 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOrthogonal Uplift Learning with Permutation-Invariant Representations for Combinatorial Treatments
Feb 23, 2026We study uplift estimation for combinatorial treatments. Uplift measures the pure incremental causal effect of an intervention (e.g., sending a coupon or a marketing message) on user behavior, modeled as a conditional individual treatment effect. Many real-world interventions are combinatorial: a treatment is a policy that specifies context-dependent action distributions rather than a single atomic label. Although recent work considers structured treatments, most methods rely on categorical or opaque encodings, limiting robustness and generalization to rare or newly deployed policies. We propose an uplift estimation framework that aligns treatment representation with causal semantics. Each policy is represented by the mixture it induces over contextaction components and embedded via a permutation-invariant aggregation. This representation is integrated into an orthogonalized low-rank uplift model, extending Robinson-style decompositions to learned, vector-valued treatments. We show that the resulting estimator is expressive for policy-induced causal effects, orthogonally robust to nuisance estimation errors, and stable under small policy perturbations. Experiments on large-scale randomized platform data demonstrate improved uplift accuracy and stability in long-tailed policy regimes
CroPS: Improving Dense Retrieval with Cross-Perspective Positive Samples in Short-Video Search
Nov 19, 2025Dense retrieval has become a foundational paradigm in modern search systems, especially on short-video platforms. However, most industrial systems adopt a self-reinforcing training pipeline that relies on historically exposed user interactions for supervision. This paradigm inevitably leads to a filter bubble effect, where potentially relevant but previously unseen content is excluded from the training signal, biasing the model toward narrow and conservative retrieval. In this paper, we present CroPS (Cross-Perspective Positive Samples), a novel retrieval data engine designed to alleviate this problem by introducing diverse and semantically meaningful positive examples from multiple perspectives. CroPS enhances training with positive signals derived from user query reformulation behavior (query-level), engagement data in recommendation streams (system-level), and world knowledge synthesized by large language models (knowledge-level). To effectively utilize these heterogeneous signals, we introduce a Hierarchical Label Assignment (HLA) strategy and a corresponding H-InfoNCE loss that together enable fine-grained, relevance-aware optimization. Extensive experiments conducted on Kuaishou Search, a large-scale commercial short-video search platform, demonstrate that CroPS significantly outperforms strong baselines both offline and in live A/B tests, achieving superior retrieval performance and reducing query reformulation rates. CroPS is now fully deployed in Kuaishou Search, serving hundreds of millions of users daily.
Personalized Query Auto-Completion for Long and Short-Term Interests with Adaptive Detoxification Generation
May 27, 2025Query auto-completion (QAC) plays a crucial role in modern search systems. However, in real-world applications, there are two pressing challenges that still need to be addressed. First, there is a need for hierarchical personalized representations for users. Previous approaches have typically used users' search behavior as a single, overall representation, which proves inadequate in more nuanced generative scenarios. Additionally, query prefixes are typically short and may contain typos or sensitive information, increasing the likelihood of generating toxic content compared to traditional text generation tasks. Such toxic content can degrade user experience and lead to public relations issues. Therefore, the second critical challenge is detoxifying QAC systems. To address these two limitations, we propose a novel model (LaD) that captures personalized information from both long-term and short-term interests, incorporating adaptive detoxification. In LaD, personalized information is captured hierarchically at both coarse-grained and fine-grained levels. This approach preserves as much personalized information as possible while enabling online generation within time constraints. To move a futher step, we propose an online training method based on Reject Preference Optimization (RPO). By incorporating a special token [Reject] during both the training and inference processes, the model achieves adaptive detoxification. Consequently, the generated text presented to users is both non-toxic and relevant to the given prefix. We conduct comprehensive experiments on industrial-scale datasets and perform online A/B tests, delivering the largest single-experiment metric improvement in nearly two years of our product. Our model has been deployed on Kuaishou search, driving the primary traffic for hundreds of millions of active users. The code is available at https://github.com/JXZe/LaD.
