 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMAVIS: Mathematical Visual Instruction Tuning
Paper and Code
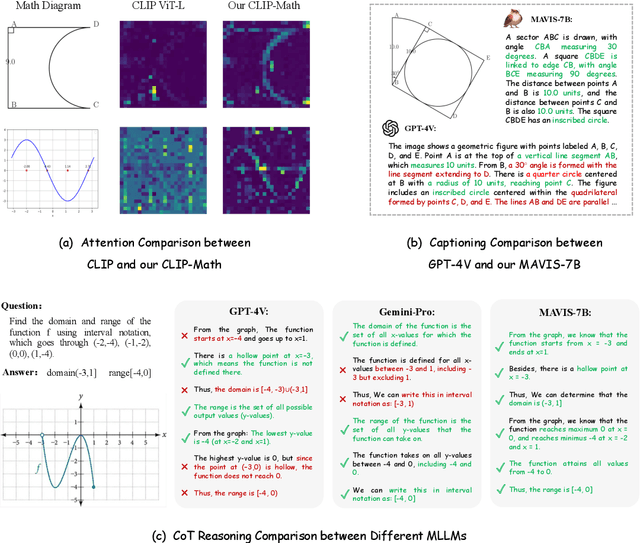
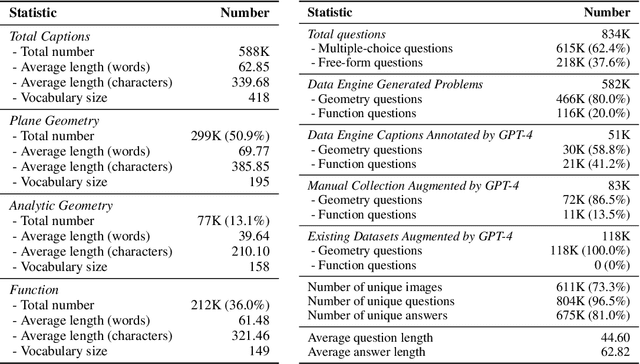
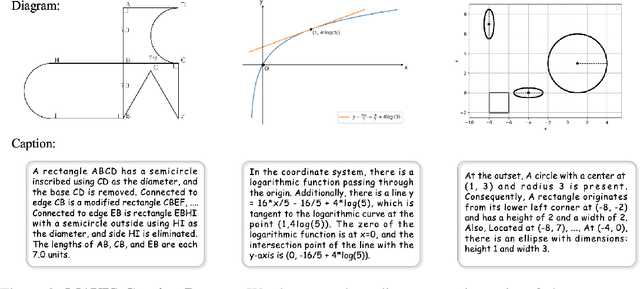

Multi-modal Large Language Models (MLLMs) have recently emerged as a significant focus in academia and industry. Despite their proficiency in general multi-modal scenarios, the mathematical problem-solving capabilities in visual contexts remain insufficiently explored. We identify three key areas within MLLMs that need to be improved: visual encoding of math diagrams, diagram-language alignment, and mathematical reasoning skills. This draws forth an urgent demand for large-scale, high-quality data and training pipelines in visual mathematics. In this paper, we propose MAVIS, the first MAthematical VISual instruction tuning paradigm for MLLMs, involving a series of mathematical visual datasets and specialized MLLMs. Targeting the three issues, MAVIS contains three progressive training stages from scratch. First, we curate MAVIS-Caption, consisting of 558K diagram-caption pairs, to fine-tune a math-specific vision encoder (CLIP-Math) through contrastive learning, tailored for improved diagram visual encoding. Second, we utilize MAVIS-Caption to align the CLIP-Math with a large language model (LLM) by a projection layer, enhancing vision-language alignment in mathematical domains. Third, we introduce MAVIS-Instruct, including 900K meticulously collected and annotated visual math problems, which is adopted to finally instruct-tune the MLLM for robust mathematical reasoning skills. In MAVIS-Instruct, we incorporate complete chain-of-thought (CoT) rationales for each problem, and minimize textual redundancy, thereby concentrating the model towards the visual elements. Data and Models are released at https://github.com/ZrrSkywalker/MAVIS