 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideo as Natural Augmentation: Towards Unified AI-Generated Image and Video Detection
May 21, 2026AI-generated content (AIGC) is rapidly improving, creating an urgent need for detectors that generalize across data sources, deployment pipelines, and visual modalities. A strongly generalizable detector should remain robust under distributional variations. However, we identify a consistent failure mode: SOTA AI-generated image detectors often collapse when applied to frames extracted from videos. Through systematic analysis, we show that this cross-modal gap arises from both entangled synthesis-agnostic video processing shifts, including color conversion, codec compression, resizing, and blur, and model-specific fingerprints introduced by modern video generators. Motivated by these findings, we propose VINA (Video as Natural Augmentation), a unified AIGC detection framework that jointly trains on image and video data. VINA uses video frames as physically grounded natural augmentations and further introduces a cross-modal supervised contrastive objective to align image and video representations under a shared real/fake decision boundary. Extensive experiments on 14 image, video, and in-the-wild benchmarks show that VINA delivers bidirectional gains, improves robustness and transferability, and achieves state-of-the-art performance across nearly all evaluated settings without complex augmentation or dataset-specific tuning.
Preserving Forgery Artifacts: AI-Generated Video Detection at Native Scale
Apr 06, 2026The rapid advancement of video generation models has enabled the creation of highly realistic synthetic media, raising significant societal concerns regarding the spread of misinformation. However, current detection methods suffer from critical limitations. They rely on preprocessing operations like fixed-resolution resizing and cropping. These operations not only discard subtle, high-frequency forgery traces but also cause spatial distortion and significant information loss. Furthermore, existing methods are often trained and evaluated on outdated datasets that fail to capture the sophistication of modern generative models. To address these challenges, we introduce a comprehensive dataset and a novel detection framework. First, we curate a large-scale dataset of over 140K videos from 15 state-of-the-art open-source and commercial generators, along with Magic Videos benchmark designed specifically for evaluating ultra-realistic synthetic content. In addition, we propose a novel detection framework built on the Qwen2.5-VL Vision Transformer, which operates natively at variable spatial resolutions and temporal durations. This native-scale approach effectively preserves the high-frequency artifacts and spatiotemporal inconsistencies typically lost during conventional preprocessing. Extensive experiments demonstrate that our method achieves superior performance across multiple benchmarks, underscoring the critical importance of native-scale processing and establishing a robust new baseline for AI-generated video detection.
Consistency Beyond Contrast: Enhancing Open-Vocabulary Object Detection Robustness via Contextual Consistency Learning
Mar 27, 2026Recent advances in open-vocabulary object detection focus primarily on two aspects: scaling up datasets and leveraging contrastive learning to align language and vision modalities. However, these approaches often neglect internal consistency within a single modality, particularly when background or environmental changes occur. This lack of consistency leads to a performance drop because the model struggles to detect the same object in different scenes, which reveals a robustness gap. To address this issue, we introduce Contextual Consistency Learning (CCL), a novel framework that integrates two key strategies: Contextual Bootstrapped Data Generation (CBDG) and Contextual Consistency Loss (CCLoss). CBDG functions as a data generation mechanism, producing images that contain the same objects across diverse backgrounds. This is essential because existing datasets alone do not support our CCL framework. The CCLoss further enforces the invariance of object features despite environmental changes, thereby improving the model's robustness in different scenes. These strategies collectively form a unified framework for ensuring contextual consistency within the same modality. Our method achieves state-of-the-art performance, surpassing previous approaches by +16.3 AP on OmniLabel and +14.9 AP on D3. These results demonstrate the importance of enforcing intra-modal consistency, significantly enhancing model generalization in diverse environments. Our code is publicly available at: https://github.com/bozhao-li/CCL.
