 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniSVG: A Unified Dataset for Vector Graphic Understanding and Generation with Multimodal Large Language Models
Aug 11, 2025Unlike bitmap images, scalable vector graphics (SVG) maintain quality when scaled, frequently employed in computer vision and artistic design in the representation of SVG code. In this era of proliferating AI-powered systems, enabling AI to understand and generate SVG has become increasingly urgent. However, AI-driven SVG understanding and generation (U&G) remain significant challenges. SVG code, equivalent to a set of curves and lines controlled by floating-point parameters, demands high precision in SVG U&G. Besides, SVG generation operates under diverse conditional constraints, including textual prompts and visual references, which requires powerful multi-modal processing for condition-to-SVG transformation. Recently, the rapid growth of Multi-modal Large Language Models (MLLMs) have demonstrated capabilities to process multi-modal inputs and generate complex vector controlling parameters, suggesting the potential to address SVG U&G tasks within a unified model. To unlock MLLM's capabilities in the SVG area, we propose an SVG-centric dataset called UniSVG, comprising 525k data items, tailored for MLLM training and evaluation. To our best knowledge, it is the first comprehensive dataset designed for unified SVG generation (from textual prompts and images) and SVG understanding (color, category, usage, etc.). As expected, learning on the proposed dataset boosts open-source MLLMs' performance on various SVG U&G tasks, surpassing SOTA close-source MLLMs like GPT-4V. We release dataset, benchmark, weights, codes and experiment details on https://ryanlijinke.github.io/.
PAFT: Prompt-Agnostic Fine-Tuning
Feb 18, 2025While Large Language Models (LLMs) adapt well to downstream tasks after fine-tuning, this adaptability often compromises prompt robustness, as even minor prompt variations can significantly degrade performance. To address this, we propose Prompt-Agnostic Fine-Tuning(PAFT), a simple yet effective approach that dynamically adjusts prompts during fine-tuning. This encourages the model to learn underlying task principles rather than overfitting to specific prompt formulations. PAFT operates in two stages: First, a diverse set of meaningful, synthetic candidate prompts is constructed. Second, during fine-tuning, prompts are randomly sampled from this set to create dynamic training inputs. Extensive experiments across diverse datasets and LLMs demonstrate that models trained with PAFT exhibit strong robustness and generalization across a wide range of prompts, including unseen ones. This enhanced robustness improves both model performance and inference speed while maintaining training efficiency. Ablation studies further confirm the effectiveness of PAFT.
Flexora: Flexible Low Rank Adaptation for Large Language Models
Aug 21, 2024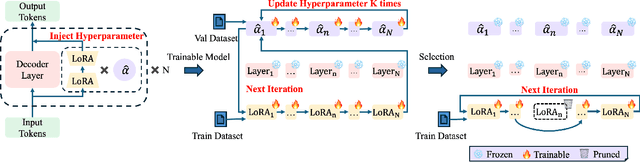
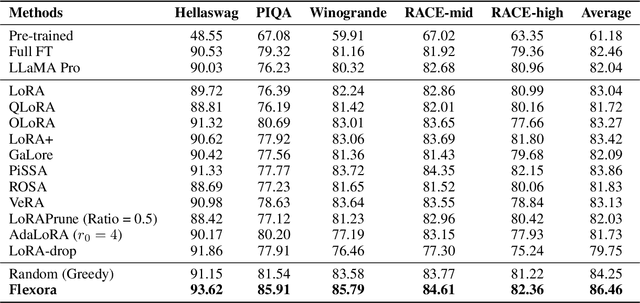

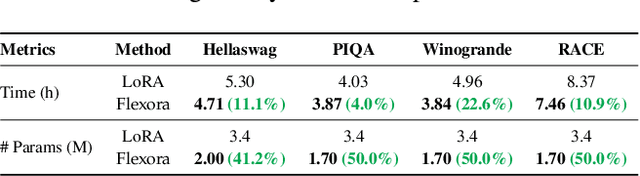
Large Language Models (LLMs) are driving advancements in artificial intelligence by increasing the scale of model parameters, which has significantly enhanced generalization ability and unlocked new capabilities in practice. However, their performance in specific downstream tasks is usually hindered by their knowledge boundaries on these tasks. Thus, fine-tuning techniques, especially the widely used Low-Rank Adaptation (LoRA) method, have been introduced to expand the boundaries on these tasks, whereas LoRA would underperform on certain tasks owing to its potential overfitting on these tasks. To overcome this overfitting and improve the performance of LoRA, we propose the flexible low rank adaptation (Flexora) method to automatically and flexibly select the most important layers needing to be fine-tuned to achieve the best performance on different downstream tasks. Specifically, Flexora firstly frames this layer selection problem as a well-defined hyperparameter optimization (HPO) problem, then addresses it using the unrolled differentiation (UD) method, and finally selects the most useful layers based on the optimized hyperparameters. Our extensive experiments on many pretrained models and natural language tasks show that Flexora is able to consistently improve over the existing baselines, indicating the effectiveness of our Flexora in practice. We additionally provide insightful theoretical results and many ablation studies to deliver a comprehensive understanding of our Flexora.