 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffStereo: High-Frequency Aware Diffusion Model for Stereo Image Restoration
Jan 17, 2025Diffusion models (DMs) have achieved promising performance in image restoration but haven't been explored for stereo images. The application of DM in stereo image restoration is confronted with a series of challenges. The need to reconstruct two images exacerbates DM's computational cost. Additionally, existing latent DMs usually focus on semantic information and remove high-frequency details as redundancy during latent compression, which is precisely what matters for image restoration. To address the above problems, we propose a high-frequency aware diffusion model, DiffStereo for stereo image restoration as the first attempt at DM in this domain. Specifically, DiffStereo first learns latent high-frequency representations (LHFR) of HQ images. DM is then trained in the learned space to estimate LHFR for stereo images, which are fused into a transformer-based stereo image restoration network providing beneficial high-frequency information of corresponding HQ images. The resolution of LHFR is kept the same as input images, which preserves the inherent texture from distortion. And the compression in channels alleviates the computational burden of DM. Furthermore, we devise a position encoding scheme when integrating the LHFR into the restoration network, enabling distinctive guidance in different depths of the restoration network. Comprehensive experiments verify that by combining generative DM and transformer, DiffStereo achieves both higher reconstruction accuracy and better perceptual quality on stereo super-resolution, deblurring, and low-light enhancement compared with state-of-the-art methods.
VmambaIR: Visual State Space Model for Image Restoration
Mar 18, 2024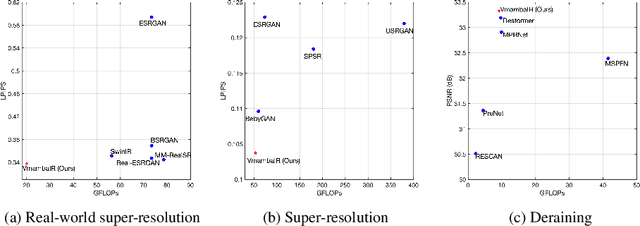
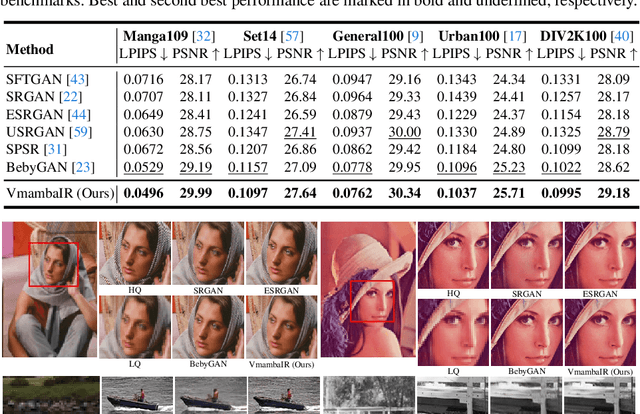
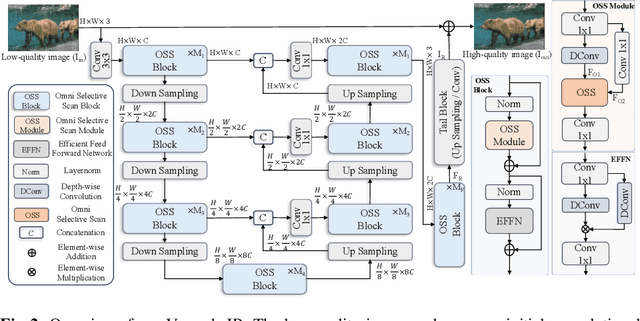
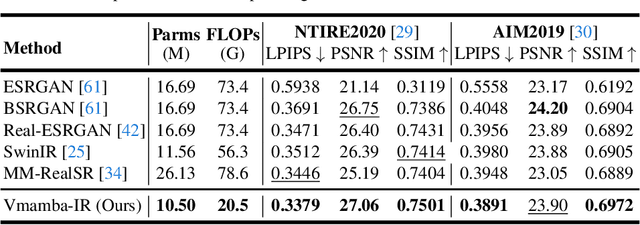
Image restoration is a critical task in low-level computer vision, aiming to restore high-quality images from degraded inputs. Various models, such as convolutional neural networks (CNNs), generative adversarial networks (GANs), transformers, and diffusion models (DMs), have been employed to address this problem with significant impact. However, CNNs have limitations in capturing long-range dependencies. DMs require large prior models and computationally intensive denoising steps. Transformers have powerful modeling capabilities but face challenges due to quadratic complexity with input image size. To address these challenges, we propose VmambaIR, which introduces State Space Models (SSMs) with linear complexity into comprehensive image restoration tasks. We utilize a Unet architecture to stack our proposed Omni Selective Scan (OSS) blocks, consisting of an OSS module and an Efficient Feed-Forward Network (EFFN). Our proposed omni selective scan mechanism overcomes the unidirectional modeling limitation of SSMs by efficiently modeling image information flows in all six directions. Furthermore, we conducted a comprehensive evaluation of our VmambaIR across multiple image restoration tasks, including image deraining, single image super-resolution, and real-world image super-resolution. Extensive experimental results demonstrate that our proposed VmambaIR achieves state-of-the-art (SOTA) performance with much fewer computational resources and parameters. Our research highlights the potential of state space models as promising alternatives to the transformer and CNN architectures in serving as foundational frameworks for next-generation low-level visual tasks.
