, while achieving superior results on established benchmarks like WISE and RISE.
Are We Ready for RL in Text-to-3D Generation? A Progressive Investigation
Dec 11, 2025Reinforcement learning (RL), earlier proven to be effective in large language and multi-modal models, has been successfully extended to enhance 2D image generation recently. However, applying RL to 3D generation remains largely unexplored due to the higher spatial complexity of 3D objects, which require globally consistent geometry and fine-grained local textures. This makes 3D generation significantly sensitive to reward designs and RL algorithms. To address these challenges, we conduct the first systematic study of RL for text-to-3D autoregressive generation across several dimensions. (1) Reward designs: We evaluate reward dimensions and model choices, showing that alignment with human preference is crucial, and that general multi-modal models provide robust signal for 3D attributes. (2) RL algorithms: We study GRPO variants, highlighting the effectiveness of token-level optimization, and further investigate the scaling of training data and iterations. (3) Text-to-3D Benchmarks: Since existing benchmarks fail to measure implicit reasoning abilities in 3D generation models, we introduce MME-3DR. (4) Advanced RL paradigms: Motivated by the natural hierarchy of 3D generation, we propose Hi-GRPO, which optimizes the global-to-local hierarchical 3D generation through dedicated reward ensembles. Based on these insights, we develop AR3D-R1, the first RL-enhanced text-to-3D model, expert from coarse shape to texture refinement. We hope this study provides insights into RL-driven reasoning for 3D generation. Code is released at https://github.com/Ivan-Tang-3D/3DGen-R1.
Are Video Models Ready as Zero-Shot Reasoners? An Empirical Study with the MME-CoF Benchmark
Oct 30, 2025Recent video generation models can produce high-fidelity, temporally coherent videos, indicating that they may encode substantial world knowledge. Beyond realistic synthesis, they also exhibit emerging behaviors indicative of visual perception, modeling, and manipulation. Yet, an important question still remains: Are video models ready to serve as zero-shot reasoners in challenging visual reasoning scenarios? In this work, we conduct an empirical study to comprehensively investigate this question, focusing on the leading and popular Veo-3. We evaluate its reasoning behavior across 12 dimensions, including spatial, geometric, physical, temporal, and embodied logic, systematically characterizing both its strengths and failure modes. To standardize this study, we curate the evaluation data into MME-CoF, a compact benchmark that enables in-depth