Beyond Static Cropping: Layer-Adaptive Visual Localization and Decoding Enhancement
Feb 04, 2026Large Vision-Language Models (LVLMs) have advanced rapidly by aligning visual patches with the text embedding space, but a fixed visual-token budget forces images to be resized to a uniform pretraining resolution, often erasing fine-grained details and causing hallucinations via over-reliance on language priors. Recent attention-guided enhancement (e.g., cropping or region-focused attention allocation) alleviates this, yet it commonly hinges on a static "magic layer" empirically chosen on simple recognition benchmarks and thus may not transfer to complex reasoning tasks. In contrast to this static assumption, we propose a dynamic perspective on visual grounding. Through a layer-wise sensitivity analysis, we demonstrate that visual grounding is a dynamic process: while simple object recognition tasks rely on middle layers, complex visual search and reasoning tasks require visual information to be reactivated at deeper layers. Based on this observation, we introduce Visual Activation by Query (VAQ), a metric that identifies the layer whose attention map is most relevant to query-specific visual grounding by measuring attention sensitivity to the input query. Building on VAQ, we further propose LASER (Layer-adaptive Attention-guided Selective visual and decoding Enhancement for Reasoning), a training-free inference procedure that adaptively selects task-appropriate layers for visual localization and question answering. Experiments across diverse VQA benchmarks show that LASER significantly improves VQA accuracy across tasks with varying levels of complexity.
HSI-VAR: Rethinking Hyperspectral Restoration through Spatial-Spectral Visual Autoregression
Jan 31, 2026Hyperspectral images (HSIs) capture richer spatial-spectral information beyond RGB, yet real-world HSIs often suffer from a composite mix of degradations, such as noise, blur, and missing bands. Existing generative approaches for HSI restoration like diffusion models require hundreds of iterative steps, making them computationally impractical for high-dimensional HSIs. While regression models tend to produce oversmoothed results, failing to preserve critical structural details. We break this impasse by introducing HSI-VAR, rethinking HSI restoration as an autoregressive generation problem, where spectral and spatial dependencies can be progressively modeled rather than globally reconstructed. HSI-VAR incorporates three key innovations: (1) Latent-condition alignment, which couples semantic consistency between latent priors and conditional embeddings for precise reconstruction; (2) Degradation-aware guidance, which uniquely encodes mixed degradations as linear combinations in the embedding space for automatic control, remarkably achieving a nearly $50\%$ reduction in computational cost at inference; (3) A spatial-spectral adaptation module that refines details across both domains in the decoding phase. Extensive experiments on nine all-in-one HSI restoration benchmarks confirm HSI-VAR's state-of-the-art performance, achieving a 3.77 dB PSNR improvement on \textbf{\textit{ICVL}} and offering superior structure preservation with an inference speed-up of up to $95.5 \times$ compared with diffusion-based methods, making it a highly practical solution for real-world HSI restoration.
Plug-and-Play Fidelity Optimization for Diffusion Transformer Acceleration via Cumulative Error Minimization
Dec 29, 2025Although Diffusion Transformer (DiT) has emerged as a predominant architecture for image and video generation, its iterative denoising process results in slow inference, which hinders broader applicability and development. Caching-based methods achieve training-free acceleration, while suffering from considerable computational error. Existing methods typically incorporate error correction strategies such as pruning or prediction to mitigate it. However, their fixed caching strategy fails to adapt to the complex error variations during denoising, which limits the full potential of error correction. To tackle this challenge, we propose a novel fidelity-optimization plugin for existing error correction methods via cumulative error minimization, named CEM. CEM predefines the error to characterize the sensitivity of model to acceleration jointly influenced by timesteps and cache intervals. Guided by this prior, we formulate a dynamic programming algorithm with cumulative error approximation for strategy optimization, which achieves the caching error minimization, resulting in a substantial improvement in generation fidelity. CEM is model-agnostic and exhibits strong generalization, which is adaptable to arbitrary acceleration budgets. It can be seamlessly integrated into existing error correction frameworks and quantized models without introducing any additional computational overhead. Extensive experiments conducted on nine generation models and quantized methods across three tasks demonstrate that CEM significantly improves generation fidelity of existing acceleration models, and outperforms the original generation performance on FLUX.1-dev, PixArt-$α$, StableDiffusion1.5 and Hunyuan. The code will be made publicly available.