LLMRA: Multi-modal Large Language Model based Restoration Assistant
Jan 21, 2024Multi-modal Large Language Models (MLLMs) have a significant impact on various tasks, due to their extensive knowledge and powerful perception and generation capabilities. However, it still remains an open research problem on applying MLLMs to low-level vision tasks. In this paper, we present a simple MLLM-based Image Restoration framework to address this gap, namely Multi-modal Large Language Model based Restoration Assistant (LLMRA). We exploit the impressive capabilities of MLLMs to obtain the degradation information for universal image restoration. By employing a pretrained multi-modal large language model and a vision language model, we generate text descriptions and encode them as context embedding with degradation information for the degraded image. Through the proposed Context Enhance Module (CEM) and Degradation Context based Transformer Network (DC-former), we integrate these context embedding into the restoration network, contributing to more accurate and adjustable image restoration. Based on the dialogue with the users, our method leverages image degradation priors from MLLMs, providing low-level attributes descriptions of the input low-quality images and the restored high-quality images simultaneously. Extensive experiments demonstrate the superior performance of our LLMRA in universal image restoration tasks.
DSR-Diff: Depth Map Super-Resolution with Diffusion Model
Nov 16, 2023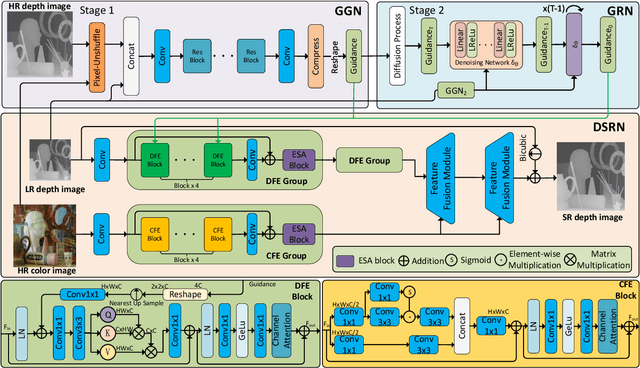
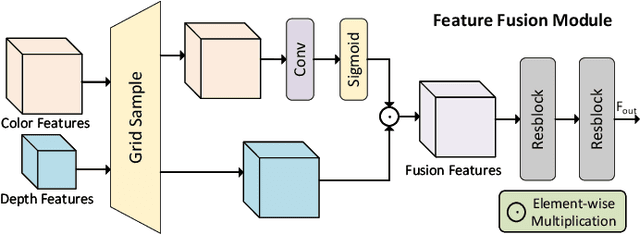
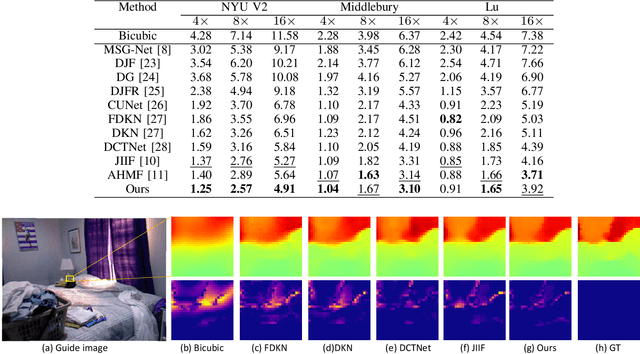
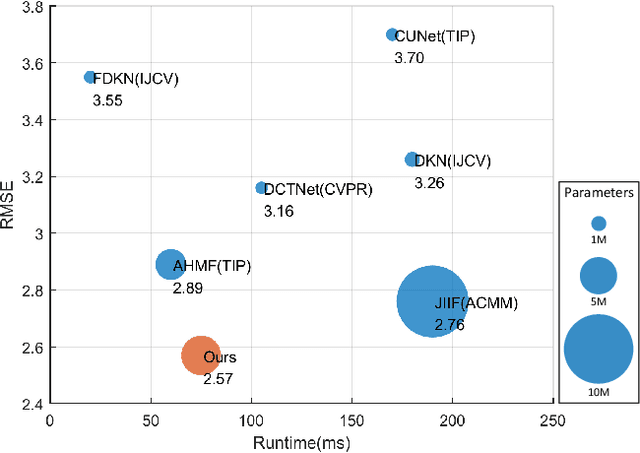
Color-guided depth map super-resolution (CDSR) improve the spatial resolution of a low-quality depth map with the corresponding high-quality color map, benefiting various applications such as 3D reconstruction, virtual reality, and augmented reality. While conventional CDSR methods typically rely on convolutional neural networks or transformers, diffusion models (DMs) have demonstrated notable effectiveness in high-level vision tasks. In this work, we present a novel CDSR paradigm that utilizes a diffusion model within the latent space to generate guidance