and thorough assessment of Chain-of-Frame (CoF) reasoning. Our findings reveal that while current video models demonstrate promising reasoning patterns on short-horizon spatial coherence, fine-grained grounding, and locally consistent dynamics, they remain limited in long-horizon causal reasoning, strict geometric constraints, and abstract logic. Overall, they are not yet reliable as standalone zero-shot reasoners, but exhibit encouraging signs as complementary visual engines alongside dedicated reasoning models. Project page: https://video-cof.github.io
Echo-4o: Harnessing the Power of GPT-4o Synthetic Images for Improved Image Generation
Aug 13, 2025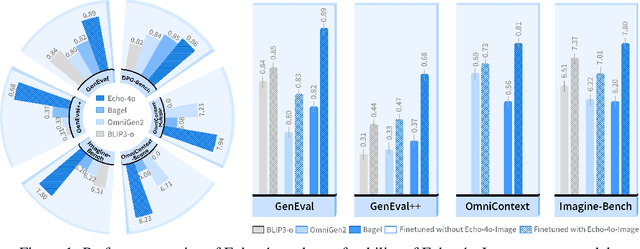
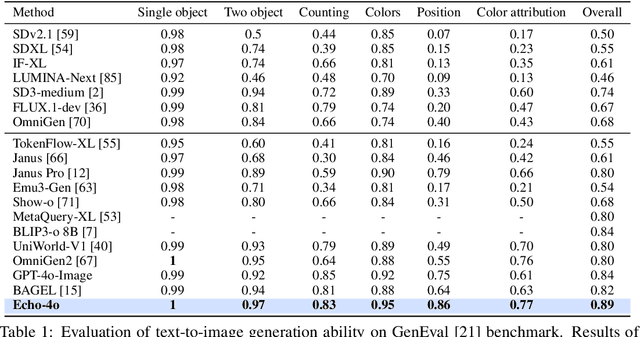
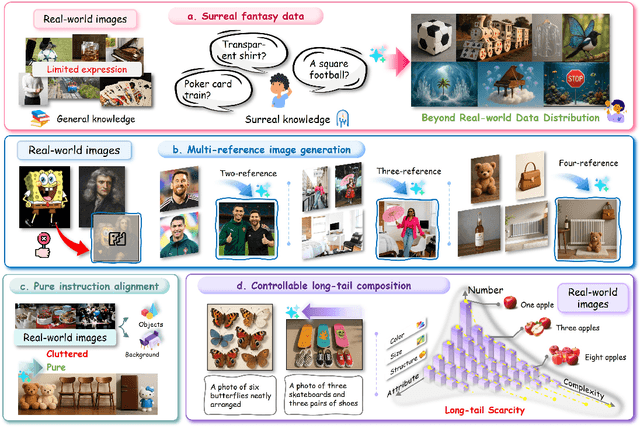
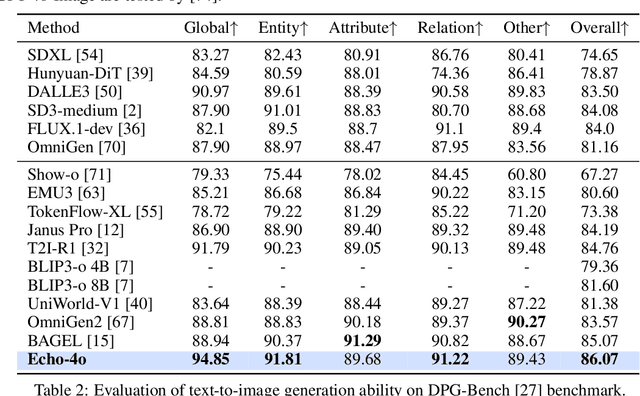
Recently, GPT-4o has garnered significant attention for its strong performance in image generation, yet open-source models still lag behind. Several studies have explored distilling image data from GPT-4o to enhance open-source models, achieving notable progress. However, a key question remains: given that real-world image datasets already constitute a natural source of high-quality data, why should we use GPT-4o-generated synthetic data? In this work, we identify two key advantages of synthetic images. First, they can complement rare scenarios in real-world datasets, such as surreal fantasy or multi-reference image generation, which frequently occur in user queries. Second, they provide clean and controllable supervision. Real-world data often contains complex background noise and inherent misalignment between text descriptions and image content, whereas synthetic images offer pure backgrounds and long-tailed supervision signals, facilitating more accurate text-to-image alignment. Building on these insights, we introduce Echo-4o-Image, a 180K-scale synthetic dataset generated by GPT-4o, harnessing the power of synthetic image data to address blind spots in real-world coverage. Using this dataset, we fine-tune the unified multimodal generation baseline Bagel to obtain Echo-4o. In addition, we propose two new evaluation benchmarks for a more accurate and challenging assessment of image generation capabilities: GenEval++, which increases instruction complexity to mitigate score saturation, and Imagine-Bench, which focuses on evaluating both the understanding and generation of imaginative content. Echo-4o demonstrates strong performance across standard benchmarks. Moreover, applying Echo-4o-Image to other foundation models (e.g., OmniGen2, BLIP3-o) yields consistent performance gains across multiple metrics, highlighting the datasets strong transferability.
