 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeM2GRL: A Multi-task Multi-view Graph Representation Learning Framework for Web-scale Recommender Systems
Paper and Code
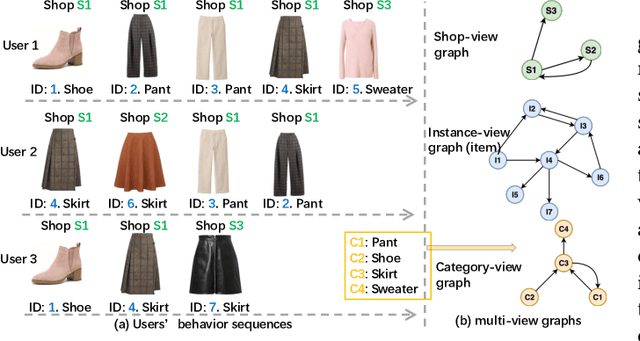

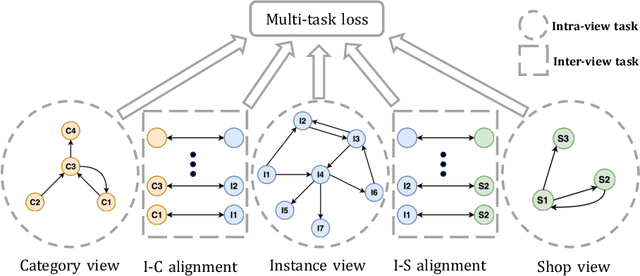
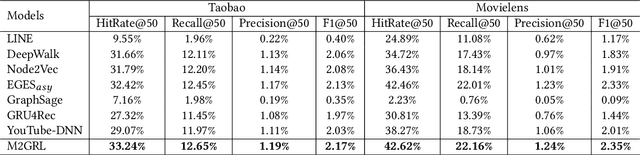
Combining graph representation learning with multi-view data (side information) for recommendation is a trend in industry. Most existing methods can be categorized as \emph{multi-view representation fusion}; they first build one graph and then integrate multi-view data into a single compact representation for each node in the graph. However, these methods are raising concerns in both engineering and algorithm aspects: 1) multi-view data are abundant and informative in industry and may exceed the capacity of one single vector, and 2) inductive bias may be introduced as multi-view data are often from different distributions. In this paper, we use a \emph{multi-view representation alignment} approach to address this issue. Particularly, we propose a multi-task multi-view graph representation learning framework (M2GRL) to learn node representations from multi-view graphs for web-scale recommender systems. M2GRL constructs one graph for each single-view data, learns multiple separate representations from multiple graphs, and performs alignment to model cross-view relations. M2GRL chooses a multi-task learning paradigm to learn intra-view representations and cross-view relations jointly. Besides, M2GRL applies homoscedastic uncertainty to adaptively tune the loss weights of tasks during training. We deploy M2GRL at Taobao and train it on 57 billion examples. According to offline metrics and online A/B tests, M2GRL significantly outperforms other state-of-the-art algorithms. Further exploration on diversity recommendation in Taobao shows the effectiveness of utilizing multiple representations produced by \method{}, which we argue is a promising direction for various industrial recommendation tasks of different focus.