 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDreamOmni3: Scribble-based Editing and Generation
Dec 27, 2025Recently unified generation and editing models have achieved remarkable success with their impressive performance. These models rely mainly on text prompts for instruction-based editing and generation, but language often fails to capture users intended edit locations and fine-grained visual details. To this end, we propose two tasks: scribble-based editing and generation, that enables more flexible creation on graphical user interface (GUI) combining user textual, images, and freehand sketches. We introduce DreamOmni3, tackling two challenges: data creation and framework design. Our data synthesis pipeline includes two parts: scribble-based editing and generation. For scribble-based editing, we define four tasks: scribble and instruction-based editing, scribble and multimodal instruction-based editing, image fusion, and doodle editing. Based on DreamOmni2 dataset, we extract editable regions and overlay hand-drawn boxes, circles, doodles or cropped image to construct training data. For scribble-based generation, we define three tasks: scribble and instruction-based generation, scribble and multimodal instruction-based generation, and doodle generation, following similar data creation pipelines. For the framework, instead of using binary masks, which struggle with complex edits involving multiple scribbles, images, and instructions, we propose a joint input scheme that feeds both the original and scribbled source images into the model, using different colors to distinguish regions and simplify processing. By applying the same index and position encodings to both images, the model can precisely localize scribbled regions while maintaining accurate editing. Finally, we establish comprehensive benchmarks for these tasks to promote further research. Experimental results demonstrate that DreamOmni3 achieves outstanding performance, and models and code will be publicly released.
RePlan: Reasoning-guided Region Planning for Complex Instruction-based Image Editing
Dec 18, 2025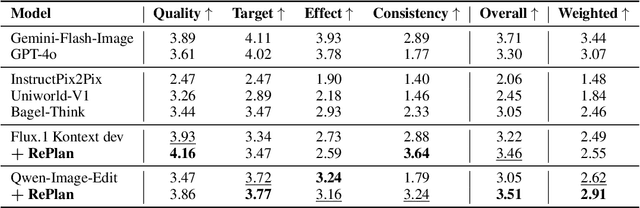
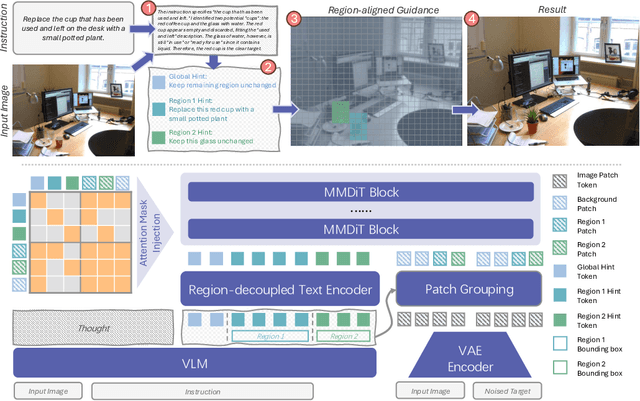

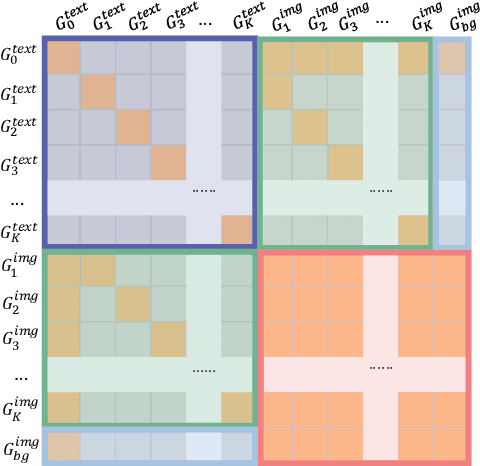
Instruction-based image editing enables natural-language control over visual modifications, yet existing models falter under Instruction-Visual Complexity (IV-Complexity), where intricate instructions meet cluttered or ambiguous scenes. We introduce RePlan (Region-aligned Planning), a plan-then-execute framework that couples a vision-language planner with a diffusion editor. The planner decomposes instructions via step-by-step reasoning and explicitly grounds them to target regions; the editor then applies changes using a training-free attention-region injection mechanism, enabling precise, parallel multi-region edits without iterative inpainting. To strengthen planning, we apply GRPO-based reinforcement learning using 1K instruction-only examples, yielding substantial gains in reasoning fidelity and format reliability. We further present IV-Edit, a benchmark focused on fine-grained grounding and knowledge-intensive edits. Across IV-Complex settings, RePlan consistently outperforms strong baselines trained on far larger datasets, improving regional precision and overall fidelity. Our project page: https://replan-iv-edit.github.io
DreamVE: Unified Instruction-based Image and Video Editing
