 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReCreate: Reasoning and Creating Domain Agents Driven by Experience
Jan 16, 2026Large Language Model agents are reshaping the industrial landscape. However, most practical agents remain human-designed because tasks differ widely, making them labor-intensive to build. This situation poses a central question: can we automatically create and adapt domain agents in the wild? While several recent approaches have sought to automate agent creation, they typically treat agent generation as a black-box procedure and rely solely on final performance metrics to guide the process. Such strategies overlook critical evidence explaining why an agent succeeds or fails, and often require high computational costs. To address these limitations, we propose ReCreate, an experience-driven framework for the automatic creation of domain agents. ReCreate systematically leverages agent interaction histories, which provide rich concrete signals on both the causes of success or failure and the avenues for improvement. Specifically, we introduce an agent-as-optimizer paradigm that effectively learns from experience via three key components: (i) an experience storage and retrieval mechanism for on-demand inspection; (ii) a reasoning-creating synergy pipeline that maps execution experience into scaffold edits; and (iii) hierarchical updates that abstract instance-level details into reusable domain patterns. In experiments across diverse domains, ReCreate consistently outperforms human-designed agents and existing automated agent generation methods, even when starting from minimal seed scaffolds.
Unleashing the True Potential of LLMs: A Feedback-Triggered Self-Correction with Long-Term Multipath Decoding
Sep 09, 2025Large Language Models (LLMs) have achieved remarkable performance across diverse tasks, yet their susceptibility to generating incorrect content during inference remains a critical unsolved challenge. While self-correction methods offer potential solutions, their effectiveness is hindered by two inherent limitations: (1) the absence of reliable guidance signals for error localization, and (2) the restricted reasoning depth imposed by conventional next-token decoding paradigms. To address these issues, we propose Feedback-Triggered Regeneration (FTR), a novel framework that synergizes user feedback with enhanced decoding dynamics. Specifically, FTR activates response regeneration only upon receiving negative user feedback, thereby circumventing error propagation from faulty self-assessment while preserving originally correct outputs. Furthermore, we introduce Long-Term Multipath (LTM) decoding, which enables systematic exploration of multiple reasoning trajectories through delayed sequence evaluation, effectively overcoming the myopic decision-making characteristic of standard next-token prediction. Extensive experiments on mathematical reasoning and code generation benchmarks demonstrate that our framework achieves consistent and significant improvements over state-of-the-art prompt-based self-correction methods.
UniSVG: A Unified Dataset for Vector Graphic Understanding and Generation with Multimodal Large Language Models
Aug 11, 2025Unlike bitmap images, scalable vector graphics (SVG) maintain quality when scaled, frequently employed in computer vision and artistic design in the representation of SVG code. In this era of proliferating AI-powered systems, enabling AI to understand and generate SVG has become increasingly urgent. However, AI-driven SVG understanding and generation (U&G) remain significant challenges. SVG code, equivalent to a set of curves and lines controlled by floating-point parameters, demands high precision in SVG U&G. Besides, SVG generation operates under diverse conditional constraints, including textual prompts and visual references, which requires powerful multi-modal processing for condition-to-SVG transformation. Recently, the rapid growth of Multi-modal Large Language Models (MLLMs) have demonstrated capabilities to process multi-modal inputs and generate complex vector controlling parameters, suggesting the potential to address SVG U&G tasks within a unified model. To unlock MLLM's capabilities in the SVG area, we propose an SVG-centric dataset called UniSVG, comprising 525k data items, tailored for MLLM training and evaluation. To our best knowledge, it is the first comprehensive dataset designed for unified SVG generation (from textual prompts and images) and SVG understanding (color, category, usage, etc.). As expected, learning on the proposed dataset boosts open-source MLLMs' performance on various SVG U&G tasks, surpassing SOTA close-source MLLMs like GPT-4V. We release dataset, benchmark, weights, codes and experiment details on https://ryanlijinke.github.io/.
