 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInEdit-Bench: Benchmarking Intermediate Logical Pathways for Intelligent Image Editing Models
Mar 04, 2026Multimodal generative models have made significant strides in image editing, demonstrating impressive performance on a variety of static tasks. However, their proficiency typically does not extend to complex scenarios requiring dynamic reasoning, leaving them ill-equipped to model the coherent, intermediate logical pathways that constitute a multi-step evolution from an initial state to a final one. This capacity is crucial for unlocking a deeper level of procedural and causal understanding in visual manipulation. To systematically measure this critical limitation, we introduce InEdit-Bench, the first evaluation benchmark dedicated to reasoning over intermediate pathways in image editing. InEdit-Bench comprises meticulously annotated test cases covering four fundamental task categories: state transition, dynamic process, temporal sequence, and scientific simulation. Additionally, to enable fine-grained evaluation, we propose a set of assessment criteria to evaluate the logical coherence and visual naturalness of the generated pathways, as well as the model's fidelity to specified path constraints. Our comprehensive evaluation of 14 representative image editing models on InEdit-Bench reveals significant and widespread shortcomings in this domain. By providing a standardized and challenging benchmark, we aim for InEdit-Bench to catalyze research and steer development towards more dynamic, reason-aware, and intelligent multimodal generative models.
Learning Vision-Driven Reactive Soccer Skills for Humanoid Robots
Nov 06, 2025Humanoid soccer poses a representative challenge for embodied intelligence, requiring robots to operate within a tightly coupled perception-action loop. However, existing systems typically rely on decoupled modules, resulting in delayed responses and incoherent behaviors in dynamic environments, while real-world perceptual limitations further exacerbate these issues. In this work, we present a unified reinforcement learning-based controller that enables humanoid robots to acquire reactive soccer skills through the direct integration of visual perception and motion control. Our approach extends Adversarial Motion Priors to perceptual settings in real-world dynamic environments, bridging motion imitation and visually grounded dynamic control. We introduce an encoder-decoder architecture combined with a virtual perception system that models real-world visual characteristics, allowing the policy to recover privileged states from imperfect observations and establish active coordination between perception and action. The resulting controller demonstrates strong reactivity, consistently executing coherent and robust soccer behaviors across various scenarios, including real RoboCup matches.
DIFNet: Decentralized Information Filtering Fusion Neural Network with Unknown Correlation in Sensor Measurement Noises
Aug 26, 2025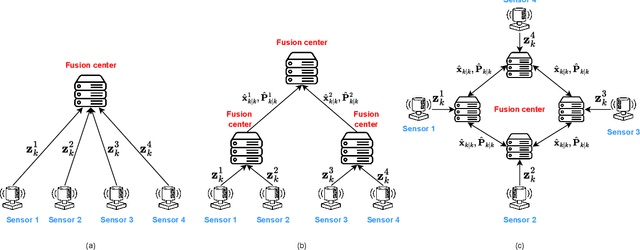
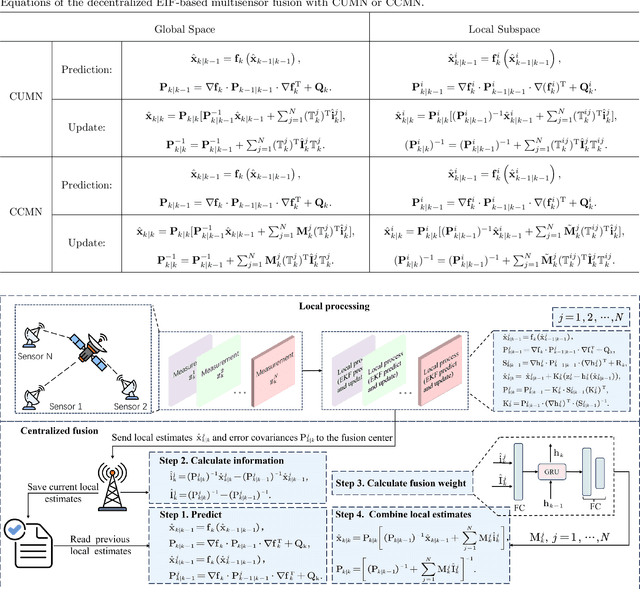
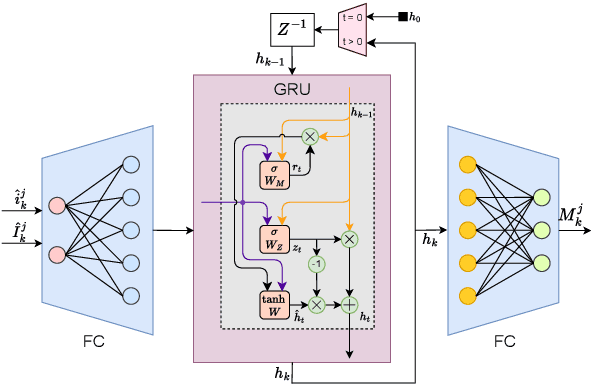
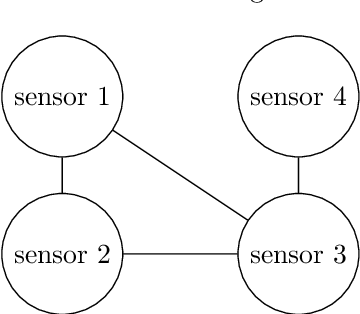
In recent years, decentralized sensor networks have garnered significant attention in the field of state estimation owing to enhanced robustness, scalability, and fault tolerance. Optimal fusion performance can be achieved under fully connected communication and known noise correlation structures. To mitigate communication overhead, the global state estimation problem is decomposed into local subproblems through structured observation model. This ensures that even when the communication network is not fully connected, each sensor can achieve locally optimal estimates of its observable state components. To address the degradation of fusion accuracy induced by unknown correlations in measurement noise, this paper proposes a data-driven method, termed Decentralized Information Filter Neural Network (DIFNet), to learn unknown noise correlations in data for discrete-time nonlinear state space models with cross-correlated measurement noises. Numerical simulations demonstrate that DIFNet achieves superior fusion performance compared to conventional filtering methods and exhibits robust characteristics in more complex scenarios, such as the presence of time-varying noise. The source code used in our numerical experiment can be found online at https://wisdom-estimation.github.io/DIFNet_Demonstrate/.
Cross-Block Fine-Grained Semantic Cascade for Skeleton-Based Sports Action Recognition
Apr 30, 2024Human action video recognition has recently attracted more attention in applications such as video security and sports posture correction. Popular solutions, including graph convolutional networks (GCNs) that model the human skeleton as a spatiotemporal graph, have proven very effective. GCNs-based methods with stacked blocks usually utilize top-layer semantics for classification/annotation purposes. Although the global features learned through the procedure are suitable for the general classification, they have difficulty capturing fine-grained action change across adjacent frames -- decisive factors in sports actions. In this paper, we propose a novel ``Cross-block Fine-grained Semantic Cascade (CFSC)'' module to overcome this challenge. In summary, the proposed CFSC progressively integrates shallow visual knowledge into high-level blocks to allow networks to focus on action details. In particular, the CFSC module utilizes the GCN feature maps produced at different levels, as well as aggregated features from proceeding levels to consolidate fine-grained features. In addition, a dedicated temporal convolution is applied at each level to learn short-term temporal features, which will be carried over from shallow to deep layers to maximize the leverage of low-level details. This cross-block feature aggregation methodology, capable of mitigating the loss of fine-grained information, has resulted in improved performance. Last, FD-7, a new action recognition dataset for fencing sports, was collected and will be made publicly available. Experimental results and empirical analysis on public benchmarks (FSD-10) and self-collected (FD-7) demonstrate the advantage of our CFSC module on learning discriminative patterns for action classification over others.
Query-dominant User Interest Network for Large-Scale Search Ranking
Oct 10, 2023



