 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLEMUR: Large scale End-to-end MUltimodal Recommendation
Nov 17, 2025Traditional ID-based recommender systems often struggle with cold-start and generalization challenges. Multimodal recommendation systems, which leverage textual and visual data, offer a promising solution to mitigate these issues. However, existing industrial approaches typically adopt a two-stage training paradigm: first pretraining a multimodal model, then applying its frozen representations to train the recommendation model. This decoupled framework suffers from misalignment between multimodal learning and recommendation objectives, as well as an inability to adapt dynamically to new data. To address these limitations, we propose LEMUR, the first large-scale multimodal recommender system trained end-to-end from raw data. By jointly optimizing both the multimodal and recommendation components, LEMUR ensures tighter alignment with downstream objectives while enabling real-time parameter updates. Constructing multimodal sequential representations from user history often entails prohibitively high computational costs. To alleviate this bottleneck, we propose a novel memory bank mechanism that incrementally accumulates historical multimodal representations throughout the training process. After one month of deployment in Douyin Search, LEMUR has led to a 0.843% reduction in query change rate decay and a 0.81% improvement in QAUC. Additionally, LEMUR has shown significant gains across key offline metrics for Douyin Advertisement. Our results validate the superiority of end-to-end multimodal recommendation in real-world industrial scenarios.
WK-Pnet: FM-Based Positioning via Wavelet Packet Decomposition and Knowledge Distillation
Apr 10, 2025



Accurate and efficient positioning in complex environments is critical for applications where traditional satellite-based systems face limitations, such as indoors or urban canyons. This paper introduces WK-Pnet, an FM-based indoor positioning framework that combines wavelet packet decomposition (WPD) and knowledge distillation. WK-Pnet leverages WPD to extract rich time-frequency features from FM signals, which are then processed by a deep learning model for precise position estimation. To address computational demands, we employ knowledge distillation, transferring insights from a high-capacity model to a streamlined student model, achieving substantial reductions in complexity without sacrificing accuracy. Experimental results across diverse environments validate WK-Pnet's superior positioning accuracy and lower computational requirements, making it a viable solution for positioning in real-time resource-constraint applications.
DS-Pnet: FM-Based Positioning via Downsampling
Apr 10, 2025



In this paper we present DS-Pnet, a novel framework for FM signal-based positioning that addresses the challenges of high computational complexity and limited deployment in resource-constrained environments. Two downsampling methods-IQ signal downsampling and time-frequency representation downsampling-are proposed to reduce data dimensionality while preserving critical positioning features. By integrating with the lightweight MobileViT-XS neural network, the framework achieves high positioning accuracy with significantly reduced computational demands. Experiments on real-world FM signal datasets demonstrate that DS-Pnet achieves superior performance in both indoor and outdoor scenarios, with space and time complexity reductions of approximately 87% and 99.5%, respectively, compared to an existing method, FM-Pnet. Despite the high compression, DS-Pnet maintains robust positioning accuracy, offering an optimal balance between efficiency and precision.
Do Not Wait: Learning Re-Ranking Model Without User Feedback At Serving Time in E-Commerce
Jun 20, 2024Recommender systems have been widely used in e-commerce, and re-ranking models are playing an increasingly significant role in the domain, which leverages the inter-item influence and determines the final recommendation lists. Online learning methods keep updating a deployed model with the latest available samples to capture the shifting of the underlying data distribution in e-commerce. However, they depend on the availability of real user feedback, which may be delayed by hours or even days, such as item purchases, leading to a lag in model enhancement. In this paper, we propose a novel extension of online learning methods for re-ranking modeling, which we term LAST, an acronym for Learning At Serving Time. It circumvents the requirement of user feedback by using a surrogate model to provide the instructional signal needed to steer model improvement. Upon receiving an online request, LAST finds and applies a model modification on the fly before generating a recommendation result for the request. The modification is request-specific and transient. It means the modification is tailored to and only to the current request to capture the specific context of the request. After a request, the modification is discarded, which helps to prevent error propagation and stabilizes the online learning procedure since the predictions of the surrogate model may be inaccurate. Most importantly, as a complement to feedback-based online learning methods, LAST can be seamlessly integrated into existing online learning systems to create a more adaptive and responsive recommendation experience. Comprehensive experiments, both offline and online, affirm that LAST outperforms state-of-the-art re-ranking models.
Controllable Multi-Objective Re-ranking with Policy Hypernetworks
Jun 13, 2023



