 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModeling User Behavior with Graph Convolution for Personalized Product Search
Feb 12, 2022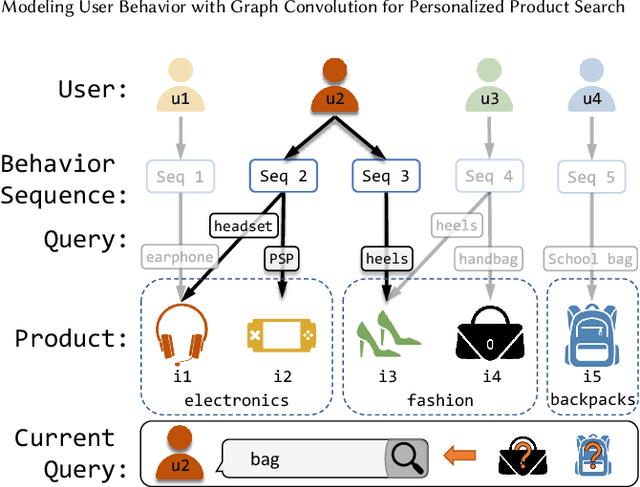
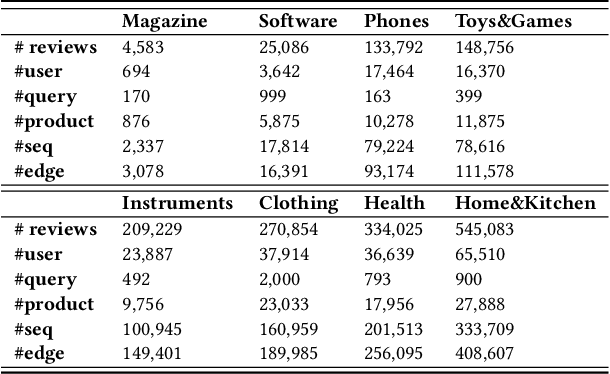
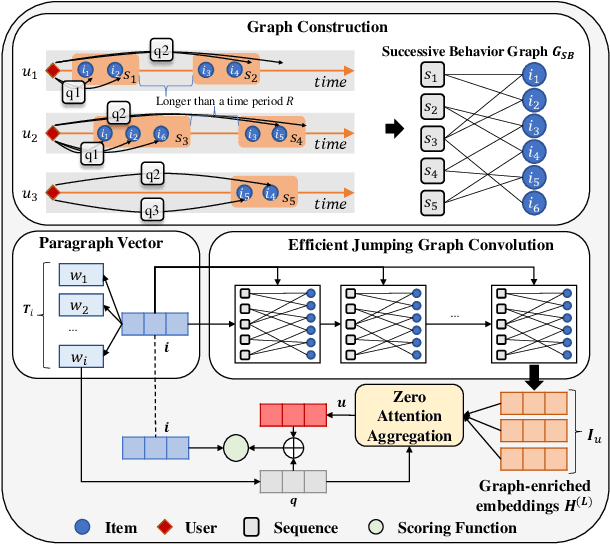
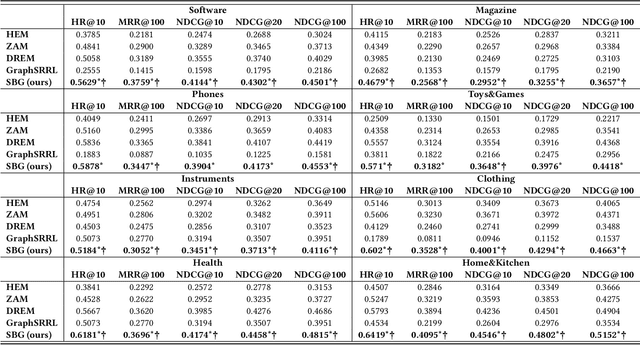
User preference modeling is a vital yet challenging problem in personalized product search. In recent years, latent space based methods have achieved state-of-the-art performance by jointly learning semantic representations of products, users, and text tokens. However, existing methods are limited in their ability to model user preferences. They typically represent users by the products they visited in a short span of time using attentive models and lack the ability to exploit relational information such as user-product interactions or item co-occurrence relations. In this work, we propose to address the limitations of prior arts by exploring local and global user behavior patterns on a user successive behavior graph, which is constructed by utilizing short-term actions of all users. To capture implicit user preference signals and collaborative patterns, we use an efficient jumping graph convolution to explore high-order relations to enrich product representations for user preference modeling. Our approach can be seamlessly integrated with existing latent space based methods and be potentially applied in any product retrieval method that uses purchase history to model user preferences. Extensive experiments on eight Amazon benchmarks demonstrate the effectiveness and potential of our approach. The source code is available at \url{https://github.com/floatSDSDS/SBG}.
