 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnconstrained Monotonic Calibration of Predictions in Deep Ranking Systems
Apr 19, 2025Ranking models primarily focus on modeling the relative order of predictions while often neglecting the significance of the accuracy of their absolute values. However, accurate absolute values are essential for certain downstream tasks, necessitating the calibration of the original predictions. To address this, existing calibration approaches typically employ predefined transformation functions with order-preserving properties to adjust the original predictions. Unfortunately, these functions often adhere to fixed forms, such as piece-wise linear functions, which exhibit limited expressiveness and flexibility, thereby constraining their effectiveness in complex calibration scenarios. To mitigate this issue, we propose implementing a calibrator using an Unconstrained Monotonic Neural Network (UMNN), which can learn arbitrary monotonic functions with great modeling power. This approach significantly relaxes the constraints on the calibrator, improving its flexibility and expressiveness while avoiding excessively distorting the original predictions by requiring monotonicity. Furthermore, to optimize this highly flexible network for calibration, we introduce a novel additional loss function termed Smooth Calibration Loss (SCLoss), which aims to fulfill a necessary condition for achieving the ideal calibration state. Extensive offline experiments confirm the effectiveness of our method in achieving superior calibration performance. Moreover, deployment in Kuaishou's large-scale online video ranking system demonstrates that the method's calibration improvements translate into enhanced business metrics. The source code is available at https://github.com/baiyimeng/UMC.
RecFlow: An Industrial Full Flow Recommendation Dataset
Oct 28, 2024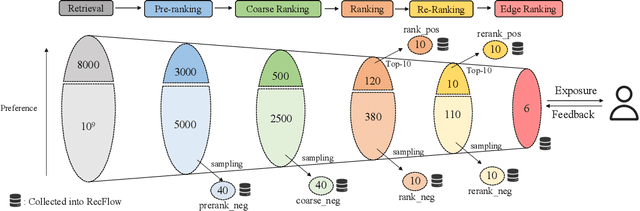
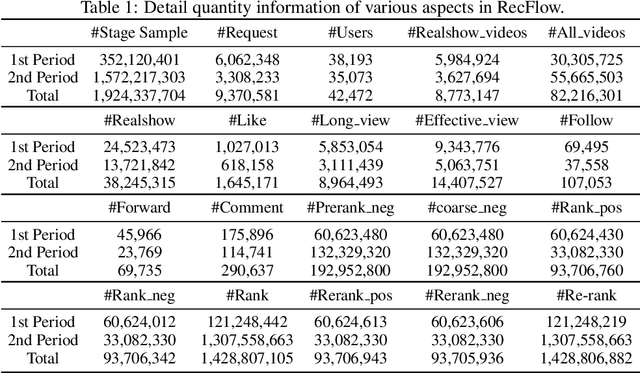

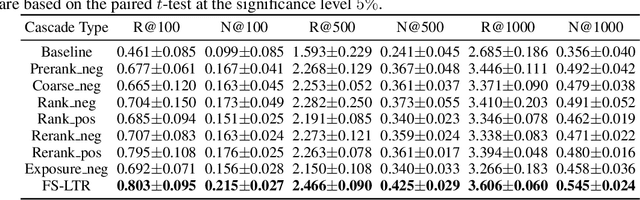
Industrial recommendation systems (RS) rely on the multi-stage pipeline to balance effectiveness and efficiency when delivering items from a vast corpus to users. Existing RS benchmark datasets primarily focus on the exposure space, where novel RS algorithms are trained and evaluated. However, when these algorithms transition to real world industrial RS, they face a critical challenge of handling unexposed items which are a significantly larger space than the exposed one. This discrepancy profoundly impacts their practical performance. Additionally, these algorithms often overlook the intricate interplay between multiple RS stages, resulting in suboptimal overall system performance. To address this issue, we introduce RecFlow, an industrial full flow recommendation dataset designed to bridge the gap between offline RS benchmarks and the real online environment. Unlike existing datasets, RecFlow includes samples not only from the exposure space but also unexposed items filtered at each stage of the RS funnel. Our dataset comprises 38M interactions from 42K users across nearly 9M items with additional 1.9B stage samples collected from 9.3M online requests over 37 days and spanning 6 stages. Leveraging the RecFlow dataset, we conduct courageous exploration experiments, showcasing its potential in designing new algorithms to enhance effectiveness by incorporating stage-specific samples. Some of these algorithms have already been deployed online, consistently yielding significant gains. We propose RecFlow as the first comprehensive benchmark dataset for the RS community, supporting research on designing algorithms at any stage, study of selection bias, debiased algorithms, multi-stage consistency and optimality, multi-task recommendation, and user behavior modeling. The RecFlow dataset, along with the corresponding source code, is available at https://github.com/RecFlow-ICLR/RecFlow.
