 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeECHO: Towards Emotionally Appropriate and Contextually Aware Interactive Head Generation
Mar 18, 2026In natural face-to-face interaction, participants seamlessly alternate between speaking and listening, producing facial behaviors (FBs) that are finely informed by long-range context and naturally exhibit contextual appropriateness and emotional rationality. Interactive Head Generation (IHG) aims to synthesize lifelike avatar head video emulating such capabilities. Existing IHG methods typically condition on dual-track signals (i.e., human user's behaviors and pre-defined audio for avatar) within a short temporal window, jointly driving generation of avatar's audio-aligned lip articulation and non-verbal FBs. However, two main challenges persist in these methods: (i) the reliance on short-clip behavioral cues without long-range contextual modeling leads them to produce facial behaviors lacking contextual appropriateness; and (ii) the entangled, role-agnostic fusion of dual-track signals empirically introduces cross-signal interference, potentially compromising lip-region synchronization during speaking. To this end, we propose ECHO, a novel IHG framework comprising two key components: a Long-range Contextual Understanding (LCU) component that facilitates contextual understanding of both behavior-grounded dynamics and linguistic-driven affective semantics to promote contextual appropriateness and emotional rationality of synthesized avatar FBs; and a block-wise Spatial-aware Decoupled Cross-attention Modulation (SDCM) module, that preserves self-audio-driven lip articulation while adaptively integrating user contextual behavioral cues for non-lip facial regions, complemented by our designed two-stage training paradigm, to jointly enhance lip synchronization and visual fidelity. Extensive experiments demonstrate the effectiveness of proposed components and ECHO's superior IHG performance.
HunyuanPortrait: Implicit Condition Control for Enhanced Portrait Animation
Mar 25, 2025We introduce HunyuanPortrait, a diffusion-based condition control method that employs implicit representations for highly controllable and lifelike portrait animation. Given a single portrait image as an appearance reference and video clips as driving templates, HunyuanPortrait can animate the character in the reference image by the facial expression and head pose of the driving videos. In our framework, we utilize pre-trained encoders to achieve the decoupling of portrait motion information and identity in videos. To do so, implicit representation is adopted to encode motion information and is employed as control signals in the animation phase. By leveraging the power of stable video diffusion as the main building block, we carefully design adapter layers to inject control signals into the denoising unet through attention mechanisms. These bring spatial richness of details and temporal consistency. HunyuanPortrait also exhibits strong generalization performance, which can effectively disentangle appearance and motion under different image styles. Our framework outperforms existing methods, demonstrating superior temporal consistency and controllability. Our project is available at https://kkakkkka.github.io/HunyuanPortrait.
DiffStereo: High-Frequency Aware Diffusion Model for Stereo Image Restoration
Jan 17, 2025Diffusion models (DMs) have achieved promising performance in image restoration but haven't been explored for stereo images. The application of DM in stereo image restoration is confronted with a series of challenges. The need to reconstruct two images exacerbates DM's computational cost. Additionally, existing latent DMs usually focus on semantic information and remove high-frequency details as redundancy during latent compression, which is precisely what matters for image restoration. To address the above problems, we propose a high-frequency aware diffusion model, DiffStereo for stereo image restoration as the first attempt at DM in this domain. Specifically, DiffStereo first learns latent high-frequency representations (LHFR) of HQ images. DM is then trained in the learned space to estimate LHFR for stereo images, which are fused into a transformer-based stereo image restoration network providing beneficial high-frequency information of corresponding HQ images. The resolution of LHFR is kept the same as input images, which preserves the inherent texture from distortion. And the compression in channels alleviates the computational burden of DM. Furthermore, we devise a position encoding scheme when integrating the LHFR into the restoration network, enabling distinctive guidance in different depths of the restoration network. Comprehensive experiments verify that by combining generative DM and transformer, DiffStereo achieves both higher reconstruction accuracy and better perceptual quality on stereo super-resolution, deblurring, and low-light enhancement compared with state-of-the-art methods.
Alignment is All You Need: A Training-free Augmentation Strategy for Pose-guided Video Generation
Aug 29, 2024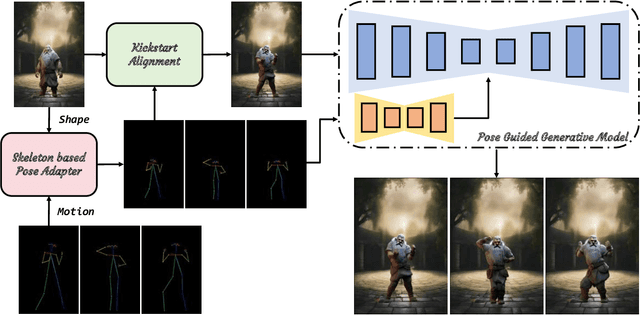



Character animation is a transformative field in computer graphics and vision, enabling dynamic and realistic video animations from static images. Despite advancements, maintaining appearance consistency in animations remains a challenge. Our approach addresses this by introducing a training-free framework that ensures the generated video sequence preserves the reference image's subtleties, such as physique and proportions, through a dual alignment strategy. We decouple skeletal and motion priors from pose information, enabling precise control over animation generation. Our method also improves pixel-level alignment for conditional control from the reference character, enhancing the temporal consistency and visual cohesion of animations. Our method significantly enhances the quality of video generation without the need for large datasets or expensive computational resources.