Aug 08, 2025Instruction-based editing holds vast potential due to its simple and efficient interactive editing format. However, instruction-based editing, particularly for video, has been constrained by limited training data, hindering its practical application. To this end, we introduce DreamVE, a unified model for instruction-based image and video editing. Specifically, We propose a two-stage training strategy: first image editing, then video editing. This offers two main benefits: (1) Image data scales more easily, and models are more efficient to train, providing useful priors for faster and better video editing training. (2) Unifying image and video generation is natural and aligns with current trends. Moreover, we present comprehensive training data synthesis pipelines, including collage-based and generative model-based data synthesis. The collage-based data synthesis combines foreground objects and backgrounds to generate diverse editing data, such as object manipulation, background changes, and text modifications. It can easily generate billions of accurate, consistent, realistic, and diverse editing pairs. We pretrain DreamVE on extensive collage-based data to achieve strong performance in key editing types and enhance generalization and transfer capabilities. However, collage-based data lacks some attribute editing cases, leading to a relative drop in performance. In contrast, the generative model-based pipeline, despite being hard to scale up, offers flexibility in handling attribute editing cases. Therefore, we use generative model-based data to further fine-tune DreamVE. Besides, we design an efficient and powerful editing framework for DreamVE. We build on the SOTA T2V model and use a token concatenation with early drop approach to inject source image guidance, ensuring strong consistency and editability. The codes and models will be released.
Training-Free Efficient Video Generation via Dynamic Token Carving
May 22, 2025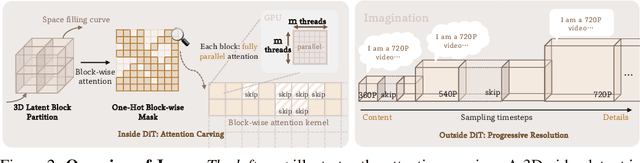
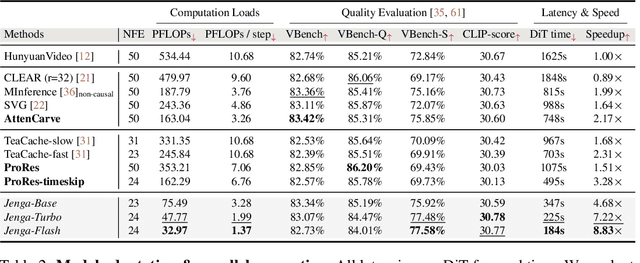
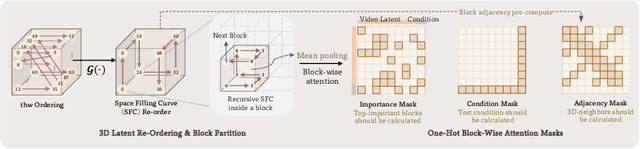
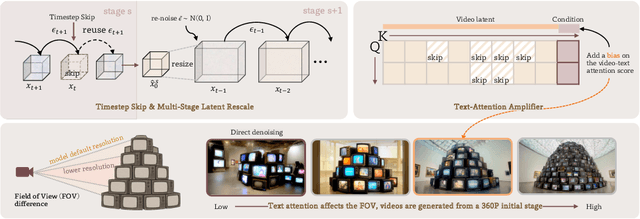
Despite the remarkable generation quality of video Diffusion Transformer (DiT) models, their practical deployment is severely hindered by extensive computational requirements. This inefficiency stems from two key challenges: the quadratic complexity of self-attention with respect to token length and the multi-step nature of diffusion models. To address these limitations, we present Jenga, a novel inference pipeline that combines dynamic attention carving with progressive resolution generation. Our approach leverages two key insights: (1) early denoising steps do not require high-resolution latents, and (2) later steps do not require dense attention. Jenga introduces a block-wise attention mechanism that dynamically selects relevant token interactions using 3D space-filling curves, alongside a progressive resolution strategy that gradually increases latent resolution during generation. Experimental results demonstrate that Jenga achieves substantial speedups across multiple state-of-the-art video diffusion models while maintaining comparable generation quality (8.83$\times$ speedup with 0.01\% performance drop on VBench). As a plug-and-play solution, Jenga enables practical, high-quality video generation on modern hardware by reducing inference time from minutes to seconds -- without requiring model retraining. Code: https://github.com/dvlab-research/Jenga
VisionReasoner: Unified Visual Perception and Reasoning via Reinforcement Learning
May 17, 2025Large vision-language models exhibit inherent capabilities to handle diverse visual perception tasks. In this paper, we introduce VisionReasoner, a unified framework capable of reasoning and solving multiple visual perception tasks within a shared model. Specifically, by designing novel multi-object cognitive learning strategies and systematic task reformulation, VisionReasoner enhances its reasoning capabilities to analyze visual inputs, and addresses diverse perception tasks in a unified framework. The model generates a structured reasoning process before delivering the desired outputs responding to user queries. To rigorously assess unified visual perception capabilities, we evaluate VisionReasoner on ten diverse tasks spanning three critical domains: detection, segmentation, and counting. Experimental results show that VisionReasoner achieves superior performance as a unified model, outperforming Qwen2.5VL by relative margins of 29.1% on COCO (detection), 22.1% on ReasonSeg (segmentation), and 15.3% on CountBench (counting).