EFIM: Efficient Serving of LLMs for Infilling Tasks with Improved KV Cache Reuse
May 29, 2025Large language models (LLMs) are often used for infilling tasks, which involve predicting or generating missing information in a given text. These tasks typically require multiple interactions with similar context. To reduce the computation of repeated historical tokens, cross-request key-value (KV) cache reuse, a technique that stores and reuses intermediate computations, has become a crucial method in multi-round interactive services. However, in infilling tasks, the KV cache reuse is often hindered by the structure of the prompt format, which typically consists of a prefix and suffix relative to the insertion point. Specifically, the KV cache of the prefix or suffix part is frequently invalidated as the other part (suffix or prefix) is incrementally generated. To address the issue, we propose EFIM, a transformed prompt format of FIM to unleash the performance potential of KV cache reuse. Although the transformed prompt can solve the inefficiency, it exposes subtoken generation problems in current LLMs, where they have difficulty generating partial words accurately. Therefore, we introduce a fragment tokenization training method which splits text into multiple fragments before tokenization during data processing. Experiments on two representative LLMs show that LLM serving with EFIM can lower the latency by 52% and improve the throughput by 98% while maintaining the original infilling capability. EFIM's source code is publicly available at https://github.com/gty111/EFIM.
AutoDebias: Learning to Debias for Recommendation
May 10, 2021
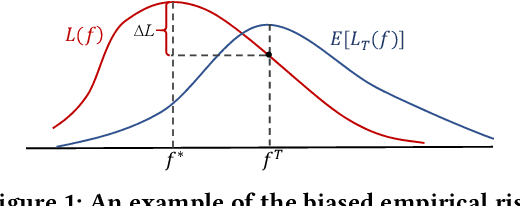
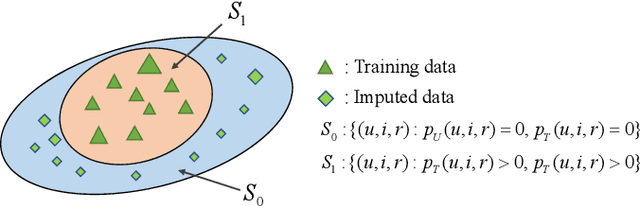
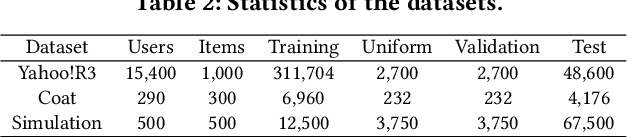
Recommender systems rely on user behavior data like ratings and clicks to build personalization model. However, the collected data is observational rather than experimental, causing various biases in the data which significantly affect the learned model. Most existing work for recommendation debiasing, such as the inverse propensity scoring and imputation approaches, focuses on one or two specific biases, lacking the universal capacity that can account for mixed or even unknown biases in the data. Towards this research gap, we first analyze the origin of biases from the perspective of \textit{risk discrepancy} that represents the difference between the expectation empirical risk and the true risk. Remarkably, we derive a general learning framework that well summarizes most existing debiasing strategies by specifying some parameters of the general framework. This provides a valuable opportunity to develop a universal solution for debiasing, e.g., by learning the debiasing parameters from data. However, the training data lacks important signal of how the data is biased and what the unbiased data looks like. To move this idea forward, we propose \textit{AotoDebias} that leverages another (small) set of uniform data to optimize the debiasing parameters by solving the bi-level optimization problem with meta-learning. Through theoretical analyses, we derive the generalization bound for AutoDebias and prove its ability to acquire the appropriate debiasing strategy. Extensive experiments on two real datasets and a simulated dataset demonstrated effectiveness of AutoDebias. The code is available at \url{https://github.com/DongHande/AutoDebias}.