VmambaIR: Visual State Space Model for Image Restoration
Mar 18, 2024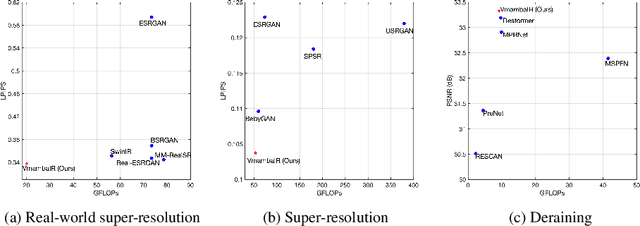
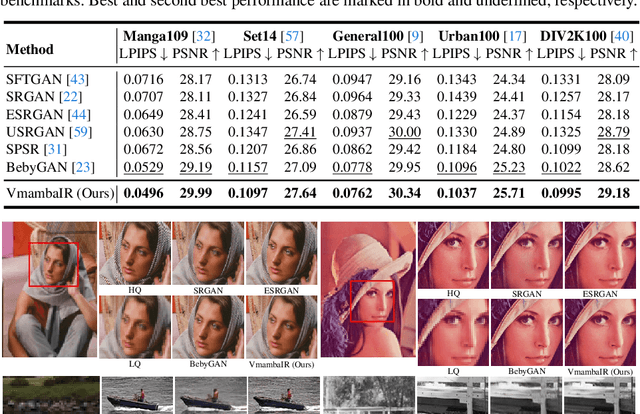
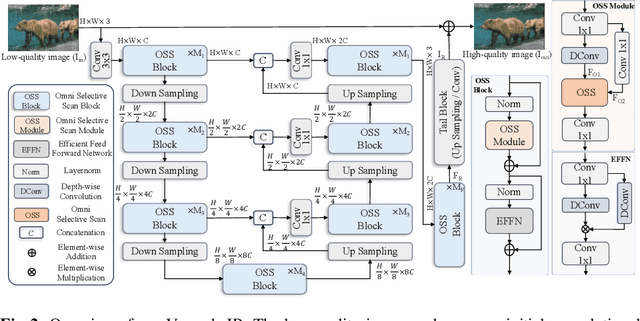
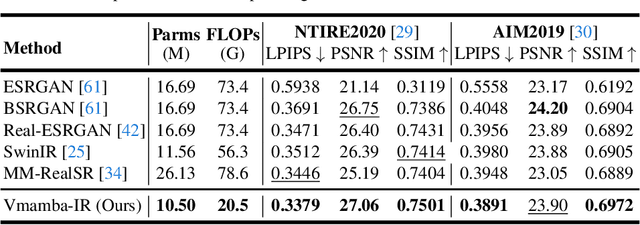
Image restoration is a critical task in low-level computer vision, aiming to restore high-quality images from degraded inputs. Various models, such as convolutional neural networks (CNNs), generative adversarial networks (GANs), transformers, and diffusion models (DMs), have been employed to address this problem with significant impact. However, CNNs have limitations in capturing long-range dependencies. DMs require large prior models and computationally intensive denoising steps. Transformers have powerful modeling capabilities but face challenges due to quadratic complexity with input image size. To address these challenges, we propose VmambaIR, which introduces State Space Models (SSMs) with linear complexity into comprehensive image restoration tasks. We utilize a Unet architecture to stack our proposed Omni Selective Scan (OSS) blocks, consisting of an OSS module and an Efficient Feed-Forward Network (EFFN). Our proposed omni selective scan mechanism overcomes the unidirectional modeling limitation of SSMs by efficiently modeling image information flows in all six directions. Furthermore, we conducted a comprehensive evaluation of our VmambaIR across multiple image restoration tasks, including image deraining, single image super-resolution, and real-world image super-resolution. Extensive experimental results demonstrate that our proposed VmambaIR achieves state-of-the-art (SOTA) performance with much fewer computational resources and parameters. Our research highlights the potential of state space models as promising alternatives to the transformer and CNN architectures in serving as foundational frameworks for next-generation low-level visual tasks.
LLMRA: Multi-modal Large Language Model based Restoration Assistant
Jan 21, 2024Multi-modal Large Language Models (MLLMs) have a significant impact on various tasks, due to their extensive knowledge and powerful perception and generation capabilities. However, it still remains an open research problem on applying MLLMs to low-level vision tasks. In this paper, we present a simple MLLM-based Image Restoration framework to address this gap, namely Multi-modal Large Language Model based Restoration Assistant (LLMRA). We exploit the impressive capabilities of MLLMs to obtain the degradation information for universal image restoration. By employing a pretrained multi-modal large language model and a vision language model, we generate text descriptions and encode them as context embedding with degradation information for the degraded image. Through the proposed Context Enhance Module (CEM) and Degradation Context based Transformer Network (DC-former), we integrate these context embedding into the restoration network, contributing to more accurate and adjustable image restoration. Based on the dialogue with the users, our method leverages image degradation priors from MLLMs, providing low-level attributes descriptions of the input low-quality images and the restored high-quality images simultaneously. Extensive experiments demonstrate the superior performance of our LLMRA in universal image restoration tasks.