 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMoE-nD: Per-Layer Mixture-of-Experts Routing for Multi-Axis KV Cache Compression
Apr 20, 2026KV cache memory is the dominant bottleneck for long-context LLM inference. Existing compression methods each act on a single axis of the four-dimensional KV tensor -- token eviction (sequence), quantization (precision), low-rank projection (head dimension), or cross-layer sharing -- but apply the same recipe to every layer. We show that this homogeneity leaves accuracy on the table: different layers respond very differently to each compression operation, and the optimal per-layer mix of eviction and quantization is far from uniform. We propose MoE-nD, a mixture-of-experts framework that routes each layer to its own (eviction-ratio, K-bits, V-bits) tuple under a global memory budget. An offline-calibrated greedy solver chooses the routing that minimizes predicted quality loss; at inference time, per-layer heterogeneous eviction and quantization are applied jointly through a single attention patch. On a 4-task subset of LongBench-v1 (16k inputs, n=50 per task, adapted reasoning-model protocol; see section Experiments), MoE-nD's hetero variant matches our uncompressed 1.9~GB baseline at 14x compression (136~MB) while every other compressed baseline we tested (1d, 2d_uniform, 2d) at comparable or smaller memory stays under 8/100. The gains hold on AIME reasoning benchmarks (+6 to +27 pts over the strongest per-layer-quantization baseline across eight configurations). Two null results -- MATH-500 and LongBench's TREC -- share a principled cause (short inputs, solver picks keep=1.0 on most layers), cleanly characterizing when per-layer eviction routing has headroom to help.
MAGNET: Towards Adaptive GUI Agents with Memory-Driven Knowledge Evolution
Jan 27, 2026Mobile GUI agents powered by large foundation models enable autonomous task execution, but frequent updates altering UI appearance and reorganizing workflows cause agents trained on historical data to fail. Despite surface changes, functional semantics and task intents remain fundamentally stable. Building on this insight, we introduce MAGNET, a memory-driven adaptive agent framework with dual-level memory: stationary memory linking diverse visual features to stable functional semantics for robust action grounding and procedural memory capturing stable task intents across varying workflows. We propose a dynamic memory evolution mechanism that continuously refines both memories by prioritizing frequently accessed knowledge. Online benchmark AndroidWorld evaluations show substantial improvements over baselines, while offline benchmarks confirm consistent gains under distribution shifts. These results validate that leveraging stable structures across interface changes improves agent performance and generalization in evolving software environments.
SocioVerse: A World Model for Social Simulation Powered by LLM Agents and A Pool of 10 Million Real-World Users
Apr 14, 2025


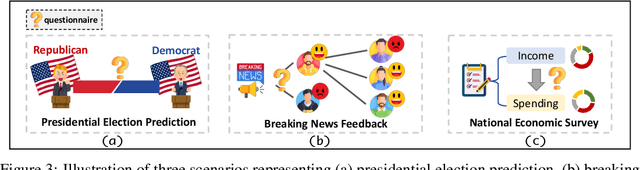
Social simulation is transforming traditional social science research by modeling human behavior through interactions between virtual individuals and their environments. With recent advances in large language models (LLMs), this approach has shown growing potential in capturing individual differences and predicting group behaviors. However, existing methods face alignment challenges related to the environment, target users, interaction mechanisms, and behavioral patterns. To this end, we introduce SocioVerse, an LLM-agent-driven world model for social simulation. Our framework features four powerful alignment components and a user pool of 10 million real individuals. To validate its effectiveness, we conducted large-scale simulation experiments across three distinct domains: politics, news, and economics. Results demonstrate that SocioVerse can reflect large-scale population dynamics while ensuring diversity, credibility, and representativeness through standardized procedures and minimal manual adjustments.
Enhancing Close-up Novel View Synthesis via Pseudo-labeling
Mar 20, 2025Recent methods, such as Neural Radiance Fields (NeRF) and 3D Gaussian Splatting (3DGS), have demonstrated remarkable capabilities in novel view synthesis. However, despite their success in producing high-quality images for viewpoints similar to those seen during training, they struggle when generating detailed images from viewpoints that significantly deviate from the training set, particularly in close-up views. The primary challenge stems from the lack of specific training data for close-up views, leading to the inability of current methods to render these views accurately. To address this issue, we introduce a novel pseudo-label-based learning strategy. This approach leverages pseudo-labels derived from existing training data to provide targeted supervision across a wide range of close-up viewpoints. Recognizing the absence of benchmarks for this specific challenge, we also present a new dataset designed to assess the effectiveness of both current and future methods in this area. Our extensive experiments demonstrate the efficacy of our approach.