Beyond Relevance: Improving User Engagement by Personalization for Short-Video Search
Sep 17, 2024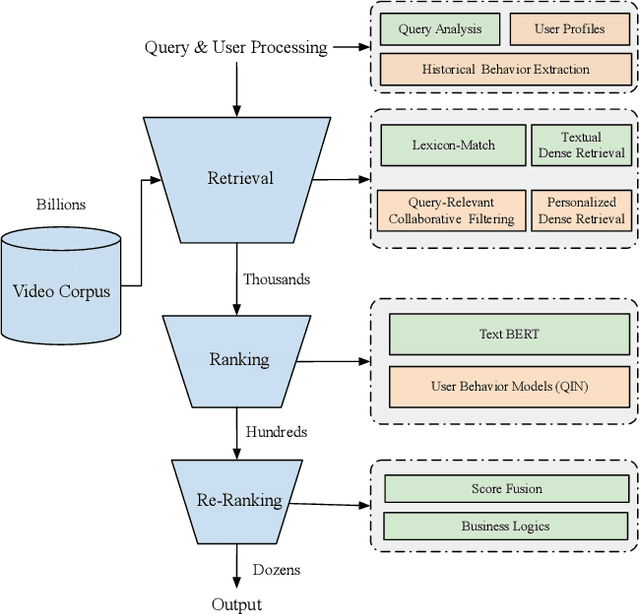
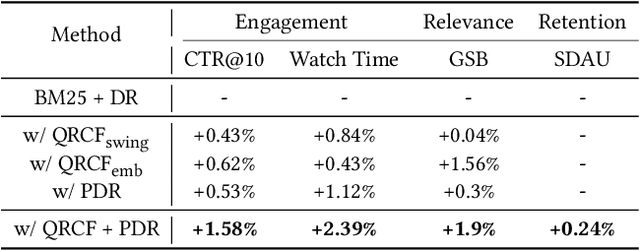
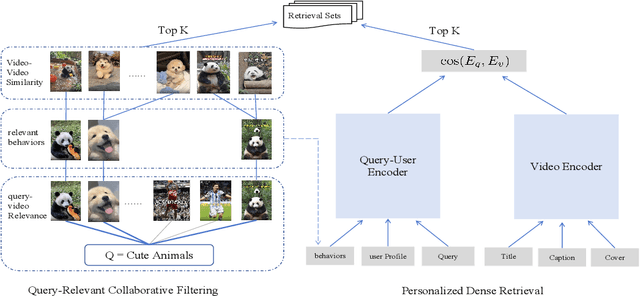
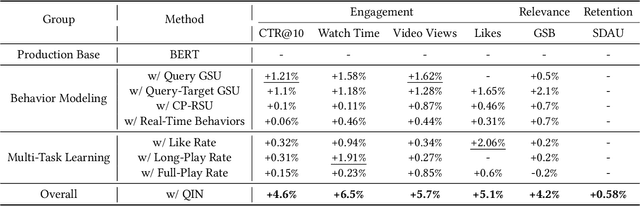
Personalized search has been extensively studied in various applications, including web search, e-commerce, social networks, etc. With the soaring popularity of short-video platforms, exemplified by TikTok and Kuaishou, the question arises: can personalization elevate the realm of short-video search, and if so, which techniques hold the key? In this work, we introduce $\text{PR}^2$, a novel and comprehensive solution for personalizing short-video search, where $\text{PR}^2$ stands for the Personalized Retrieval and Ranking augmented search system. Specifically, $\text{PR}^2$ leverages query-relevant collaborative filtering and personalized dense retrieval to extract relevant and individually tailored content from a large-scale video corpus. Furthermore, it utilizes the QIN (Query-Dominate User Interest Network) ranking model, to effectively harness user long-term preferences and real-time behaviors, and efficiently learn from user various implicit feedback through a multi-task learning framework. By deploying the $\text{PR}^2$ in production system, we have achieved the most remarkable user engagement improvements in recent years: a 10.2% increase in CTR@10, a notable 20% surge in video watch time, and a 1.6% uplift of search DAU. We believe the practical insights presented in this work are valuable especially for building and improving personalized search systems for the short video platforms.