Multi-stage ranking pipelines have become widely used strategies in modern recommender systems, where the final stage aims to return a ranked list of items that balances a number of requirements such as user preference, diversity, novelty etc. Linear scalarization is arguably the most widely used technique to merge multiple requirements into one optimization objective, by summing up the requirements with certain preference weights. Existing final-stage ranking methods often adopt a static model where the preference weights are determined during offline training and kept unchanged during online serving. Whenever a modification of the preference weights is needed, the model has to be re-trained, which is time and resources inefficient. Meanwhile, the most appropriate weights may vary greatly for different groups of targeting users or at different time periods (e.g., during holiday promotions). In this paper, we propose a framework called controllable multi-objective re-ranking (CMR) which incorporates a hypernetwork to generate parameters for a re-ranking model according to different preference weights. In this way, CMR is enabled to adapt the preference weights according to the environment changes in an online manner, without retraining the models. Moreover, we classify practical business-oriented tasks into four main categories and seamlessly incorporate them in a new proposed re-ranking model based on an Actor-Evaluator framework, which serves as a reliable real-world testbed for CMR. Offline experiments based on the dataset collected from Taobao App showed that CMR improved several popular re-ranking models by using them as underlying models. Online A/B tests also demonstrated the effectiveness and trustworthiness of CMR.
Reinforcement Re-ranking with 2D Grid-based Recommendation Panels
Apr 11, 2022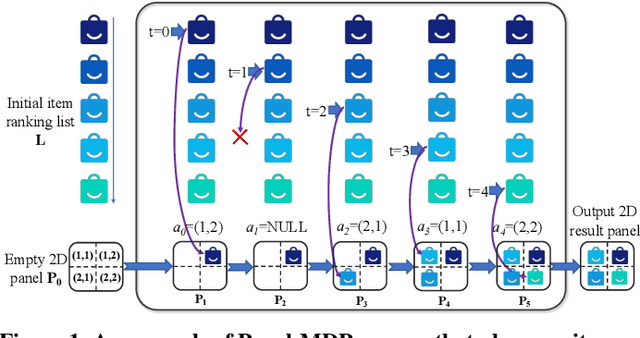