Historical behaviors have shown great effect and potential in various prediction tasks, including recommendation and information retrieval. The overall historical behaviors are various but noisy while search behaviors are always sparse. Most existing approaches in personalized search ranking adopt the sparse search behaviors to learn representation with bottleneck, which do not sufficiently exploit the crucial long-term interest. In fact, there is no doubt that user long-term interest is various but noisy for instant search, and how to exploit it well still remains an open problem. To tackle this problem, in this work, we propose a novel model named Query-dominant user Interest Network (QIN), including two cascade units to filter the raw user behaviors and reweigh the behavior subsequences. Specifically, we propose a relevance search unit (RSU), which aims to search a subsequence relevant to the query first and then search the sub-subsequences relevant to the target item. These items are then fed into an attention unit called Fused Attention Unit (FAU). It should be able to calculate attention scores from the ID field and attribute field separately, and then adaptively fuse the item embedding and content embedding based on the user engagement of past period. Extensive experiments and ablation studies on real-world datasets demonstrate the superiority of our model over state-of-the-art methods. The QIN now has been successfully deployed on Kuaishou search, an online video search platform, and obtained 7.6% improvement on CTR.
The Re-Label Method For Data-Centric Machine Learning
Feb 09, 2023In industry deep learning application, our manually labeled data has a certain number of noisy data. To solve this problem and achieve more than 90 score in dev dataset, we present a simple method to find the noisy data and re-label the noisy data by human, given the model predictions as references in human labeling. In this paper, we illustrate our idea for a broad set of deep learning tasks, includes classification, sequence tagging, object detection, sequence generation, click-through rate prediction. The experimental results and human evaluation results verify our idea.
A Comprehensive Exploration of Pre-training Language Models
Jun 22, 2021
Recently, the development of pre-trained language models has brought natural language processing (NLP) tasks to the new state-of-the-art. In this paper we explore the efficiency of various pre-trained language models. We pre-train a list of transformer-based models with the same amount of text and the same training steps. The experimental results shows that the most improvement upon the origin BERT is adding the RNN-layer to capture more contextual information for the transformer-encoder layers.
Learning From How Human Correct
Jan 30, 2021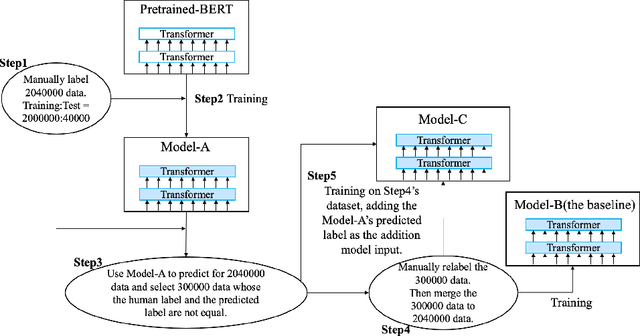