DimeRec: A Unified Framework for Enhanced Sequential Recommendation via Generative Diffusion Models
Aug 22, 2024Sequential Recommendation (SR) plays a pivotal role in recommender systems by tailoring recommendations to user preferences based on their non-stationary historical interactions. Achieving high-quality performance in SR requires attention to both item representation and diversity. However, designing an SR method that simultaneously optimizes these merits remains a long-standing challenge. In this study, we address this issue by integrating recent generative Diffusion Models (DM) into SR. DM has demonstrated utility in representation learning and diverse image generation. Nevertheless, a straightforward combination of SR and DM leads to sub-optimal performance due to discrepancies in learning objectives (recommendation vs. noise reconstruction) and the respective learning spaces (non-stationary vs. stationary). To overcome this, we propose a novel framework called DimeRec (\textbf{Di}ffusion with \textbf{m}ulti-interest \textbf{e}nhanced \textbf{Rec}ommender). DimeRec synergistically combines a guidance extraction module (GEM) and a generative diffusion aggregation module (DAM). The GEM extracts crucial stationary guidance signals from the user's non-stationary interaction history, while the DAM employs a generative diffusion process conditioned on GEM's outputs to reconstruct and generate consistent recommendations. Our numerical experiments demonstrate that DimeRec significantly outperforms established baseline methods across three publicly available datasets. Furthermore, we have successfully deployed DimeRec on a large-scale short video recommendation platform, serving hundreds of millions of users. Live A/B testing confirms that our method improves both users' time spent and result diversification.
A Self-boosted Framework for Calibrated Ranking
Jun 12, 2024



Scale-calibrated ranking systems are ubiquitous in real-world applications nowadays, which pursue accurate ranking quality and calibrated probabilistic predictions simultaneously. For instance, in the advertising ranking system, the predicted click-through rate (CTR) is utilized for ranking and required to be calibrated for the downstream cost-per-click ads bidding. Recently, multi-objective based methods have been wildly adopted as a standard approach for Calibrated Ranking, which incorporates the combination of two loss functions: a pointwise loss that focuses on calibrated absolute values and a ranking loss that emphasizes relative orderings. However, when applied to industrial online applications, existing multi-objective CR approaches still suffer from two crucial limitations. First, previous methods need to aggregate the full candidate list within a single mini-batch to compute the ranking loss. Such aggregation strategy violates extensive data shuffling which has long been proven beneficial for preventing overfitting, and thus degrades the training effectiveness. Second, existing multi-objective methods apply the two inherently conflicting loss functions on a single probabilistic prediction, which results in a sub-optimal trade-off between calibration and ranking. To tackle the two limitations, we propose a Self-Boosted framework for Calibrated Ranking (SBCR).