MINT-CoT: Enabling Interleaved Visual Tokens in Mathematical Chain-of-Thought Reasoning
Jun 05, 2025Chain-of-Thought (CoT) has widely enhanced mathematical reasoning in Large Language Models (LLMs), but it still remains challenging for extending it to multimodal domains. Existing works either adopt a similar textual reasoning for image input, or seek to interleave visual signals into mathematical CoT. However, they face three key limitations for math problem-solving: reliance on coarse-grained box-shaped image regions, limited perception of vision encoders on math content, and dependence on external capabilities for visual modification. In this paper, we propose MINT-CoT, introducing Mathematical INterleaved Tokens for Chain-of-Thought visual reasoning. MINT-CoT adaptively interleaves relevant visual tokens into textual reasoning steps via an Interleave Token, which dynamically selects visual regions of any shapes within math figures. To empower this capability, we construct the MINT-CoT dataset, containing 54K mathematical problems aligning each reasoning step with visual regions at the token level, accompanied by a rigorous data generation pipeline. We further present a three-stage MINT-CoT training strategy, progressively combining text-only CoT SFT, interleaved CoT SFT, and interleaved CoT RL, which derives our MINT-CoT-7B model. Extensive experiments demonstrate the effectiveness of our method for effective visual interleaved reasoning in mathematical domains, where MINT-CoT-7B outperforms the baseline model by +34.08% on MathVista, +28.78% on GeoQA, and +23.2% on MMStar, respectively. Our code and data are available at https://github.com/xinyan-cxy/MINT-CoT
T2I-R1: Reinforcing Image Generation with Collaborative Semantic-level and Token-level CoT
May 01, 2025Recent advancements in large language models have demonstrated how chain-of-thought (CoT) and reinforcement learning (RL) can improve performance. However, applying such reasoning strategies to the visual generation domain remains largely unexplored. In this paper, we present T2I-R1, a novel reasoning-enhanced text-to-image generation model, powered by RL with a bi-level CoT reasoning process. Specifically, we identify two levels of CoT that can be utilized to enhance different stages of generation: (1) the semantic-level CoT for high-level planning of the prompt and (2) the token-level CoT for low-level pixel processing during patch-by-patch generation. To better coordinate these two levels of CoT, we introduce BiCoT-GRPO with an ensemble of generation rewards, which seamlessly optimizes both generation CoTs within the same training step. By applying our reasoning strategies to the baseline model, Janus-Pro, we achieve superior performance with 13% improvement on T2I-CompBench and 19% improvement on the WISE benchmark, even surpassing the state-of-the-art model FLUX.1. Code is available at: https://github.com/CaraJ7/T2I-R1
ADT: Tuning Diffusion Models with Adversarial Supervision
Apr 15, 2025



Diffusion models have achieved outstanding image generation by reversing a forward noising process to approximate true data distributions. During training, these models predict diffusion scores from noised versions of true samples in a single forward pass, while inference requires iterative denoising starting from white noise. This training-inference divergences hinder the alignment between inference and training data distributions, due to potential prediction biases and cumulative error accumulation. To address this problem, we propose an intuitive but effective fine-tuning framework, called Adversarial Diffusion Tuning (ADT), by stimulating the inference process during optimization and aligning the final outputs with training data by adversarial supervision. Specifically, to achieve robust adversarial training, ADT features a siamese-network discriminator with a fixed pre-trained backbone and lightweight trainable parameters, incorporates an image-to-image sampling strategy to smooth discriminative difficulties, and preserves the original diffusion loss to prevent discriminator hacking. In addition, we carefully constrain the backward-flowing path for back-propagating gradients along the inference path without incurring memory overload or gradient explosion. Finally, extensive experiments on Stable Diffusion models (v1.5, XL, and v3), demonstrate that ADT significantly improves both distribution alignment and image quality.
