 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModeling User Behavior with Graph Convolution for Personalized Product Search
Feb 12, 2022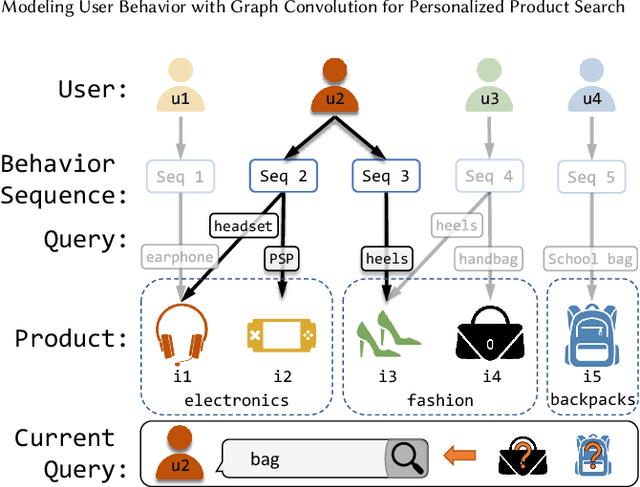
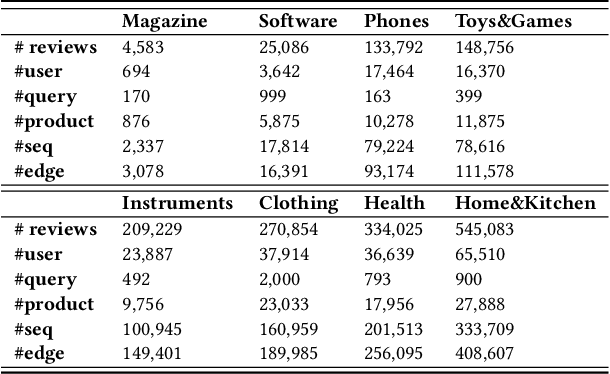
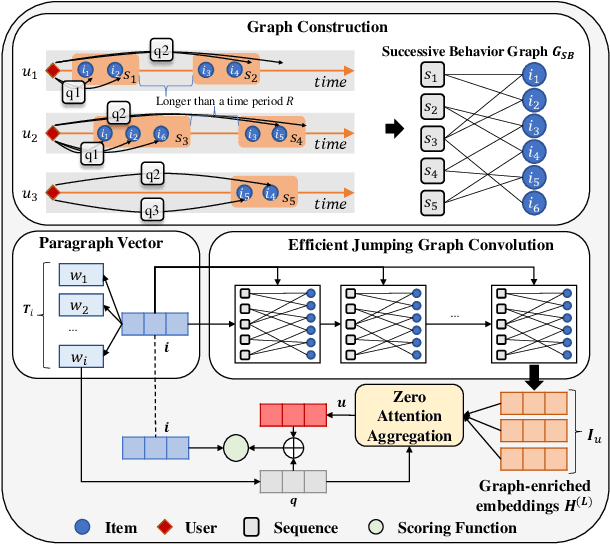
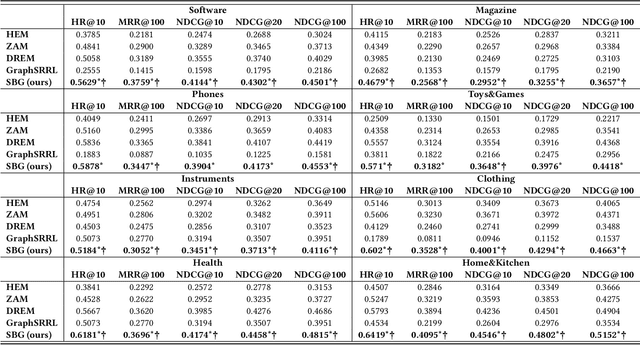
User preference modeling is a vital yet challenging problem in personalized product search. In recent years, latent space based methods have achieved state-of-the-art performance by jointly learning semantic representations of products, users, and text tokens. However, existing methods are limited in their ability to model user preferences. They typically represent users by the products they visited in a short span of time using attentive models and lack the ability to exploit relational information such as user-product interactions or item co-occurrence relations. In this work, we propose to address the limitations of prior arts by exploring local and global user behavior patterns on a user successive behavior graph, which is constructed by utilizing short-term actions of all users. To capture implicit user preference signals and collaborative patterns, we use an efficient jumping graph convolution to explore high-order relations to enrich product representations for user preference modeling. Our approach can be seamlessly integrated with existing latent space based methods and be potentially applied in any product retrieval method that uses purchase history to model user preferences. Extensive experiments on eight Amazon benchmarks demonstrate the effectiveness and potential of our approach. The source code is available at \url{https://github.com/floatSDSDS/SBG}.
Embedding-based Product Retrieval in Taobao Search
Jun 17, 2021