for depth map super-resolution. The proposed method comprises a guidance generation network (GGN), a depth map super-resolution network (DSRN), and a guidance recovery network (GRN). The GGN is specifically designed to generate the guidance while managing its compactness. Additionally, we integrate a simple but effective feature fusion module and a transformer-style feature extraction module into the DSRN, enabling it to leverage guided priors in the extraction, fusion, and reconstruction of multi-model images. Taking into account both accuracy and efficiency, our proposed method has shown superior performance in extensive experiments when compared to state-of-the-art methods. Our codes will be made available at https://github.com/shiyuan7/DSR-Diff.
Using Domain Knowledge for Low Resource Named Entity Recognition
Mar 28, 2022
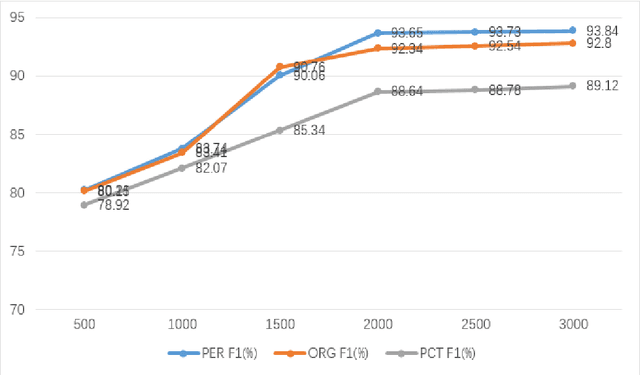
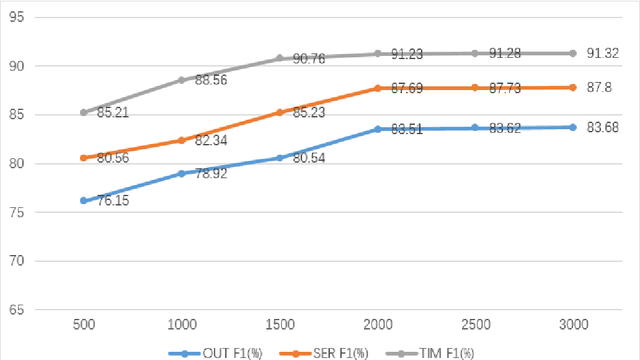

In recent years, named entity recognition has always been a popular research in the field of natural language processing, while traditional deep learning methods require a large amount of labeled data for model training, which makes them not suitable for areas where labeling resources are scarce. In addition, the existing cross-domain knowledge transfer methods need to adjust the entity labels for different fields, so as to increase the training cost. To solve these problems, enlightened by a processing method of Chinese named entity recognition, we propose to use domain knowledge to improve the performance of named entity recognition in areas with low resources. The domain knowledge mainly applied by us is domain dictionary and domain labeled data. We use dictionary information for each word to strengthen its word embedding and domain labeled data to reinforce the recognition effect. The proposed model avoids large-scale data adjustments in different domains while handling named entities recognition with low resources. Experiments demonstrate the effectiveness of our method, which has achieved impressive results on the data set in the field of scientific and technological equipment, and the F1 score has been significantly improved compared with many other baseline methods.