Does Your Vision-Language Model Get Lost in the Long Video Sampling Dilemma?
Mar 16, 2025

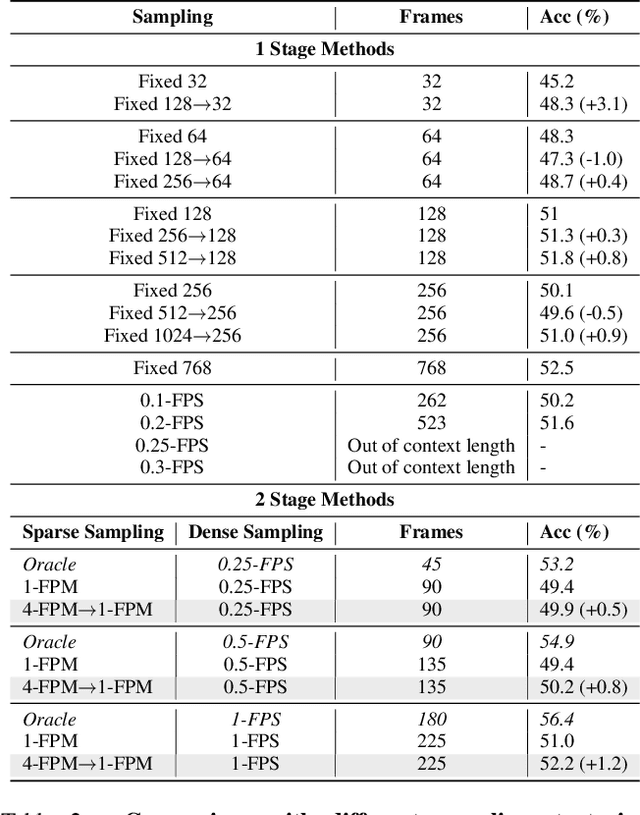

The rise of Large Vision-Language Models (LVLMs) has significantly advanced video understanding. However, efficiently processing long videos remains a challenge due to the ``Sampling Dilemma'': low-density sampling risks missing critical information, while high-density sampling introduces redundancy. To address this issue, we introduce LSDBench, the first benchmark designed to evaluate LVLMs on long-video tasks by constructing high Necessary Sampling Density (NSD) questions, where NSD represents the minimum sampling density required to accurately answer a given question. LSDBench focuses on dense, short-duration actions to rigorously assess the sampling strategies employed by LVLMs. To tackle the challenges posed by high-NSD questions, we propose a novel Reasoning-Driven Hierarchical Sampling (RHS) framework, which combines global localization of question-relevant cues with local dense sampling for precise inference. Additionally, we develop a lightweight Semantic-Guided Frame Selector to prioritize informative frames, enabling RHS to achieve comparable or superior performance with significantly fewer sampled frames. Together, our LSDBench and RHS framework address the unique challenges of high-NSD long-video tasks, setting a new standard for evaluating and improving LVLMs in this domain.
Seg-Zero: Reasoning-Chain Guided Segmentation via Cognitive Reinforcement
Mar 09, 2025Traditional methods for reasoning segmentation rely on supervised fine-tuning with categorical labels and simple descriptions, limiting its out-of-domain generalization and lacking explicit reasoning processes. To address these limitations, we propose Seg-Zero, a novel framework that demonstrates remarkable generalizability and derives explicit chain-of-thought reasoning through cognitive reinforcement. Seg-Zero introduces a decoupled architecture consisting of a reasoning model and a segmentation model. The reasoning model interprets user intentions, generates explicit reasoning chains, and produces positional prompts, which are subsequently used by the segmentation model to generate precious pixel-level masks. We design a sophisticated reward mechanism that integrates both format and accuracy rewards to effectively guide optimization directions. Trained exclusively via reinforcement learning with GRPO and without explicit reasoning data, Seg-Zero achieves robust zero-shot generalization and exhibits emergent test-time reasoning capabilities. Experiments show that Seg-Zero-7B achieves a zero-shot performance of 57.5 on the ReasonSeg benchmark, surpassing the prior LISA-7B by 18\%. This significant improvement highlights Seg-Zero's ability to generalize across domains while presenting an explicit reasoning process. Code is available at https://github.com/dvlab-research/Seg-Zero.