Modeling Users' Contextualized Page-wise Feedback for Click-Through Rate Prediction in E-commerce Search
Mar 29, 2022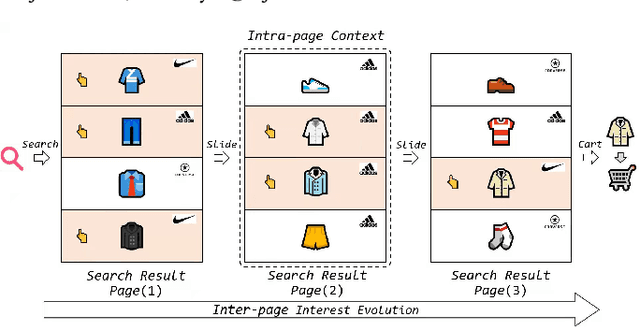

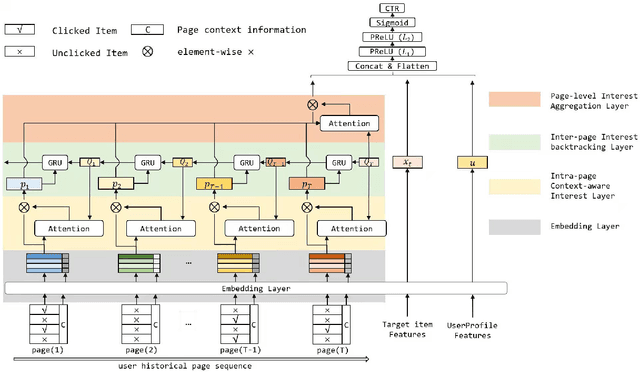
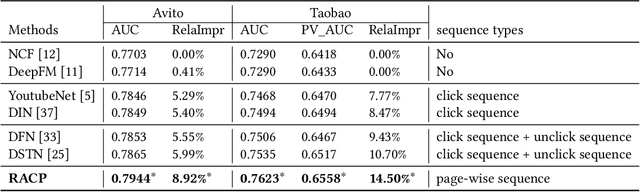
Modeling user's historical feedback is essential for Click-Through Rate Prediction in personalized search and recommendation. Existing methods usually only model users' positive feedback information such as click sequences which neglects the context information of the feedback. In this paper, we propose a new perspective for context-aware users' behavior modeling by including the whole page-wisely exposed products and the corresponding feedback as contextualized page-wise feedback sequence. The intra-page context information and inter-page interest evolution can be captured to learn more specific user preference. We design a novel neural ranking model RACP(i.e., Recurrent Attention over Contextualized Page sequence), which utilizes page-context aware attention to model the intra-page context. A recurrent attention process is used to model the cross-page interest convergence evolution as denoising the interest in the previous pages. Experiments on public and real-world industrial datasets verify our model's effectiveness.
Hierarchically Modeling Micro and Macro Behaviors via Multi-Task Learning for Conversion Rate Prediction
Apr 20, 2021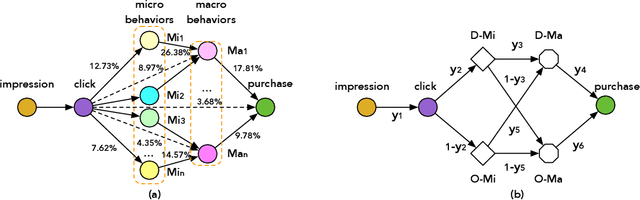

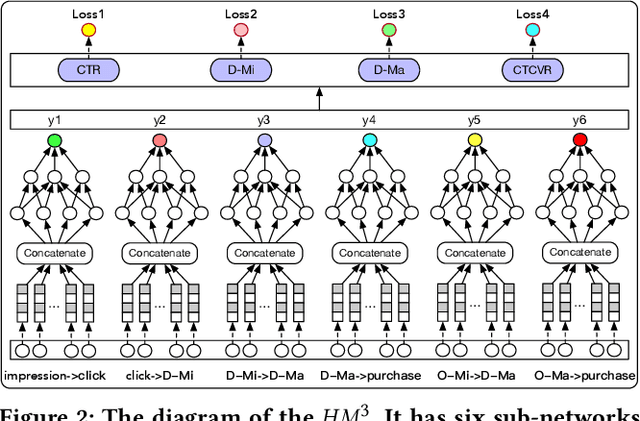
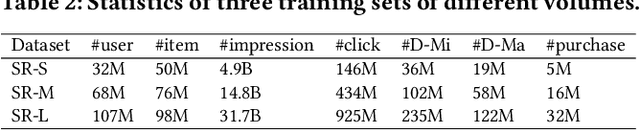
Conversion Rate (\emph{CVR}) prediction in modern industrial e-commerce platforms is becoming increasingly important, which directly contributes to the final revenue. In order to address the well-known sample selection bias (\emph{SSB}) and data sparsity (\emph{DS}) issues encountered during CVR modeling, the abundant labeled macro behaviors ($i.e.$, user's interactions with items) are used. Nonetheless, we observe that several purchase-related micro behaviors ($i.e.