Surgical Scheduling via Optimization and Machine Learning with Long-Tailed Data
Feb 13, 2022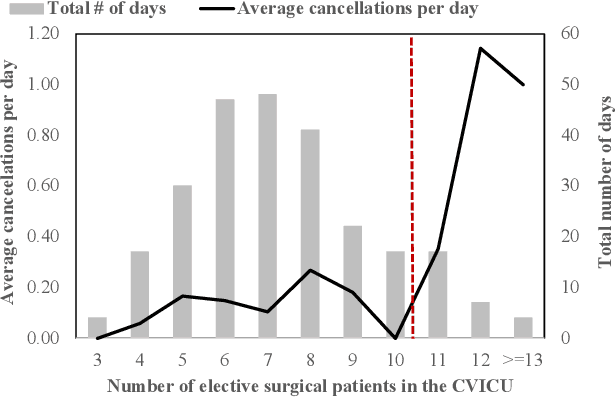
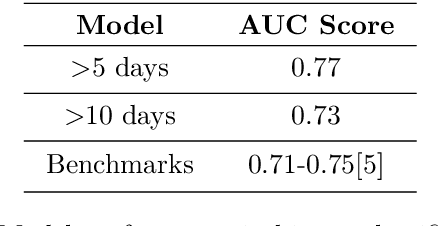
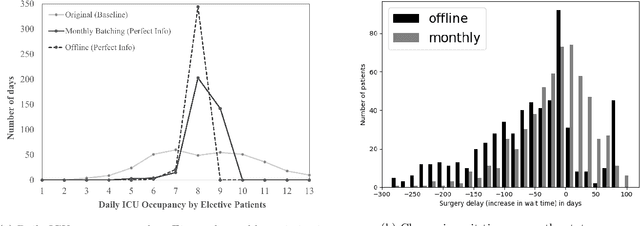
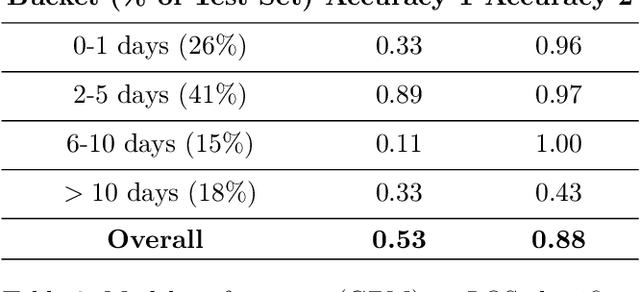
Using data from cardiovascular surgery patients with long and highly variable post-surgical lengths of stay (LOS), we develop a model to reduce recovery unit congestion. We estimate LOS using a variety of machine learning models, schedule procedures with a variety of online optimization models, and estimate performance with simulation. The machine learning models achieved only modest LOS prediction accuracy, despite access to a very rich set of patient characteristics. Compared to the current paper-based system used in the hospital, most optimization models failed to reduce congestion without increasing wait times for surgery. A conservative stochastic optimization with sufficient sampling to capture the long tail of the LOS distribution outperformed the current manual process. These results highlight the perils of using oversimplified distributional models of patient length of stay for scheduling procedures and the importance of using stochastic optimization well-suited to dealing with long-tailed behavior.
Sparse Compositional Metric Learning
Apr 15, 2014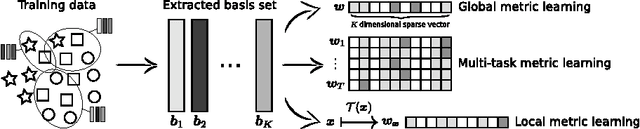
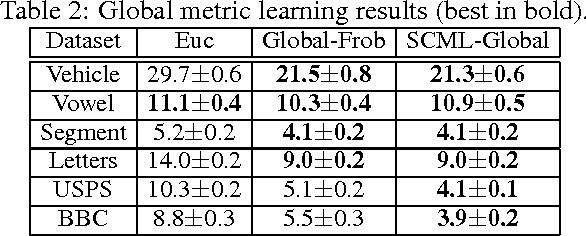
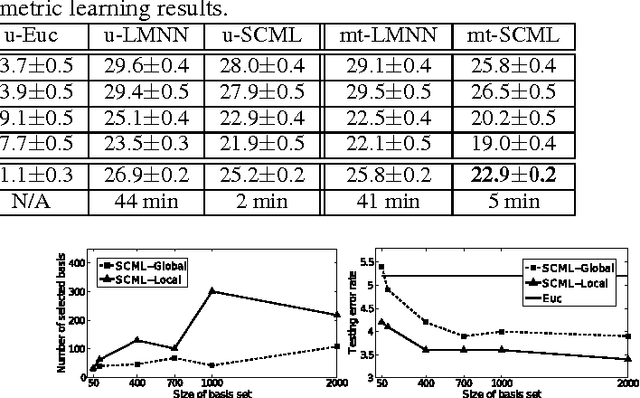
We propose a new approach for metric learning by framing it as learning a sparse combination of locally discriminative metrics that are inexpensive to generate from the training data. This flexible framework allows us to naturally derive formulations for global, multi-task and local metric learning. The resulting algorithms have several advantages over existing methods in the literature: a much smaller number of parameters to be estimated and a principled way to generalize learned metrics to new testing data points. To analyze the approach theoretically, we derive a generalization bound that justifies the sparse combination. Empirically, we evaluate our algorithms on several datasets against state-of-the-art metric learning methods. The results are consistent with our theoretical findings and demonstrate the superiority of our approach in terms of classification performance and scalability.