From Individual to Society: A Survey on Social Simulation Driven by Large Language Model-based Agents
Dec 04, 2024



Traditional sociological research often relies on human participation, which, though effective, is expensive, challenging to scale, and with ethical concerns. Recent advancements in large language models (LLMs) highlight their potential to simulate human behavior, enabling the replication of individual responses and facilitating studies on many interdisciplinary studies. In this paper, we conduct a comprehensive survey of this field, illustrating the recent progress in simulation driven by LLM-empowered agents. We categorize the simulations into three types: (1) Individual Simulation, which mimics specific individuals or demographic groups; (2) Scenario Simulation, where multiple agents collaborate to achieve goals within specific contexts; and (3) Society Simulation, which models interactions within agent societies to reflect the complexity and variety of real-world dynamics. These simulations follow a progression, ranging from detailed individual modeling to large-scale societal phenomena. We provide a detailed discussion of each simulation type, including the architecture or key components of the simulation, the classification of objectives or scenarios and the evaluation method. Afterward, we summarize commonly used datasets and benchmarks. Finally, we discuss the trends across these three types of simulation. A repository for the related sources is at {\url{https://github.com/FudanDISC/SocialAgent}}.
ElectionSim: Massive Population Election Simulation Powered by Large Language Model Driven Agents
Oct 28, 2024



The massive population election simulation aims to model the preferences of specific groups in particular election scenarios. It has garnered significant attention for its potential to forecast real-world social trends. Traditional agent-based modeling (ABM) methods are constrained by their ability to incorporate complex individual background information and provide interactive prediction results. In this paper, we introduce ElectionSim, an innovative election simulation framework based on large language models, designed to support accurate voter simulations and customized distributions, together with an interactive platform to dialogue with simulated voters. We present a million-level voter pool sampled from social media platforms to support accurate individual simulation. We also introduce PPE, a poll-based presidential election benchmark to assess the performance of our framework under the U.S. presidential election scenario. Through extensive experiments and analyses, we demonstrate the effectiveness and robustness of our framework in U.S. presidential election simulations.
AI-Press: A Multi-Agent News Generating and Feedback Simulation System Powered by Large Language Models
Oct 10, 2024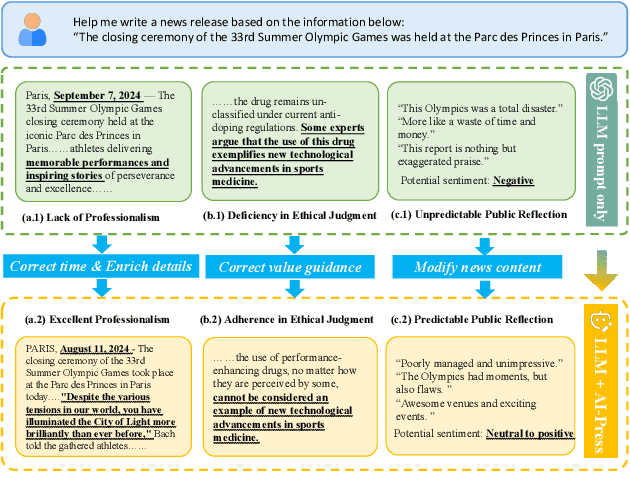
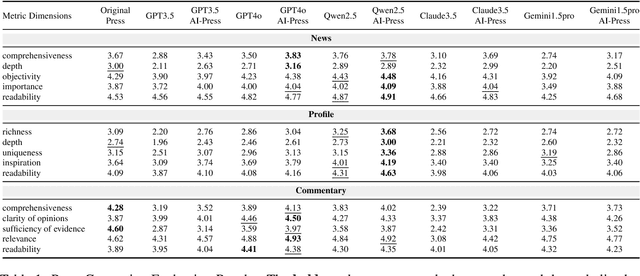
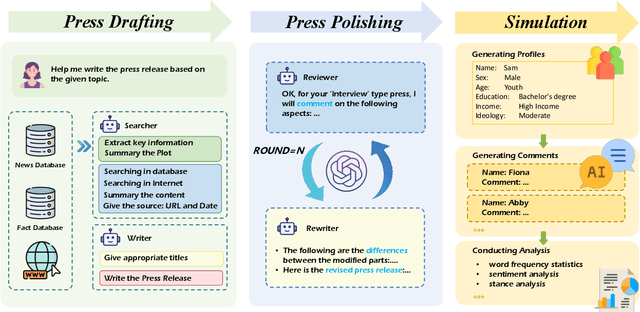
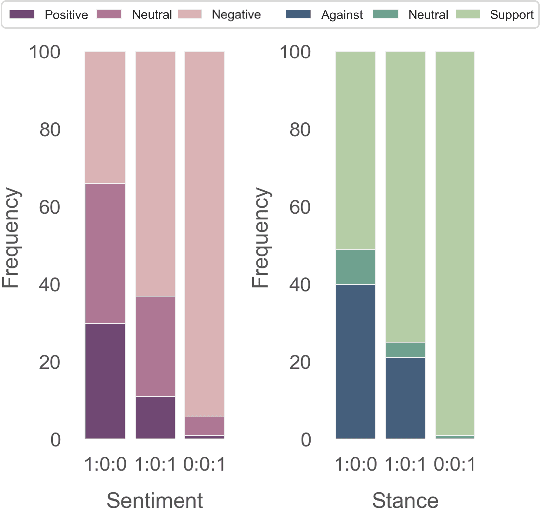
The rise of various social platforms has transformed journalism. The growing demand for news content has led to the increased use of large language models (LLMs) in news production due to their speed and cost-effectiveness. However, LLMs still encounter limitations in professionalism and ethical judgment in news generation. Additionally, predicting public feedback is usually difficult before news is released. To tackle these challenges, we introduce AI-Press, an automated news drafting and polishing system based on multi-agent collaboration and Retrieval-Augmented Generation. We develop a feedback simulation system that generates public feedback considering demographic distributions. Through extensive quantitative and qualitative evaluations, our system shows significant improvements in news-generating capabilities and verifies the effectiveness of public feedback simulation.