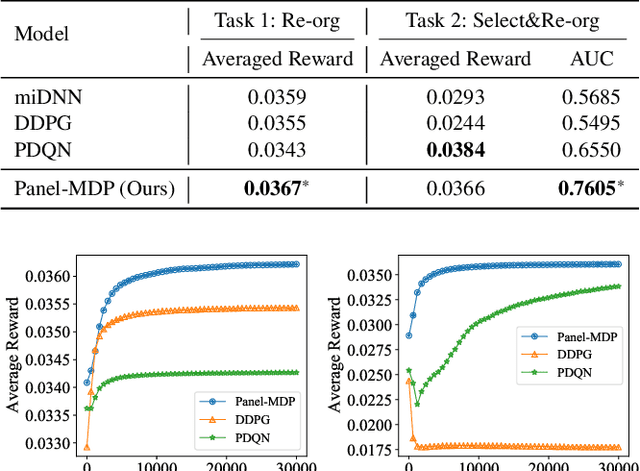
Modern recommender systems usually present items as one-dimensional ranking list. Recently there is a trend in e-commerce that the recommended items are organized as two-dimensional grid-based panels where users can view the items in both vertical and horizontal directions. Presenting items in grid-based result panels poses new challenges to recommender systems because existing models are all designed to output sequential lists while the slots in a grid-based panel have no explicit order. Directly converting the item rankings into grids (e.g., pre-defining an order on the slots)overlooks the user-specific behavioral patterns on grid-based pan-els and inevitably hurts the user experiences. To address this issue, we propose a novel Markov decision process (MDP) to place the items in 2D grid-based result panels at the final re-ranking stage of the recommender systems. The model, referred to as Panel-MDP, takes an initial item ranking from the early stages as the input. Then, it defines the MDP discrete time steps as the ranks in the initial ranking list, and the actions as the slots in the grid-based panels, plus a NULL action. At each time step, Panel-MDP sequentially takes an action of selecting one slot for placing an item of the initial ranking list, or discarding the item if NULL action is selected. The process is continued until all of the slots are filled. The reinforcement learning algorithm of DQN is employed to implement and learn the parameters in the Panel-MDP. Experiments on a dataset collected from a widely-used e-commerce app demonstrated the superiority ofPanel-MDP in terms of recommending 2D grid-based result panels.
A Causal Perspective to Unbiased Conversion Rate Estimation on Data Missing Not at Random
Oct 16, 2019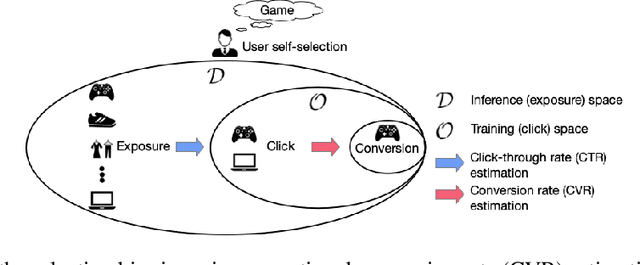
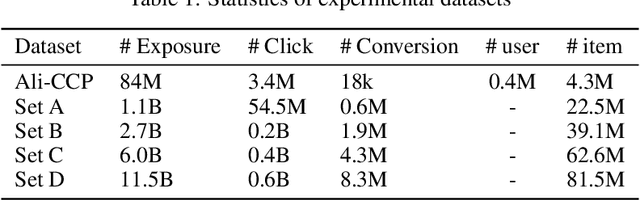
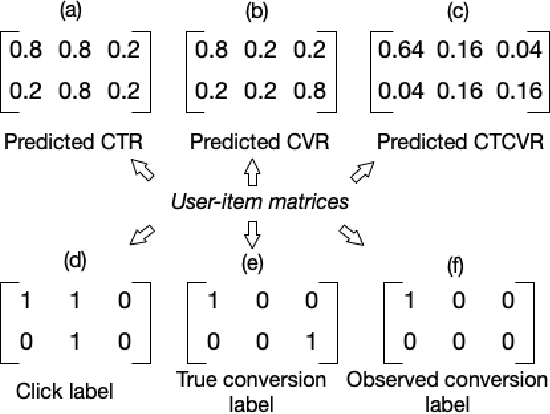
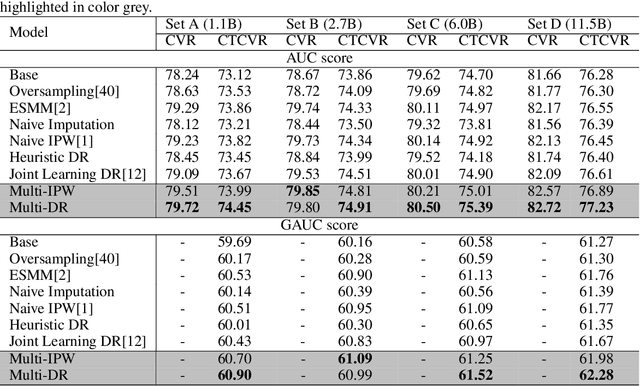
In modern e-commerce and advertising recommender systems, ongoing research works attempt to optimize conversion rate (CVR) estimation, and increase the gross merchandise volume. Even though the state-of-the-art CVR estimators adopt deep learning methods, their model performances are still subject to sample selection bias and data sparsity issues. Conversion labels of exposed items in training dataset are typically missing not at random due to selection bias. Empirically, data sparsity issue causes the performance degradation of model with large parameter space. In this paper, we proposed two causal estimators combined with multi-task learning, and aim to solve sample selection bias (SSB) and data sparsity (DS) issues in conversion rate estimation. The proposed estimators adjust for the MNAR mechanism as if they are trained on a "do dataset" where users are forced to click on all exposed items. We evaluate the causal estimators with billion data samples. Experiment results demonstrate that the proposed CVR estimators outperform other state-of-the-art CVR estimators. In addition, empirical study shows that our methods are cost-effective with large scale dataset.
Conversion Rate Prediction via Post-Click Behaviour Modeling
Oct 15, 2019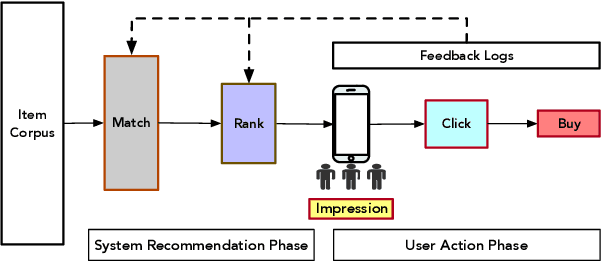
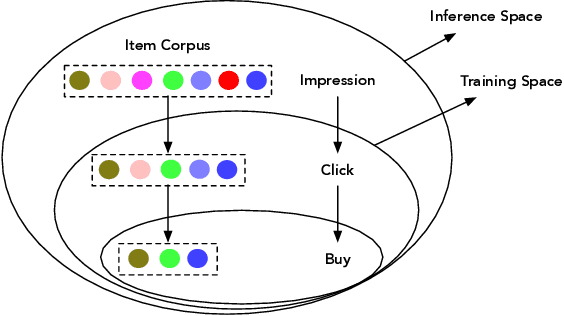