Embedding-based Product Retrieval in Taobao Search
Jun 17, 2021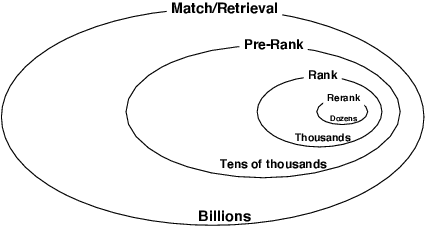

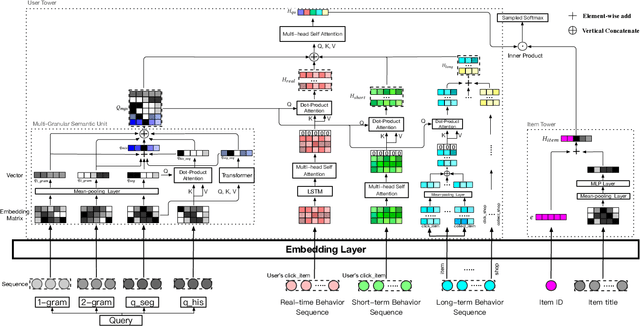
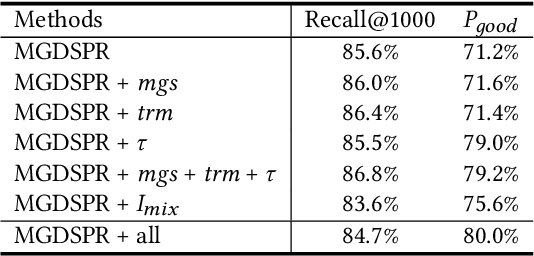
Nowadays, the product search service of e-commerce platforms has become a vital shopping channel in people's life. The retrieval phase of products determines the search system's quality and gradually attracts researchers' attention. Retrieving the most relevant products from a large-scale corpus while preserving personalized user characteristics remains an open question. Recent approaches in this domain have mainly focused on embedding-based retrieval (EBR) systems. However, after a long period of practice on Taobao, we find that the performance of the EBR system is dramatically degraded due to its: (1) low relevance with a given query and (2) discrepancy between the training and inference phases. Therefore, we propose a novel and practical embedding-based product retrieval model, named Multi-Grained Deep Semantic Product Retrieval (MGDSPR). Specifically, we first identify the inconsistency between the training and inference stages, and then use the softmax cross-entropy loss as the training objective, which achieves better performance and faster convergence. Two efficient methods are further proposed to improve retrieval relevance, including smoothing noisy training data and generating relevance-improving hard negative samples without requiring extra knowledge and training procedures. We evaluate MGDSPR on Taobao Product Search with significant metrics gains observed in offline experiments and online A/B tests. MGDSPR has been successfully deployed to the existing multi-channel retrieval system in Taobao Search. We also introduce the online deployment scheme and share practical lessons of our retrieval system to contribute to the community.
