 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScalable Language Model with Generalized Continual Learning
Apr 11, 2024



Continual learning has gained increasing importance as it facilitates the acquisition and refinement of scalable knowledge and skills in language models. However, existing methods typically encounter strict limitations and challenges in real-world scenarios, such as reliance on experience replay, optimization constraints, and inference task-ID. In this study, we introduce the Scalable Language Model (SLM) to overcome these limitations within a more challenging and generalized setting, representing a significant advancement toward practical applications for continual learning. Specifically, we propose the Joint Adaptive Re-Parameterization (JARe), integrated with Dynamic Task-related Knowledge Retrieval (DTKR), to enable adaptive adjustment of language models based on specific downstream tasks. This approach leverages the task distribution within the vector space, aiming to achieve a smooth and effortless continual learning process. Our method demonstrates state-of-the-art performance on diverse backbones and benchmarks, achieving effective continual learning in both full-set and few-shot scenarios with minimal forgetting. Moreover, while prior research primarily focused on a single task type such as classification, our study goes beyond, with the large language model, i.e., LLaMA-2, to explore the effects across diverse domains and task types, such that a single language model can be decently scaled to broader applications.
Exploring and Improving Mobile Level Vision Transformers
Aug 30, 2021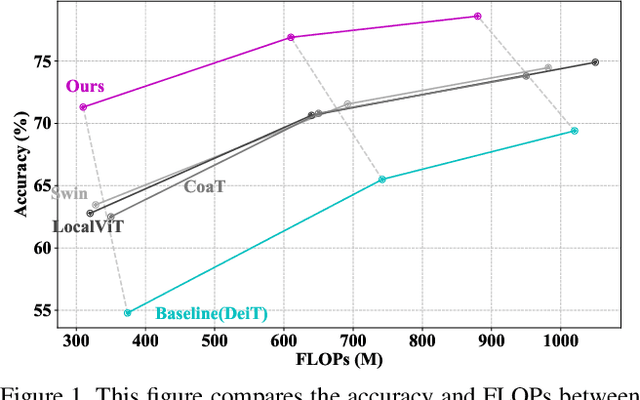
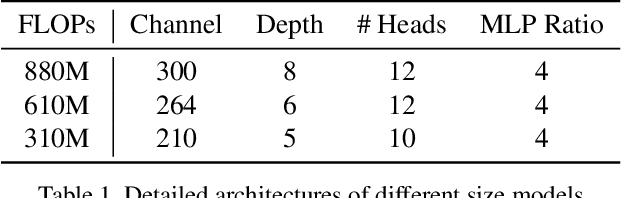
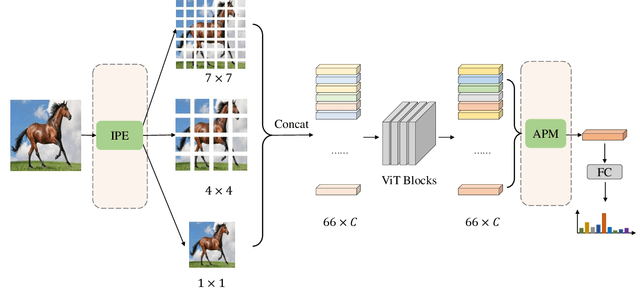
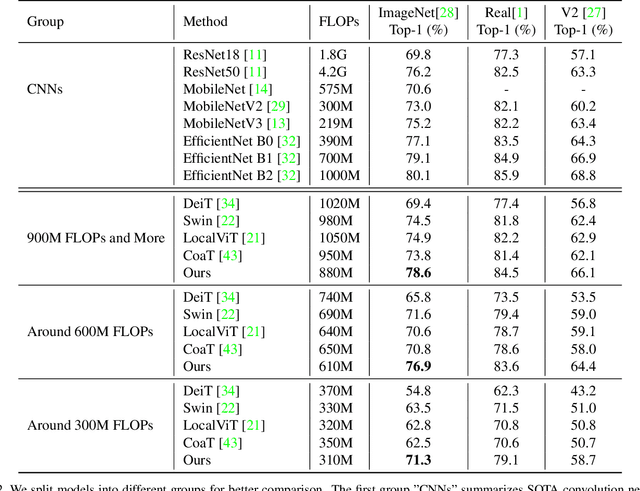
We study the vision transformer structure in the mobile level in this paper, and find a dramatic performance drop. We analyze the reason behind this phenomenon, and propose a novel irregular patch embedding module and adaptive patch fusion module to improve the performance. We conjecture that the vision transformer blocks (which consist of multi-head attention and feed-forward network) are more suitable to handle high-level information than low-level features. The irregular patch embedding module extracts patches that contain rich high-level information with different receptive fields. The transformer blocks can obtain the most useful information from these irregular patches. Then the processed patches pass the adaptive patch merging module to get the final features for the classifier. With our proposed improvements, the traditional uniform vision transformer structure can achieve state-of-the-art results in mobile level. We improve the DeiT baseline by more than 9\% under the mobile-level settings and surpass other transformer architectures like Swin and CoaT by a large margin.