KAN or MLP? Point Cloud Shows the Way Forward
Apr 18, 2025Multi-Layer Perceptrons (MLPs) have become one of the fundamental architectural component in point cloud analysis due to its effective feature learning mechanism. However, when processing complex geometric structures in point clouds, MLPs' fixed activation functions struggle to efficiently capture local geometric features, while suffering from poor parameter efficiency and high model redundancy. In this paper, we propose PointKAN, which applies Kolmogorov-Arnold Networks (KANs) to point cloud analysis tasks to investigate their efficacy in hierarchical feature representation. First, we introduce a Geometric Affine Module (GAM) to transform local features, improving the model's robustness to geometric variations. Next, in the Local Feature Processing (LFP), a parallel structure extracts both group-level features and global context, providing a rich representation of both fine details and overall structure. Finally, these features are combined and processed in the Global Feature Processing (GFP). By repeating these operations, the receptive field gradually expands, enabling the model to capture complete geometric information of the point cloud. To overcome the high parameter counts and computational inefficiency of standard KANs, we develop Efficient-KANs in the PointKAN-elite variant, which significantly reduces parameters while maintaining accuracy. Experimental results demonstrate that PointKAN outperforms PointMLP on benchmark datasets such as ModelNet40, ScanObjectNN, and ShapeNetPart, with particularly strong performance in Few-shot Learning task. Additionally, PointKAN achieves substantial reductions in parameter counts and computational complexity (FLOPs). This work highlights the potential of KANs-based architectures in 3D vision and opens new avenues for research in point cloud understanding.
Binarized Mamba-Transformer for Lightweight Quad Bayer HybridEVS Demosaicing
Mar 20, 2025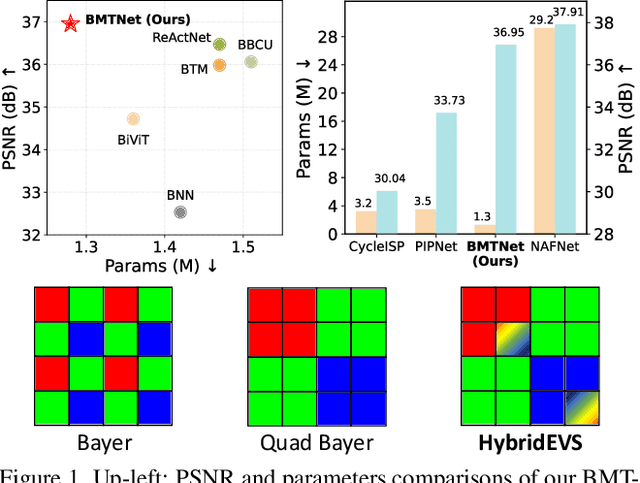
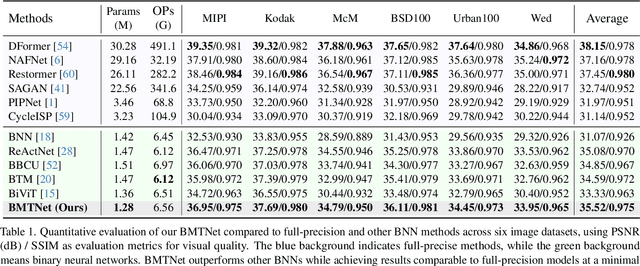
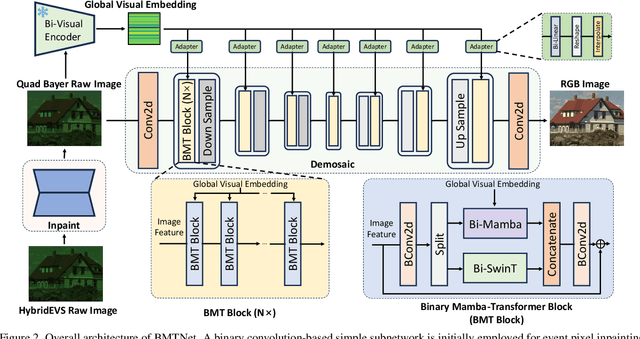
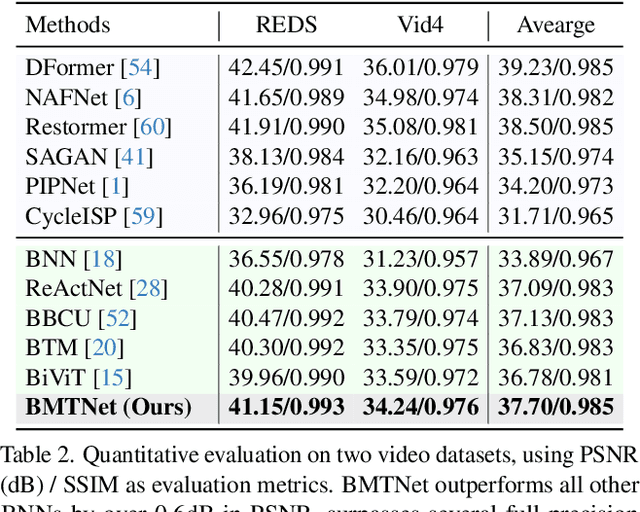
Quad Bayer demosaicing is the central challenge for enabling the widespread application of Hybrid Event-based Vision Sensors (HybridEVS). Although existing learning-based methods that leverage long-range dependency modeling have achieved promising results, their complexity severely limits deployment on mobile devices for real-world applications. To address these limitations, we propose a lightweight Mamba-based binary neural network designed for efficient and high-performing demosaicing of HybridEVS RAW images. First, to effectively capture both global and local dependencies, we introduce a hybrid Binarized Mamba-Transformer architecture that combines the strengths of the Mamba and Swin Transformer architectures. Next, to significantly reduce computational complexity, we propose a binarized Mamba (Bi-Mamba), which binarizes all projections while retaining the core Selective Scan in full precision. Bi-Mamba also incorporates additional global visual information to enhance global context and mitigate precision loss. We conduct quantitative and qualitative experiments to demonstrate the effectiveness of BMTNet in both performance and computational efficiency, providing a lightweight demosaicing solution suited for real-world edge devices. Our codes and models are available at https://github.com/Clausy9/BMTNet.