Effective and efficient recommendation is crucial for modern e-commerce platforms. It consists of two indispensable components named Click-Through Rate (CTR) prediction and Conversion Rate (CVR) prediction, where the latter is an essential factor contributing to the final purchasing volume. Existing methods specifically predict CVR using the clicked and purchased samples, which has limited performance affected by the well-known sample selection bias and data sparsity issues. To address these issues, we propose a novel deep CVR prediction method by considering the post-click behaviors. After grouping deterministic actions together, we construct a novel sequential path, which elaborately depicts the post-click behaviors of users. Based on the path, we define the CVR and several related probabilities including CTR, etc., and devise a deep neural network with multiple targets involved accordingly. It takes advantage of the abundant samples with deterministic labels derived from the post-click actions, leading to a significant improvement of CVR prediction. Extensive experiments on both offline and online settings demonstrate its superiority over representative state-of-the-art methods.
Multi-Level Deep Cascade Trees for Conversion Rate Prediction
Aug 29, 2018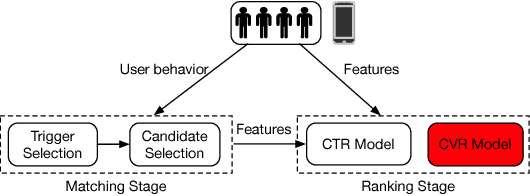

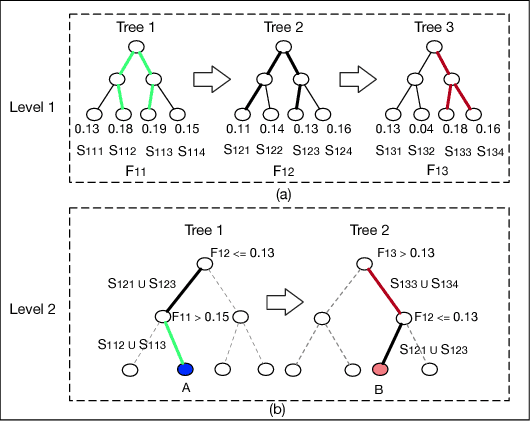

Developing effective and efficient recommendation methods is very challenging for modern e-commerce platforms (e.g., Taobao). In this paper, we tackle this problem by proposing multi-Level Deep Cascade Trees (ldcTree), which is a novel decision tree ensemble approach. It leverages deep cascade structures by stacking Gradient Boosting Decision Trees (GBDT) to effectively learn feature representation. In addition, we propose to utilize the cross-entropy in each tree of the preceding GBDT as the input feature representation for next level GBDT, which has a clear explanation, i.e., a traversal from root to leaf nodes in the next level GBDT corresponds to the combination of certain traversals in the preceding GBDT. The deep cascade structure and the combination rule enable the proposed ldcTree to have a stronger distributed feature representation ability. Moreover, we propose an ensemble ldcTree to take full use of weak and strong correlation features. Experimental results on off-line dataset and online deployment demonstrate the effectiveness of the proposed methods.