Information-Theoretical Learning of Discriminative Clusters for Unsupervised Domain Adaptation
Jun 27, 2012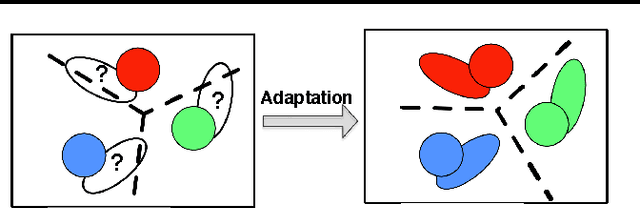
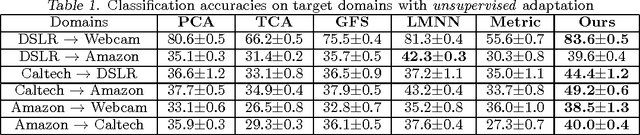

We study the problem of unsupervised domain adaptation, which aims to adapt classifiers trained on a labeled source domain to an unlabeled target domain. Many existing approaches first learn domain-invariant features and then construct classifiers with them. We propose a novel approach that jointly learn the both. Specifically, while the method identifies a feature space where data in the source and the target domains are similarly distributed, it also learns the feature space discriminatively, optimizing an information-theoretic metric as an proxy to the expected misclassification error on the target domain. We show how this optimization can be effectively carried out with simple gradient-based methods and how hyperparameters can be cross-validated without demanding any labeled data from the target domain. Empirical studies on benchmark tasks of object recognition and sentiment analysis validated our modeling assumptions and demonstrated significant improvement of our method over competing ones in classification accuracies.
Learning Discriminative Metrics via Generative Models and Kernel Learning
Sep 19, 2011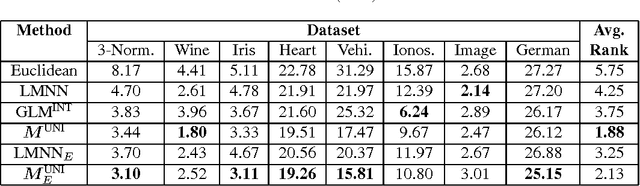
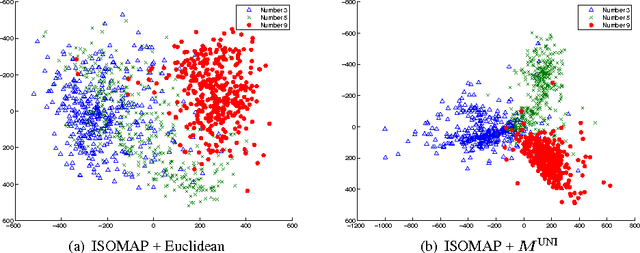
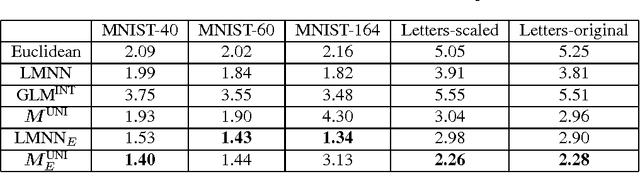

Metrics specifying distances between data points can be learned in a discriminative manner or from generative models. In this paper, we show how to unify generative and discriminative learning of metrics via a kernel learning framework. Specifically, we learn local metrics optimized from parametric generative models. These are then used as base kernels to construct a global kernel that minimizes a discriminative training criterion. We consider both linear and nonlinear combinations of local metric kernels. Our empirical results show that these combinations significantly improve performance on classification tasks. The proposed learning algorithm is also very efficient, achieving order of magnitude speedup in training time compared to previous discriminative baseline methods.