 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThree-dimensional Conditional Diffusion Models for Cosmological 21 cm Lightcone Emulation
May 27, 2026We investigate conditional diffusion modeling for three-dimensional 21 cm lightcone emulation, focusing on cubes with a sky-plane size of $64\times64$ and a line-of-sight depth up to 1024 cells. Relative to earlier 2D studies, the 3D setting is substantially harder because memory limits enforce very small micro-batches while the underlying voxel distribution is highly skewed and long tailed. We perform controlled comparisons across preprocessing choices, dynamic-range compression settings, architecture depth, and training duration using $25{,}600$ training lightcones and validation ensembles at fixed parameter points. For validation, each reference parameter point contains 800 21cmFAST realizations with independent initial conditions, and we use 800 samples per model and per reference set for the reported ensemble comparisons. We evaluate generated lightcones with complementary diagnostics in both image and summary-statistic spaces: brightness-temperature slices, the global signal, the power spectrum, and reduced scattering coefficients. Across the tested configurations, preprocessing is the dominant factor governing stable training and the resulting physical fidelity. Among the configurations explored here, Yeo-Johnson preprocessing combined with moderate amplitude compression gives the most consistently favorable trade-off, with the strongest quantitative support coming from rankings based on the standard-deviation-normalized mean absolute error ($\mathrm{MAE}_{\rm std}$) of the global signal and qualitatively compatible behavior in the complementary diagnostics. At the same time, visually plausible 3D samples still retain measurable biases in two-point and higher-order statistics. We therefore view the present work as a simulation-level baseline for three-dimensional 21 cm emulation and for future studies that incorporate more realistic observational effects.
AVBench: Human-Aligned and Automated Evaluation Benchmark for Audio-Video Generative Models
May 23, 2026Rapid advances in audio-video (AV) generation have enabled high-fidelity synthesis with synchronized sound, particularly for human-related scenarios involving speech and interactions. Yet evaluation for AV generation remains at an early stage, with only a few coarse-grained benchmarks for human-related scenarios and relying on limited preset evaluations with generic multimodal LLMs, leading to inaccurate assessments of model capabilities. To address these issues, we introduce AVBench, a fully automated benchmark tailored for human-centric AV generation. AVBench is built on two key designs for comprehensive and accurate evaluation: (i) Human-centric and fine-grained metrics. AVBench integrates ten evaluation dimensions designed for human-centered real-world scenarios, covering visual quality, audio quality, and multi-level consistency across modalities. These practical metrics capture human-related details that existing benchmarks often overlook. (ii) Specialized evaluators via preference learning. To address the lack of specialized training data, we construct large-scale supervision by transforming real-world videos into diverse training pairs with controlled perturbations. After fine-tuning on this high-quality dataset, the evaluators learn to reliably detect subtle cross-modal inconsistencies. Crucially, instead of producing discrete textual judgment, AVBench derives continuous evaluation scores from the model's prediction confidence on binary decisions. This probabilistic scoring mechanism enables a more reliable assessment than traditional VQA-style evaluation and aligns closely with human judgment. Taken together, AVBench offers automated evaluation for AV generation, demonstrates strong potential for data filtering, and serves as a differentiable reward signal for Reinforcement Learning from Human Feedback (RLHF).
Divide and Conquer: Decoupled Representation Alignment for Multimodal World Models
May 03, 2026Emerging multi-modal world models attempt to jointly generate videos across diverse modalities (e.g., RGB, depth, and mask), yet they fail to fully exploit the rich priors of existing foundation models. We propose $M^2$-REPA, the first representation alignment method tailored for multi-modal video generation. Our key insight is that foundation models trained on different modality spaces naturally capture distinct domain-specific priors, acting as complementary "experts." Specifically, we first decouple modality-specific features from the diffusion model's intermediate representations, then align each with its corresponding expert foundation model. To this end, we design two synergistic objectives: a multi-modal representation alignment loss that enforces feature-to-expert matching, and a modality-specific decoupling regularization that encourages complementarity across different modalities. This design enables joint optimization, fully exploiting priors from multiple foundation models. Extensive experiments demonstrate that our method significantly outperforms baselines in visual quality and long-term consistency.
Agentic World Modeling: Foundations, Capabilities, Laws, and Beyond
Apr 24, 2026As AI systems move from generating text to accomplishing goals through sustained interaction, the ability to model environment dynamics becomes a central bottleneck. Agents that manipulate objects, navigate software, coordinate with others, or design experiments require predictive environment models, yet the term world model carries different meanings across research communities. We introduce a "levels x laws" taxonomy organized along two axes. The first defines three capability levels: L1 Predictor, which learns one-step local transition operators; L2 Simulator, which composes them into multi-step, action-conditioned rollouts that respect domain laws; and L3 Evolver, which autonomously revises its own model when predictions fail against new evidence. The second identifies four governing-law regimes: physical, digital, social, and scientific. These regimes determine what constraints a world model must satisfy and where it is most likely to fail. Using this framework, we synthesize over 400 works and summarize more than 100 representative systems spanning model-based reinforcement learning, video generation, web and GUI agents, multi-agent social simulation, and AI-driven scientific discovery. We analyze methods, failure modes, and evaluation practices across level-regime pairs, propose decision-centric evaluation principles and a minimal reproducible evaluation package, and outline architectural guidance, open problems, and governance challenges. The resulting roadmap connects previously isolated communities and charts a path from passive next-step prediction toward world models that can simulate, and ultimately reshape, the environments in which agents operate.