$, user's interactions with specific components on the item detail page) can supplement fine-grained cues for \emph{CVR} prediction. Motivated by this observation, we propose a novel \emph{CVR} prediction method by Hierarchically Modeling both Micro and Macro behaviors ($HM^3$). Specifically, we first construct a complete user sequential behavior graph to hierarchically represent micro behaviors and macro behaviors as one-hop and two-hop post-click nodes. Then, we embody $HM^3$ as a multi-head deep neural network, which predicts six probability variables corresponding to explicit sub-paths in the graph. They are further combined into the prediction targets of four auxiliary tasks as well as the final $CVR$ according to the conditional probability rule defined on the graph. By employing multi-task learning and leveraging the abundant supervisory labels from micro and macro behaviors, $HM^3$ can be trained end-to-end and address the \emph{SSB} and \emph{DS} issues. Extensive experiments on both offline and online settings demonstrate the superiority of the proposed $HM^3$ over representative state-of-the-art methods.
A Causal Perspective to Unbiased Conversion Rate Estimation on Data Missing Not at Random
Oct 16, 2019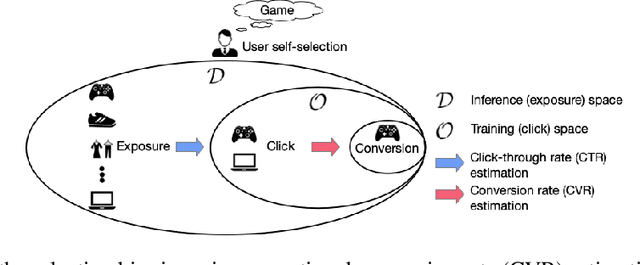
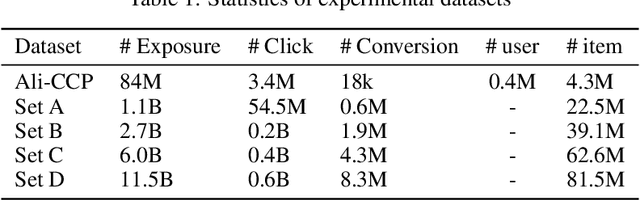
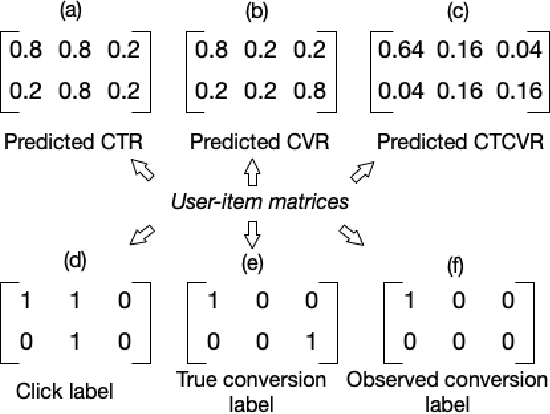
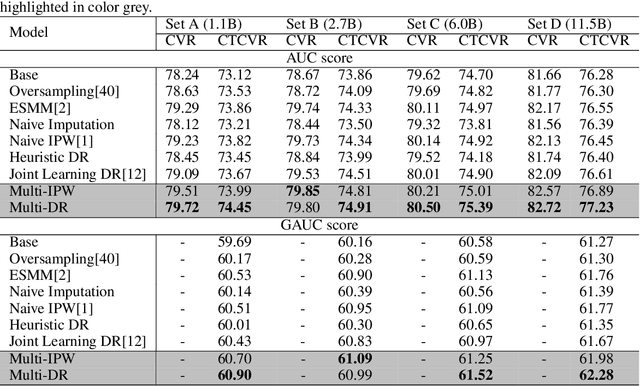
In modern e-commerce and advertising recommender systems, ongoing research works attempt to optimize conversion rate (CVR) estimation, and increase the gross merchandise volume. Even though the state-of-the-art CVR estimators adopt deep learning methods, their model performances are still subject to sample selection bias and data sparsity issues. Conversion labels of exposed items in training dataset are typically missing not at random due to selection bias. Empirically, data sparsity issue causes the performance degradation of model with large parameter