Magic Mirror: ID-Preserved Video Generation in Video Diffusion Transformers
Jan 07, 2025

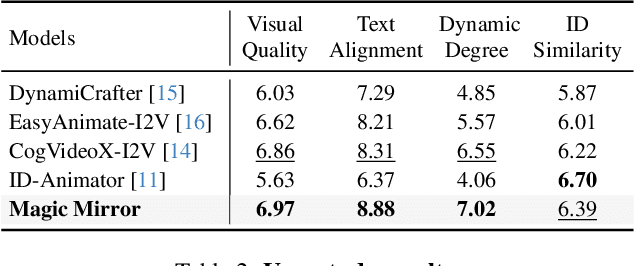
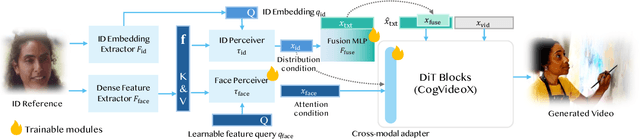
We present Magic Mirror, a framework for generating identity-preserved videos with cinematic-level quality and dynamic motion. While recent advances in video diffusion models have shown impressive capabilities in text-to-video generation, maintaining consistent identity while producing natural motion remains challenging. Previous methods either require person-specific fine-tuning or struggle to balance identity preservation with motion diversity. Built upon Video Diffusion Transformers, our method introduces three key components: (1) a dual-branch facial feature extractor that captures both identity and structural features, (2) a lightweight cross-modal adapter with Conditioned Adaptive Normalization for efficient identity integration, and (3) a two-stage training strategy combining synthetic identity pairs with video data. Extensive experiments demonstrate that Magic Mirror effectively balances identity consistency with natural motion, outperforming existing methods across multiple metrics while requiring minimal parameters added. The code and model will be made publicly available at: https://github.com/dvlab-research/MagicMirror/
ControlNeXt: Powerful and Efficient Control for Image and Video Generation
Aug 15, 2024



Diffusion models have demonstrated remarkable and robust abilities in both image and video generation. To achieve greater control over generated results, researchers introduce additional architectures, such as ControlNet, Adapters and ReferenceNet, to integrate conditioning controls. However, current controllable generation methods often require substantial additional computational resources, especially for video generation, and face challenges in training or exhibit weak control. In this paper, we propose ControlNeXt: a powerful and efficient method for controllable image and video generation. We first design a more straightforward and efficient architecture, replacing heavy additional branches with minimal additional cost compared to the base model. Such a concise structure also allows our method to seamlessly integrate with other LoRA weights, enabling style alteration without the need for additional training. As for training, we reduce up to 90% of learnable parameters compared to the alternatives. Furthermore, we propose another method called Cross Normalization (CN) as a replacement for Zero-Convolution' to achieve fast and stable training convergence. We have conducted various experiments with different base models across images and videos, demonstrating the robustness of our method.
Scalable Language Model with Generalized Continual Learning
Apr 11, 2024



Continual learning has gained increasing importance as it facilitates the acquisition and refinement of scalable knowledge and skills in language models. However, existing methods typically encounter strict limitations and challenges in real-world scenarios, such as reliance on experience replay, optimization constraints, and inference task-ID. In this study, we introduce the Scalable Language Model (SLM) to overcome these limitations within a more challenging and generalized setting, representing a significant advancement toward practical applications for continual learning. Specifically, we propose the Joint Adaptive Re-Parameterization (JARe), integrated with Dynamic Task-related Knowledge Retrieval (DTKR), to enable adaptive adjustment of language models based on specific downstream tasks. This approach leverages the task distribution within the vector space, aiming to achieve a smooth and effortless continual learning process. Our method demonstrates state-of-the-art performance on diverse backbones and benchmarks, achieving effective continual learning in both full-set and few-shot scenarios with minimal forgetting. Moreover, while prior research primarily focused on a single task type such as classification, our study goes beyond, with the large language model, i.e., LLaMA-2, to explore the effects across diverse domains and task types, such that a single language model can be decently scaled to broader applications.