Index-ASR Technical Report
Dec 31, 2025Automatic speech recognition (ASR) has witnessed remarkable progress in recent years, largely driven by the emergence of LLM-based ASR paradigm. Despite their strong performance on a variety of open-source benchmarks, existing LLM-based ASR systems still suffer from two critical limitations. First, they are prone to hallucination errors, often generating excessively long and repetitive outputs that are not well grounded in the acoustic input. Second, they provide limited support for flexible and fine-grained contextual customization. To address these challenges, we propose Index-ASR, a large-scale LLM-based ASR system designed to simultaneously enhance robustness and support customizable hotword recognition. The core idea of Index-ASR lies in the integration of LLM and large-scale training data enriched with background noise and contextual information. Experimental results show that our Index-ASR achieves strong performance on both open-source benchmarks and in-house test sets, highlighting its robustness and practicality for real-world ASR applications.
DreamOmni3: Scribble-based Editing and Generation
Dec 27, 2025Recently unified generation and editing models have achieved remarkable success with their impressive performance. These models rely mainly on text prompts for instruction-based editing and generation, but language often fails to capture users intended edit locations and fine-grained visual details. To this end, we propose two tasks: scribble-based editing and generation, that enables more flexible creation on graphical user interface (GUI) combining user textual, images, and freehand sketches. We introduce DreamOmni3, tackling two challenges: data creation and framework design. Our data synthesis pipeline includes two parts: scribble-based editing and generation. For scribble-based editing, we define four tasks: scribble and instruction-based editing, scribble and multimodal instruction-based editing, image fusion, and doodle editing. Based on DreamOmni2 dataset, we extract editable regions and overlay hand-drawn boxes, circles, doodles or cropped image to construct training data. For scribble-based generation, we define three tasks: scribble and instruction-based generation, scribble and multimodal instruction-based generation, and doodle generation, following similar data creation pipelines. For the framework, instead of using binary masks, which struggle with complex edits involving multiple scribbles, images, and instructions, we propose a joint input scheme that feeds both the original and scribbled source images into the model, using different colors to distinguish regions and simplify processing. By applying the same index and position encodings to both images, the model can precisely localize scribbled regions while maintaining accurate editing. Finally, we establish comprehensive benchmarks for these tasks to promote further research. Experimental results demonstrate that DreamOmni3 achieves outstanding performance, and models and code will be publicly released.
Wan-Move: Motion-controllable Video Generation via Latent Trajectory Guidance
Dec 09, 2025We present Wan-Move, a simple and scalable framework that brings motion control to video generative models. Existing motion-controllable methods typically suffer from coarse control granularity and limited scalability, leaving their outputs insufficient for practical use. We narrow this gap by achieving precise and high-quality motion control. Our core idea is to directly make the original condition features motion-aware for guiding video synthesis. To this end, we first represent object motions with dense point trajectories, allowing fine-grained control over the scene. We then project these trajectories into latent space and propagate the first frame's features along each trajectory, producing an aligned spatiotemporal feature map that tells how each scene element should move. This feature map serves as the updated latent condition, which is naturally integrated into the off-the-shelf image-to-video model, e.g., Wan-I2V-14B, as motion guidance without any architecture change. It removes the need for auxiliary motion encoders and makes fine-tuning base models easily scalable. Through scaled training, Wan-Move generates 5-second, 480p videos whose motion controllability rivals Kling 1.5 Pro's commercial Motion Brush, as indicated by user studies. To support comprehensive evaluation, we further design MoveBench, a rigorously curated benchmark featuring diverse content categories and hybrid-verified annotations. It is distinguished by larger data volume, longer video durations, and high-quality motion annotations. Extensive experiments on MoveBench and the public dataset consistently show Wan-Move's superior motion quality. Code, models, and benchmark data are made publicly available.