AutoDebias: Learning to Debias for Recommendation
May 10, 2021
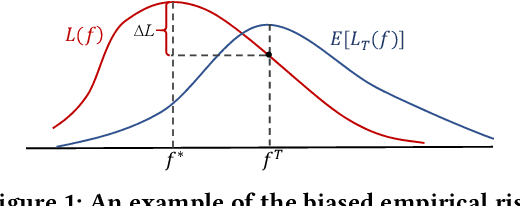
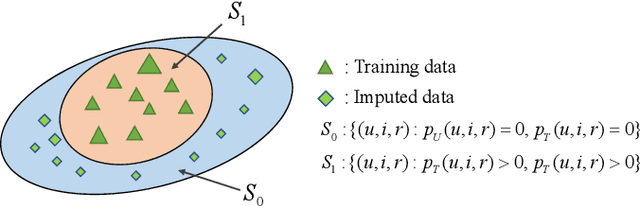
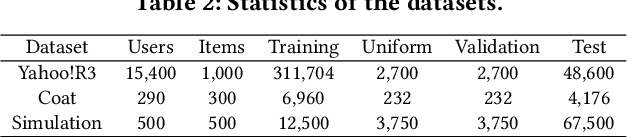
Recommender systems rely on user behavior data like ratings and clicks to build personalization model. However, the collected data is observational rather than experimental, causing various biases in the data which significantly affect the learned model. Most existing work for recommendation debiasing, such as the inverse propensity scoring and imputation approaches, focuses on one or two specific biases, lacking the universal capacity that can account for mixed or even unknown biases in the data. Towards this research gap, we first analyze the origin of biases from the perspective of \textit{risk discrepancy} that represents the difference between the expectation empirical risk and the true risk. Remarkably, we derive a general learning framework that well summarizes most existing debiasing strategies by specifying some parameters of the general framework. This provides a valuable opportunity to develop a universal solution for debiasing, e.g., by learning the debiasing parameters from data. However, the training data lacks important signal of how the data is biased and what the unbiased data looks like. To move this idea forward, we propose \textit{AotoDebias} that leverages another (small) set of uniform data to optimize the debiasing parameters by solving the bi-level optimization problem with meta-learning. Through theoretical analyses, we derive the generalization bound for AutoDebias and prove its ability to acquire the appropriate debiasing strategy. Extensive experiments on two real datasets and a simulated dataset demonstrated effectiveness of AutoDebias. The code is available at \url{https://github.com/DongHande/AutoDebias}.
M2GRL: A Multi-task Multi-view Graph Representation Learning Framework for Web-scale Recommender Systems
Jun 01, 2020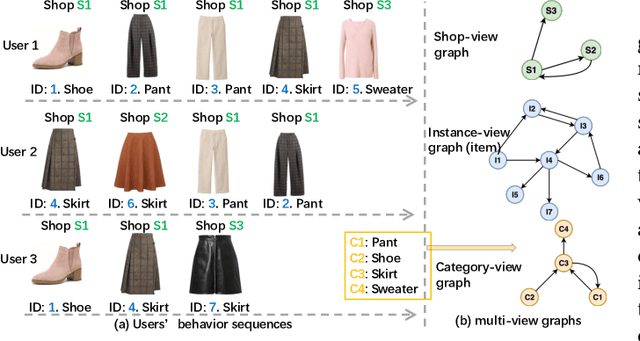

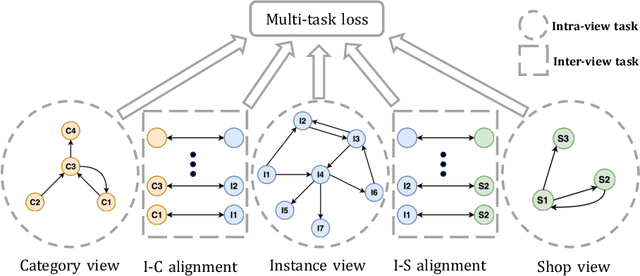
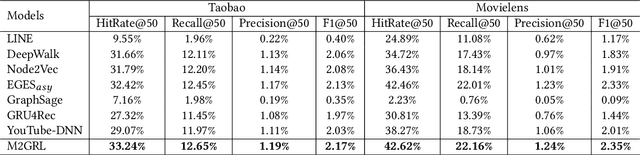
Combining graph representation learning with multi-view data (side information) for recommendation is a trend in industry. Most existing methods can be categorized as \emph{multi-view representation fusion}; they first build one graph and then integrate multi-view data into a single compact representation for each node in the graph. However, these methods are raising concerns in both engineering and algorithm aspects: 1) multi-view data are abundant and informative in industry and may exceed the capacity of one single vector, and 2) inductive bias may be introduced as multi-view data are often from different distributions. In this paper, we use a \emph{multi-view representation alignment} approach to address this issue. Particularly, we propose a multi-task multi-view graph representation learning framework (M2GRL) to learn node representations from multi-view graphs for web-scale recommender systems. M2GRL constructs one graph for each single-view data, learns multiple separate representations from multiple graphs, and performs alignment to model cross-view relations. M2GRL chooses a multi-task learning paradigm to learn intra-view representations and cross-view relations jointly. Besides, M2GRL applies homoscedastic uncertainty to adaptively tune the loss weights of tasks during training. We deploy M2GRL at Taobao and train it on 57 billion examples. According to offline metrics and online A/B tests, M2GRL significantly outperforms other state-of-the-art algorithms. Further exploration on diversity recommendation in Taobao shows the effectiveness of utilizing multiple representations produced by \method{}, which we argue is a promising direction for various industrial recommendation tasks of different focus.