 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSAM-R1: Leveraging SAM for Reward Feedback in Multimodal Segmentation via Reinforcement Learning
May 28, 2025Leveraging multimodal large models for image segmentation has become a prominent research direction. However, existing approaches typically rely heavily on manually annotated datasets that include explicit reasoning processes, which are costly and time-consuming to produce. Recent advances suggest that reinforcement learning (RL) can endow large models with reasoning capabilities without requiring such reasoning-annotated data. In this paper, we propose SAM-R1, a novel framework that enables multimodal large models to perform fine-grained reasoning in image understanding tasks. Our approach is the first to incorporate fine-grained segmentation settings during the training of multimodal reasoning models. By integrating task-specific, fine-grained rewards with a tailored optimization objective, we further enhance the model's reasoning and segmentation alignment. We also leverage the Segment Anything Model (SAM) as a strong and flexible reward provider to guide the learning process. With only 3k training samples, SAM-R1 achieves strong performance across multiple benchmarks, demonstrating the effectiveness of reinforcement learning in equipping multimodal models with segmentation-oriented reasoning capabilities.
Separate to Collaborate: Dual-Stream Diffusion Model for Coordinated Piano Hand Motion Synthesis
Apr 14, 2025Automating the synthesis of coordinated bimanual piano performances poses significant challenges, particularly in capturing the intricate choreography between the hands while preserving their distinct kinematic signatures. In this paper, we propose a dual-stream neural framework designed to generate synchronized hand gestures for piano playing from audio input, addressing the critical challenge of modeling both hand independence and coordination. Our framework introduces two key innovations: (i) a decoupled diffusion-based generation framework that independently models each hand's motion via dual-noise initialization, sampling distinct latent noise for each while leveraging a shared positional condition, and (ii) a Hand-Coordinated Asymmetric Attention (HCAA) mechanism suppresses symmetric (common-mode) noise to highlight asymmetric hand-specific features, while adaptively enhancing inter-hand coordination during denoising. The system operates hierarchically: it first predicts 3D hand positions from audio features and then generates joint angles through position-aware diffusion models, where parallel denoising streams interact via HCAA. Comprehensive evaluations demonstrate that our framework outperforms existing state-of-the-art methods across multiple metrics.
PAFT: Prompt-Agnostic Fine-Tuning
Feb 18, 2025While Large Language Models (LLMs) adapt well to downstream tasks after fine-tuning, this adaptability often compromises prompt robustness, as even minor prompt variations can significantly degrade performance. To address this, we propose Prompt-Agnostic Fine-Tuning(PAFT), a simple yet effective approach that dynamically adjusts prompts during fine-tuning. This encourages the model to learn underlying task principles rather than overfitting to specific prompt formulations. PAFT operates in two stages: First, a diverse set of meaningful, synthetic candidate prompts is constructed. Second, during fine-tuning, prompts are randomly sampled from this set to create dynamic training inputs. Extensive experiments across diverse datasets and LLMs demonstrate that models trained with PAFT exhibit strong robustness and generalization across a wide range of prompts, including unseen ones. This enhanced robustness improves both model performance and inference speed while maintaining training efficiency. Ablation studies further confirm the effectiveness of PAFT.
Alignment is All You Need: A Training-free Augmentation Strategy for Pose-guided Video Generation
Aug 29, 2024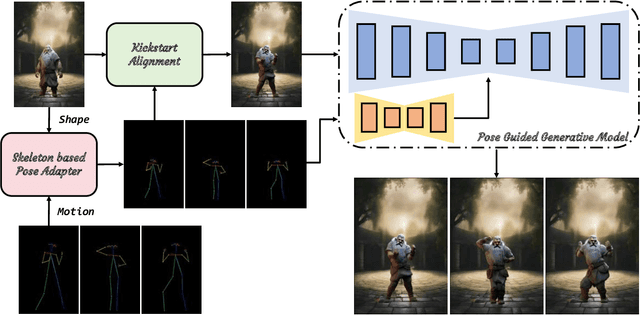



Character animation is a transformative field in computer graphics and vision, enabling dynamic and realistic video animations from static images. Despite advancements, maintaining appearance consistency in animations remains a challenge. Our approach addresses this by introducing a training-free framework that ensures the generated video sequence preserves the reference image's subtleties, such as physique and proportions, through a dual alignment strategy. We decouple skeletal and motion priors from pose information, enabling precise control over animation generation. Our method also improves pixel-level alignment for conditional control from the reference character, enhancing the temporal consistency and visual cohesion of animations. Our method significantly enhances the quality of video generation without the need for large datasets or expensive computational resources.