Unconstrained Monotonic Calibration of Predictions in Deep Ranking Systems
Apr 19, 2025Ranking models primarily focus on modeling the relative order of predictions while often neglecting the significance of the accuracy of their absolute values. However, accurate absolute values are essential for certain downstream tasks, necessitating the calibration of the original predictions. To address this, existing calibration approaches typically employ predefined transformation functions with order-preserving properties to adjust the original predictions. Unfortunately, these functions often adhere to fixed forms, such as piece-wise linear functions, which exhibit limited expressiveness and flexibility, thereby constraining their effectiveness in complex calibration scenarios. To mitigate this issue, we propose implementing a calibrator using an Unconstrained Monotonic Neural Network (UMNN), which can learn arbitrary monotonic functions with great modeling power. This approach significantly relaxes the constraints on the calibrator, improving its flexibility and expressiveness while avoiding excessively distorting the original predictions by requiring monotonicity. Furthermore, to optimize this highly flexible network for calibration, we introduce a novel additional loss function termed Smooth Calibration Loss (SCLoss), which aims to fulfill a necessary condition for achieving the ideal calibration state. Extensive offline experiments confirm the effectiveness of our method in achieving superior calibration performance. Moreover, deployment in Kuaishou's large-scale online video ranking system demonstrates that the method's calibration improvements translate into enhanced business metrics. The source code is available at https://github.com/baiyimeng/UMC.
Unified Generative Search and Recommendation
Apr 10, 2025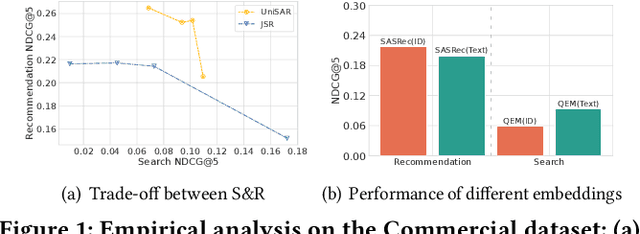
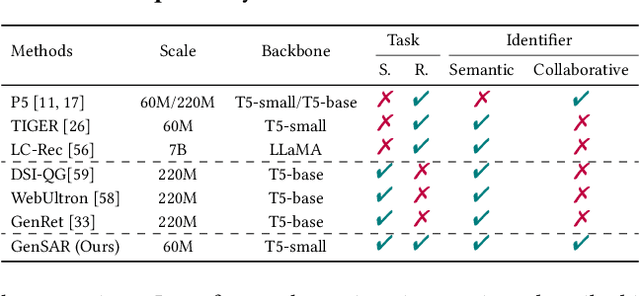
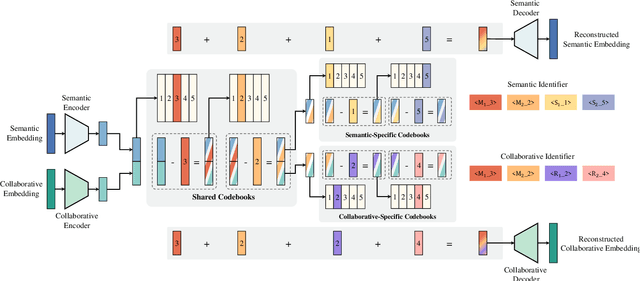

Modern commercial platforms typically offer both search and recommendation functionalities to serve diverse user needs, making joint modeling of these tasks an appealing direction. While prior work has shown that integrating search and recommendation can be mutually beneficial, it also reveals a performance trade-off: enhancements in one task often come at the expense of the other. This challenge arises from their distinct information requirements: search emphasizes semantic relevance between queries and items, whereas recommendation depends more on collaborative signals among users and items. Effectively addressing this trade-off requires tackling two key problems: (1) integrating both semantic and collaborative signals into item representations, and (2) guiding the model to distinguish and adapt to the unique demands of search and recommendation. The emergence of generative retrieval with Large Language Models (LLMs) presents new possibilities. This paradigm encodes items as identifiers and frames both search and recommendation as sequential generation tasks, offering the flexibility to leverage multiple identifiers and task-specific prompts. In light of this, we introduce GenSAR, a unified generative framework for balanced search and recommendation. Our approach designs dual-purpose identifiers and tailored training strategies to incorporate complementary signals and align with task-specific objectives. Experiments on both public and commercial datasets demonstrate that GenSAR effectively reduces the trade-off and achieves state-of-the-art performance on both tasks.