SciVerse: Unveiling the Knowledge Comprehension and Visual Reasoning of LMMs on Multi-modal Scientific Problems
Mar 13, 2025The rapid advancement of Large Multi-modal Models (LMMs) has enabled their application in scientific problem-solving, yet their fine-grained capabilities remain under-explored. In this paper, we introduce SciVerse, a multi-modal scientific evaluation benchmark to thoroughly assess LMMs across 5,735 test instances in five distinct versions. We aim to investigate three key dimensions of LMMs: scientific knowledge comprehension, multi-modal content interpretation, and Chain-of-Thought (CoT) reasoning. To unveil whether LMMs possess sufficient scientific expertise, we first transform each problem into three versions containing different levels of knowledge required for solving, i.e., Knowledge-free, -lite, and -rich. Then, to explore how LMMs interpret multi-modal scientific content, we annotate another two versions, i.e., Vision-rich and -only, marking more question information from texts to diagrams. Comparing the results of different versions, SciVerse systematically examines the professional knowledge stock and visual perception skills of LMMs in scientific domains. In addition, to rigorously assess CoT reasoning, we propose a new scientific CoT evaluation strategy, conducting a step-wise assessment on knowledge and logical errors in model outputs. Our extensive evaluation of different LMMs on SciVerse reveals critical limitations in their scientific proficiency and provides new insights into future developments. Project page: https://sciverse-cuhk.github.io
PiSA: A Self-Augmented Data Engine and Training Strategy for 3D Understanding with Large Models
Mar 13, 2025



3D Multimodal Large Language Models (MLLMs) have recently made substantial advancements. However, their potential remains untapped, primarily due to the limited quantity and suboptimal quality of 3D datasets. Current approaches attempt to transfer knowledge from 2D MLLMs to expand 3D instruction data, but still face modality and domain gaps. To this end, we introduce PiSA-Engine (Point-Self-Augmented-Engine), a new framework for generating instruction point-language datasets enriched with 3D spatial semantics. We observe that existing 3D MLLMs offer a comprehensive understanding of point clouds for annotation, while 2D MLLMs excel at cross-validation by providing complementary information. By integrating holistic 2D and 3D insights from off-the-shelf MLLMs, PiSA-Engine enables a continuous cycle of high-quality data generation. We select PointLLM as the baseline and adopt this co-evolution training framework to develop an enhanced 3D MLLM, termed PointLLM-PiSA. Additionally, we identify limitations in previous 3D benchmarks, which often feature coarse language captions and insufficient category diversity, resulting in inaccurate evaluations. To address this gap, we further introduce PiSA-Bench, a comprehensive 3D benchmark covering six key aspects with detailed and diverse labels. Experimental results demonstrate PointLLM-PiSA's state-of-the-art performance in zero-shot 3D object captioning and generative classification on our PiSA-Bench, achieving significant improvements of 46.45% (+8.33%) and 63.75% (+16.25%), respectively. We will release the code, datasets, and benchmark.
MME-CoT: Benchmarking Chain-of-Thought in Large Multimodal Models for Reasoning Quality, Robustness, and Efficiency
Feb 13, 2025



Answering questions with Chain-of-Thought (CoT) has significantly enhanced the reasoning capabilities of Large Language Models (LLMs), yet its impact on Large Multimodal Models (LMMs) still lacks a systematic assessment and in-depth investigation. In this paper, we introduce MME-CoT, a specialized benchmark evaluating the CoT reasoning performance of LMMs, spanning six domains: math, science, OCR, logic, space-time, and general scenes. As the first comprehensive study in this area, we propose a thorough evaluation suite incorporating three novel metrics that assess the reasoning quality, robustness, and efficiency at a fine-grained level. Leveraging curated high-quality data and a unique evaluation strategy, we conduct an in-depth analysis of state-of-the-art LMMs, uncovering several key insights: 1) Models with reflection mechanism demonstrate a superior CoT quality, with Kimi k1.5 outperforming GPT-4o and demonstrating the highest quality results; 2) CoT prompting often degrades LMM performance on perception-heavy tasks, suggesting a potentially harmful overthinking behavior; and 3) Although the CoT quality is high, LMMs with reflection exhibit significant inefficiency in both normal response and self-correction phases. We hope MME-CoT serves as a foundation for advancing multimodal reasoning in LMMs. Project Page: https://mmecot.github.io/