Typicalness-Aware Learning for Failure Detection
Nov 04, 2024



Deep neural networks (DNNs) often suffer from the overconfidence issue, where incorrect predictions are made with high confidence scores, hindering the applications in critical systems. In this paper, we propose a novel approach called Typicalness-Aware Learning (TAL) to address this issue and improve failure detection performance. We observe that, with the cross-entropy loss, model predictions are optimized to align with the corresponding labels via increasing logit magnitude or refining logit direction. However, regarding atypical samples, the image content and their labels may exhibit disparities. This discrepancy can lead to overfitting on atypical samples, ultimately resulting in the overconfidence issue that we aim to address. To tackle the problem, we have devised a metric that quantifies the typicalness of each sample, enabling the dynamic adjustment of the logit magnitude during the training process. By allowing atypical samples to be adequately fitted while preserving reliable logit direction, the problem of overconfidence can be mitigated. TAL has been extensively evaluated on benchmark datasets, and the results demonstrate its superiority over existing failure detection methods. Specifically, TAL achieves a more than 5% improvement on CIFAR100 in terms of the Area Under the Risk-Coverage Curve (AURC) compared to the state-of-the-art. Code is available at https://github.com/liuyijungoon/TAL.
Skeleton-based Group Activity Recognition via Spatial-Temporal Panoramic Graph
Jul 28, 2024



Group Activity Recognition aims to understand collective activities from videos. Existing solutions primarily rely on the RGB modality, which encounters challenges such as background variations, occlusions, motion blurs, and significant computational overhead. Meanwhile, current keypoint-based methods offer a lightweight and informative representation of human motions but necessitate accurate individual annotations and specialized interaction reasoning modules. To address these limitations, we design a panoramic graph that incorporates multi-person skeletons and objects to encapsulate group activity, offering an effective alternative to RGB video. This panoramic graph enables Graph Convolutional Network (GCN) to unify intra-person, inter-person, and person-object interactive modeling through spatial-temporal graph convolutions. In practice, we develop a novel pipeline that extracts skeleton coordinates using pose estimation and tracking algorithms and employ Multi-person Panoramic GCN (MP-GCN) to predict group activities. Extensive experiments on Volleyball and NBA datasets demonstrate that the MP-GCN achieves state-of-the-art performance in both accuracy and efficiency. Notably, our method outperforms RGB-based approaches by using only estimated 2D keypoints as input. Code is available at https://github.com/mgiant/MP-GCN