LLM4PR: Improving Post-Ranking in Search Engine with Large Language Models
Nov 02, 2024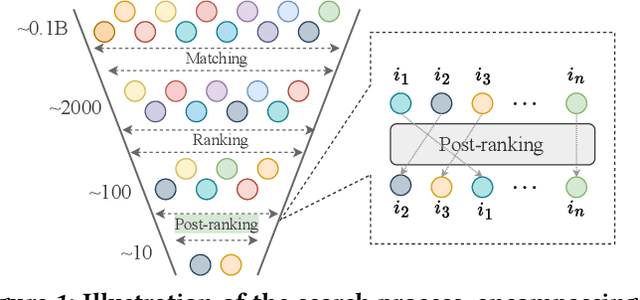



Alongside the rapid development of Large Language Models (LLMs), there has been a notable increase in efforts to integrate LLM techniques in information retrieval (IR) and search engines (SE). Recently, an additional post-ranking stage is suggested in SE to enhance user satisfaction in practical applications. Nevertheless, research dedicated to enhancing the post-ranking stage through LLMs remains largely unexplored. In this study, we introduce a novel paradigm named Large Language Models for Post-Ranking in search engine (LLM4PR), which leverages the capabilities of LLMs to accomplish the post-ranking task in SE. Concretely, a Query-Instructed Adapter (QIA) module is designed to derive the user/item representation vectors by incorporating their heterogeneous features. A feature adaptation step is further introduced to align the semantics of user/item representations with the LLM. Finally, the LLM4PR integrates a learning to post-rank step, leveraging both a main task and an auxiliary task to fine-tune the model to adapt the post-ranking task. Experiment studies demonstrate that the proposed framework leads to significant improvements and exhibits state-of-the-art performance compared with other alternatives.
Beyond Relevance: Improving User Engagement by Personalization for Short-Video Search
Sep 17, 2024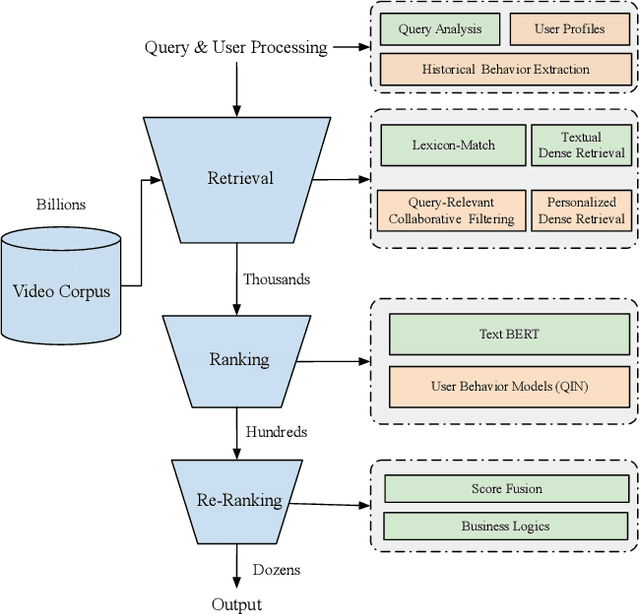
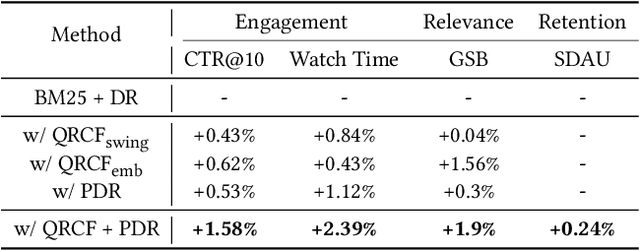
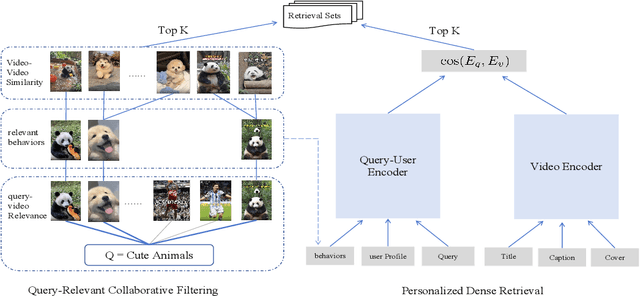
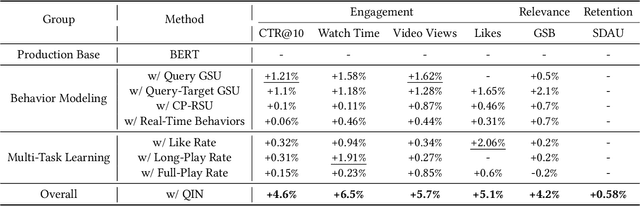
Personalized search has been extensively studied in various applications, including web search, e-commerce, social networks, etc. With the soaring popularity of short-video platforms, exemplified by TikTok and Kuaishou, the question arises: can personalization elevate the realm of short-video search, and if so, which techniques hold the key? In this work, we introduce $\text{PR}^2$, a novel and comprehensive solution for personalizing short-video search, where $\text{PR}^2$ stands for the Personalized Retrieval and Ranking augmented search system. Specifically, $\text{PR}^2$ leverages query-relevant collaborative filtering and personalized dense retrieval to extract relevant and individually tailored content from a large-scale video corpus. Furthermore, it utilizes the QIN (Query-Dominate User Interest Network) ranking model, to effectively harness user long-term preferences and real-time behaviors, and efficiently learn from user various implicit feedback through a multi-task learning framework. By deploying the $\text{PR}^2$ in production system, we have achieved the most remarkable user engagement improvements in recent years: a 10.2% increase in CTR@10, a notable 20% surge in video watch time, and a 1.6% uplift of search DAU. We believe the practical insights presented in this work are valuable especially for building and improving personalized search systems for the short video platforms.