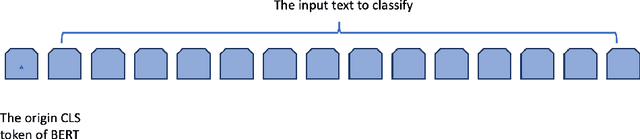
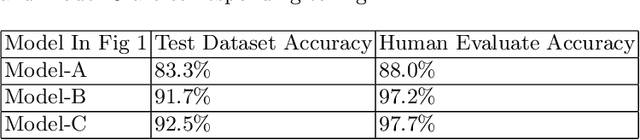
In industry NLP application, our manually labeled data has a certain number of noisy data. We present a simple method to find the noisy data and relabel them manually, meanwhile we collect the correction information. Then we present novel method to incorporate the human correction information into deep learning model. Human know how to correct noisy data. So the correction information can be inject into deep learning model. We do the experiment on our own text classification dataset, which is manually labeled, because we relabel the noisy data in our dataset for our industry application. The experiment result shows that our method improve the classification accuracy from 91.7% to 92.5%. The 91.7% baseline is based on BERT training on the corrected dataset, which is hard to surpass.
Predictions For Pre-training Language Models
Nov 18, 2020

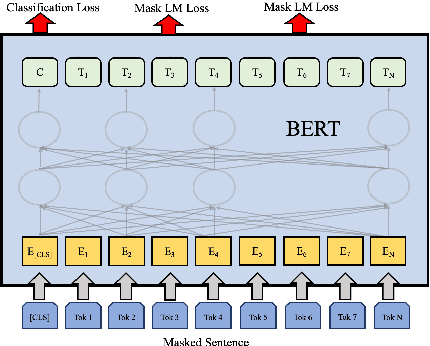

Language model pre-training has proven to be useful in many language understanding tasks. In this paper, we investigate whether it is still helpful to add the specific task's loss in pre-training step. In industry NLP applications, we have large amount of data produced by users. We use the fine-tuned model to give the user-generated unlabeled data a pseudo-label. Then we use the pseudo-label for the task-specific loss and masked language model loss to pre-train. The experiment shows that using the fine-tuned model's predictions for pseudo-labeled pre-training offers further gains in the downstream task. The improvement of our method is stable and remarkable.
Content Enhanced BERT-based Text-to-SQL Generation
Nov 27, 2019


We present a simple methods to leverage the table content for the BERT-based model to solve the text-to-SQL problem. Based on the observation that some of the table content match some words in question string and some of the table header also match some words in question string, we encode two addition feature vector for the deep model. Our methods also benefit the model inference in testing time as the tables are almost the same in training and testing time. We test our model on the WikiSQL dataset and outperform the BERT-based baseline by 3.7% in logic form and 3.7% in execution accuracy and achieve state-of-the-art.