space. In this paper, we proposed two causal estimators combined with multi-task learning, and aim to solve sample selection bias (SSB) and data sparsity (DS) issues in conversion rate estimation. The proposed estimators adjust for the MNAR mechanism as if they are trained on a "do dataset" where users are forced to click on all exposed items. We evaluate the causal estimators with billion data samples. Experiment results demonstrate that the proposed CVR estimators outperform other state-of-the-art CVR estimators. In addition, empirical study shows that our methods are cost-effective with large scale dataset.
Conversion Rate Prediction via Post-Click Behaviour Modeling
Oct 15, 2019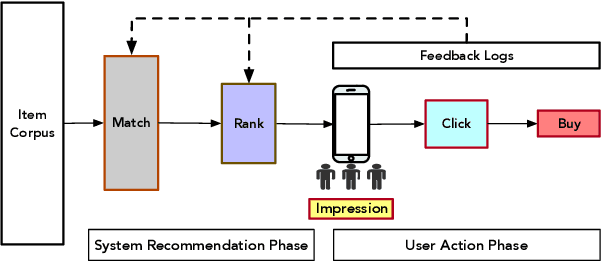
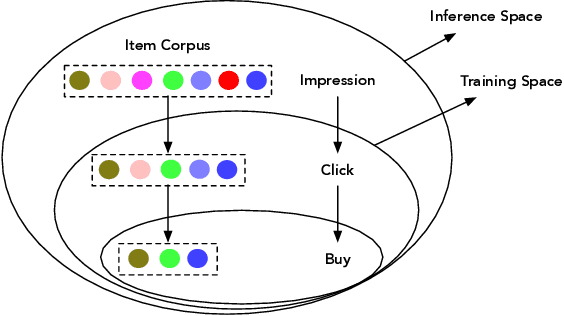

Effective and efficient recommendation is crucial for modern e-commerce platforms. It consists of two indispensable components named Click-Through Rate (CTR) prediction and Conversion Rate (CVR) prediction, where the latter is an essential factor contributing to the final purchasing volume. Existing methods specifically predict CVR using the clicked and purchased samples, which has limited performance affected by the well-known sample selection bias and data sparsity issues. To address these issues, we propose a novel deep CVR prediction method by considering the post-click behaviors. After grouping deterministic actions together, we construct a novel sequential path, which elaborately depicts the post-click behaviors of users. Based on the path, we define the CVR and several related probabilities including CTR, etc., and devise a deep neural network with multiple targets involved accordingly. It takes advantage of the abundant samples with deterministic labels derived from the post-click actions, leading to a significant improvement of CVR prediction. Extensive experiments on both offline and online settings demonstrate its superiority over representative state-of-the-art methods.