DimeRec: A Unified Framework for Enhanced Sequential Recommendation via Generative Diffusion Models
Aug 22, 2024Sequential Recommendation (SR) plays a pivotal role in recommender systems by tailoring recommendations to user preferences based on their non-stationary historical interactions. Achieving high-quality performance in SR requires attention to both item representation and diversity. However, designing an SR method that simultaneously optimizes these merits remains a long-standing challenge. In this study, we address this issue by integrating recent generative Diffusion Models (DM) into SR. DM has demonstrated utility in representation learning and diverse image generation. Nevertheless, a straightforward combination of SR and DM leads to sub-optimal performance due to discrepancies in learning objectives (recommendation vs. noise reconstruction) and the respective learning spaces (non-stationary vs. stationary). To overcome this, we propose a novel framework called DimeRec (\textbf{Di}ffusion with \textbf{m}ulti-interest \textbf{e}nhanced \textbf{Rec}ommender). DimeRec synergistically combines a guidance extraction module (GEM) and a generative diffusion aggregation module (DAM). The GEM extracts crucial stationary guidance signals from the user's non-stationary interaction history, while the DAM employs a generative diffusion process conditioned on GEM's outputs to reconstruct and generate consistent recommendations. Our numerical experiments demonstrate that DimeRec significantly outperforms established baseline methods across three publicly available datasets. Furthermore, we have successfully deployed DimeRec on a large-scale short video recommendation platform, serving hundreds of millions of users. Live A/B testing confirms that our method improves both users' time spent and result diversification.
A Self-boosted Framework for Calibrated Ranking
Jun 12, 2024



Scale-calibrated ranking systems are ubiquitous in real-world applications nowadays, which pursue accurate ranking quality and calibrated probabilistic predictions simultaneously. For instance, in the advertising ranking system, the predicted click-through rate (CTR) is utilized for ranking and required to be calibrated for the downstream cost-per-click ads bidding. Recently, multi-objective based methods have been wildly adopted as a standard approach for Calibrated Ranking, which incorporates the combination of two loss functions: a pointwise loss that focuses on calibrated absolute values and a ranking loss that emphasizes relative orderings. However, when applied to industrial online applications, existing multi-objective CR approaches still suffer from two crucial limitations. First, previous methods need to aggregate the full candidate list within a single mini-batch to compute the ranking loss. Such aggregation strategy violates extensive data shuffling which has long been proven beneficial for preventing overfitting, and thus degrades the training effectiveness. Second, existing multi-objective methods apply the two inherently conflicting loss functions on a single probabilistic prediction, which results in a sub-optimal trade-off between calibration and ranking. To tackle the two limitations, we propose a Self-Boosted framework for Calibrated Ranking (SBCR).
CounterCLR: Counterfactual Contrastive Learning with Non-random Missing Data in Recommendation
Feb 08, 2024


Recommender systems are designed to learn user preferences from observed feedback and comprise many fundamental tasks, such as rating prediction and post-click conversion rate (pCVR) prediction. However, the observed feedback usually suffer from two issues: selection bias and data sparsity, where biased and insufficient feedback seriously degrade the performance of recommender systems in terms of accuracy and ranking. Existing solutions for handling the issues, such as data imputation and inverse propensity score, are highly susceptible to additional trained imputation or propensity models. In this work, we propose a novel counterfactual contrastive learning framework for recommendation, named CounterCLR, to tackle the problem of non-random missing data by exploiting the advances in contrast learning. Specifically, the proposed CounterCLR employs a deep representation network, called CauNet, to infer non-random missing data in recommendations and perform user preference modeling by further introducing a self-supervised contrastive learning task. Our CounterCLR mitigates the selection bias problem without the need for additional models or estimators, while also enhancing the generalization ability in cases of sparse data. Experiments on real-world datasets demonstrate the effectiveness and superiority of our method.