UnityVideo: Unified Multi-Modal Multi-Task Learning for Enhancing World-Aware Video Generation
Dec 08, 2025Recent video generation models demonstrate impressive synthesis capabilities but remain limited by single-modality conditioning, constraining their holistic world understanding. This stems from insufficient cross-modal interaction and limited modal diversity for comprehensive world knowledge representation. To address these limitations, we introduce UnityVideo, a unified framework for world-aware video generation that jointly learns across multiple modalities (segmentation masks, human skeletons, DensePose, optical flow, and depth maps) and training paradigms. Our approach features two core components: (1) dynamic noising to unify heterogeneous training paradigms, and (2) a modality switcher with an in-context learner that enables unified processing via modular parameters and contextual learning. We contribute a large-scale unified dataset with 1.3M samples. Through joint optimization, UnityVideo accelerates convergence and significantly enhances zero-shot generalization to unseen data. We demonstrate that UnityVideo achieves superior video quality, consistency, and improved alignment with physical world constraints. Code and data can be found at: https://github.com/dvlab-research/UnityVideo
DreamVE: Unified Instruction-based Image and Video Editing
Aug 08, 2025Instruction-based editing holds vast potential due to its simple and efficient interactive editing format. However, instruction-based editing, particularly for video, has been constrained by limited training data, hindering its practical application. To this end, we introduce DreamVE, a unified model for instruction-based image and video editing. Specifically, We propose a two-stage training strategy: first image editing, then video editing. This offers two main benefits: (1) Image data scales more easily, and models are more efficient to train, providing useful priors for faster and better video editing training. (2) Unifying image and video generation is natural and aligns with current trends. Moreover, we present comprehensive training data synthesis pipelines, including collage-based and generative model-based data synthesis. The collage-based data synthesis combines foreground objects and backgrounds to generate diverse editing data, such as object manipulation, background changes, and text modifications. It can easily generate billions of accurate, consistent, realistic, and diverse editing pairs. We pretrain DreamVE on extensive collage-based data to achieve strong performance in key editing types and enhance generalization and transfer capabilities. However, collage-based data lacks some attribute editing cases, leading to a relative drop in performance. In contrast, the generative model-based pipeline, despite being hard to scale up, offers flexibility in handling attribute editing cases. Therefore, we use generative model-based data to further fine-tune DreamVE. Besides, we design an efficient and powerful editing framework for DreamVE. We build on the SOTA T2V model and use a token concatenation with early drop approach to inject source image guidance, ensuring strong consistency and editability. The codes and models will be released.
Training-Free Efficient Video Generation via Dynamic Token Carving
May 22, 2025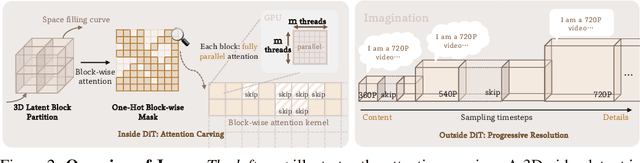
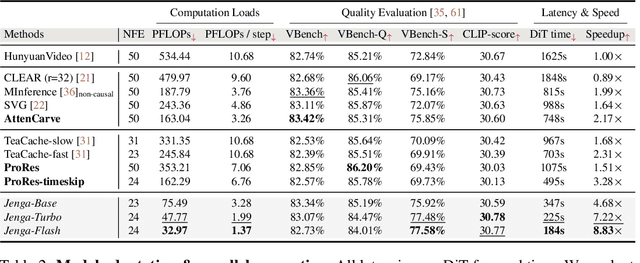
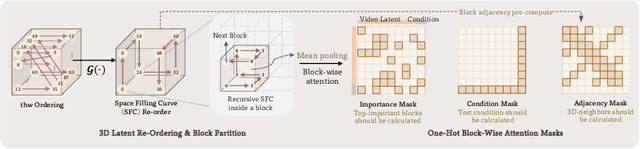
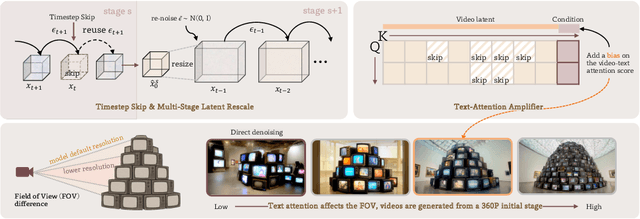
Despite the remarkable generation quality of video Diffusion Transformer (DiT) models, their practical deployment is severely hindered by extensive computational requirements. This inefficiency stems from two key challenges: the quadratic complexity of self-attention with respect to token length and the multi-step nature of diffusion models. To address these limitations, we present Jenga, a novel inference pipeline that combines dynamic attention carving with progressive resolution generation. Our approach leverages two key insights: (1) early denoising steps do not require high-resolution latents, and (2) later steps do not require dense attention. Jenga introduces a block-wise attention mechanism that dynamically selects relevant token interactions using 3D space-filling curves, alongside a progressive resolution strategy that gradually increases latent resolution during generation. Experimental results demonstrate that Jenga achieves substantial speedups across multiple state-of-the-art video diffusion models while maintaining comparable generation quality (8.83$\times$ speedup with 0.01\% performance drop on VBench). As a plug-and-play solution, Jenga enables practical, high-quality video generation on modern hardware by reducing inference time from minutes to seconds -- without requiring model retraining. Code: https://github.com/dvlab-research/Jenga