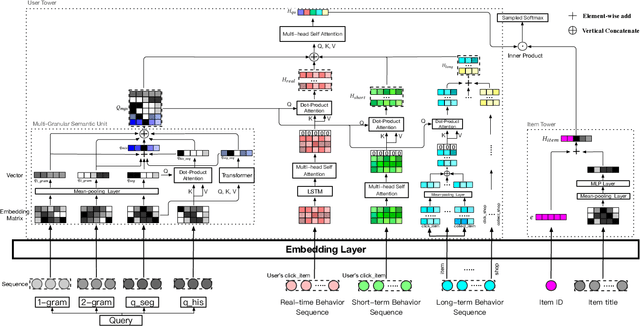
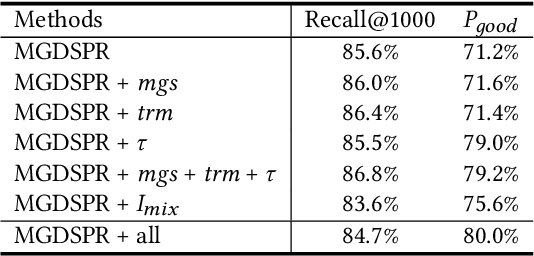
Nowadays, the product search service of e-commerce platforms has become a vital shopping channel in people's life. The retrieval phase of products determines the search system's quality and gradually attracts researchers' attention. Retrieving the most relevant products from a large-scale corpus while preserving personalized user characteristics remains an open question. Recent approaches in this domain have mainly focused on embedding-based retrieval (EBR) systems. However, after a long period of practice on Taobao, we find that the performance of the EBR system is dramatically degraded due to its: (1) low relevance with a given query and (2) discrepancy between the training and inference phases. Therefore, we propose a novel and practical embedding-based product retrieval model, named Multi-Grained Deep Semantic Product Retrieval (MGDSPR). Specifically, we first identify the inconsistency between the training and inference stages, and then use the softmax cross-entropy loss as the training objective, which achieves better performance and faster convergence. Two efficient methods are further proposed to improve retrieval relevance, including smoothing noisy training data and generating relevance-improving hard negative samples without requiring extra knowledge and training procedures. We evaluate MGDSPR on Taobao Product Search with significant metrics gains observed in offline experiments and online A/B tests. MGDSPR has been successfully deployed to the existing multi-channel retrieval system in Taobao Search. We also introduce the online deployment scheme and share practical lessons of our retrieval system to contribute to the community.
Multi-Level Deep Cascade Trees for Conversion Rate Prediction
Aug 29, 2018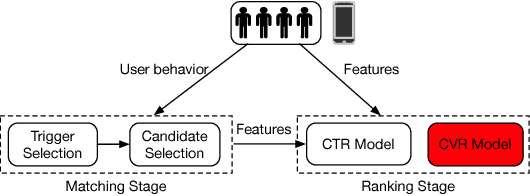

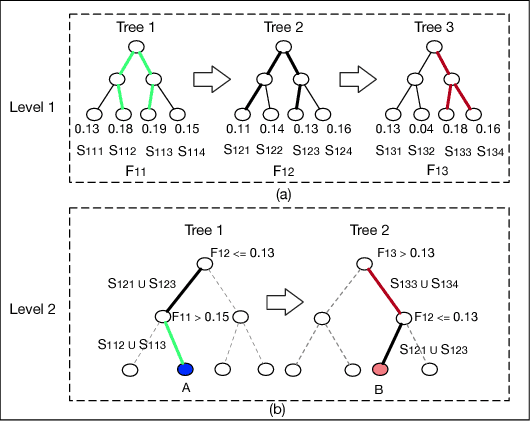

Developing effective and efficient recommendation methods is very challenging for modern e-commerce platforms (e.g., Taobao). In this paper, we tackle this problem by proposing multi-Level Deep Cascade Trees (ldcTree), which is a novel decision tree ensemble approach. It leverages deep cascade structures by stacking Gradient Boosting Decision Trees (GBDT) to effectively learn feature representation. In addition, we propose to utilize the cross-entropy in each tree of the preceding GBDT as the input feature representation for next level GBDT, which has a clear explanation, i.e., a traversal from root to leaf nodes in the next level GBDT corresponds to the combination of certain traversals in the preceding GBDT. The deep cascade structure and the combination rule enable the proposed ldcTree to have a stronger distributed feature representation ability. Moreover, we propose an ensemble ldcTree to take full use of weak and strong correlation features. Experimental results on off-line dataset and online deployment demonstrate the effectiveness of the proposed methods.