On the Equivalence of Decoupled Graph Convolution Network and Label Propagation
Oct 23, 2020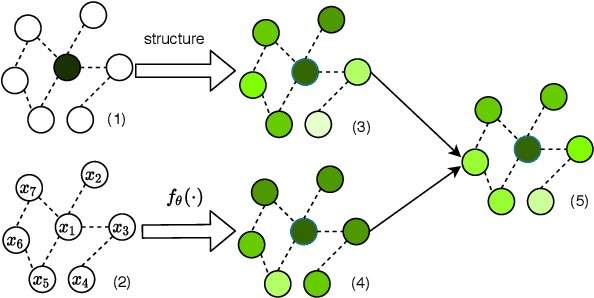

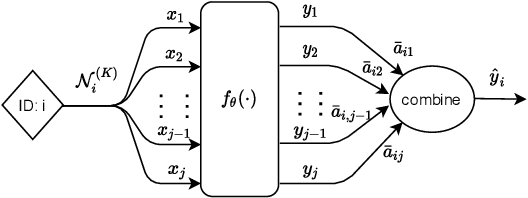
The original design of Graph Convolution Network (GCN) couples feature transformation and neighborhood aggregation for node representation learning. Recently, some work shows that coupling is inferior to decoupling, which supports deep graph propagation and has become the latest paradigm of GCN (e.g., APPNP and SGCN). Despite effectiveness, the working mechanisms of the decoupled GCN are not well understood. In this paper, we explore the decoupled GCN for semi-supervised node classification from a novel and fundamental perspective -- label propagation. We conduct thorough theoretical analyses, proving that the decoupled GCN is essentially the same as the two-step label propagation: first, propagating the known labels along the graph to generate pseudo-labels for the unlabeled nodes, and second, training normal neural network classifiers on the augmented pseudo-labeled data. More interestingly, we reveal the effectiveness of decoupled GCN: going beyond the conventional label propagation, it could automatically assign structure- and model- aware weights to the pseudo-label data. This explains why the decoupled GCN is relatively robust to the structure noise and over-smoothing, but sensitive to the label noise and model initialization. Based on this insight, we propose a new label propagation method named Propagation then Training Adaptively (PTA), which overcomes the flaws of the decoupled GCN with a dynamic and adaptive weighting strategy. Our PTA is simple yet more effective and robust than decoupled GCN. We empirically validate our findings on four benchmark datasets, demonstrating the advantages of our method.
Data Augmentation View on Graph Convolutional Network and the Proposal of Monte Carlo Graph Learning
Jun 23, 2020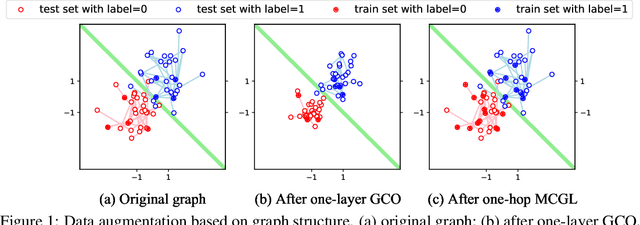

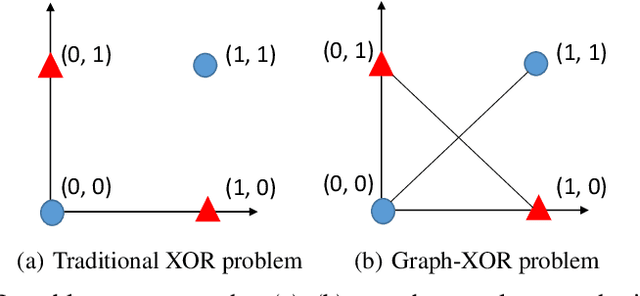

Today, there are two major understandings for graph convolutional networks, i.e., in the spectral and spatial domain. But both lack transparency. In this work, we introduce a new understanding for it -- data augmentation, which is more transparent than the previous understandings. Inspired by it, we propose a new graph learning paradigm -- Monte Carlo Graph Learning (MCGL). The core idea of MCGL contains: (1) Data augmentation: propagate the labels of the training set through the graph structure and expand the training set; (2) Model training: use the expanded training set to train traditional classifiers. We use synthetic datasets to compare the strengths of MCGL and graph convolutional operation on clean graphs. In addition, we show that MCGL's tolerance to graph structure noise is weaker than GCN on noisy graphs (four real-world datasets). Moreover, inspired by MCGL, we re-analyze the reasons why the performance of GCN becomes worse when deepened too much: rather than the mainstream view of over-smoothing, we argue that the main reason is the graph structure noise, and experimentally verify our view. The code is available at https://github.com/DongHande/MCGL.