Identity-Driven Hierarchical Role-Playing Agents
Jul 28, 2024Utilizing large language models (LLMs) to achieve role-playing has gained great attention recently. The primary implementation methods include leveraging refined prompts and fine-tuning on role-specific datasets. However, these methods suffer from insufficient precision and limited flexibility respectively. To achieve a balance between flexibility and precision, we construct a Hierarchical Identity Role-Playing Framework (HIRPF) based on identity theory, constructing complex characters using multiple identity combinations. We develop an identity dialogue dataset for this framework and propose an evaluation benchmark including scale evaluation and open situation evaluation. Empirical results indicate the remarkable efficacy of our framework in modeling identity-level role simulation, and reveal its potential for application in social simulation.
GeoBench: Benchmarking and Analyzing Monocular Geometry Estimation Models
Jun 18, 2024



Recent advances in discriminative and generative pretraining have yielded geometry estimation models with strong generalization capabilities. While discriminative monocular geometry estimation methods rely on large-scale fine-tuning data to achieve zero-shot generalization, several generative-based paradigms show the potential of achieving impressive generalization performance on unseen scenes by leveraging pre-trained diffusion models and fine-tuning on even a small scale of synthetic training data. Frustratingly, these models are trained with different recipes on different datasets, making it hard to find out the critical factors that determine the evaluation performance. Besides, current geometry evaluation benchmarks have two main drawbacks that may prevent the development of the field, i.e., limited scene diversity and unfavorable label quality. To resolve the above issues, (1) we build fair and strong baselines in a unified codebase for evaluating and analyzing the geometry estimation models; (2) we evaluate monocular geometry estimators on more challenging benchmarks for geometry estimation task with diverse scenes and high-quality annotations. Our results reveal that pre-trained using large data, discriminative models such as DINOv2, can outperform generative counterparts with a small amount of high-quality synthetic data under the same training configuration, which suggests that fine-tuning data quality is a more important factor than the data scale and model architecture. Our observation also raises a question: if simply fine-tuning a general vision model such as DINOv2 using a small amount of synthetic depth data produces SOTA results, do we really need complex generative models for depth estimation? We believe this work can propel advancements in geometry estimation tasks as well as a wide range of downstream applications.
Cross-Block Fine-Grained Semantic Cascade for Skeleton-Based Sports Action Recognition
Apr 30, 2024Human action video recognition has recently attracted more attention in applications such as video security and sports posture correction. Popular solutions, including graph convolutional networks (GCNs) that model the human skeleton as a spatiotemporal graph, have proven very effective. GCNs-based methods with stacked blocks usually utilize top-layer semantics for classification/annotation purposes. Although the global features learned through the procedure are suitable for the general classification, they have difficulty capturing fine-grained action change across adjacent frames -- decisive factors in sports actions. In this paper, we propose a novel ``Cross-block Fine-grained Semantic Cascade (CFSC)'' module to overcome this challenge. In summary, the proposed CFSC progressively integrates shallow visual knowledge into high-level blocks to allow networks to focus on action details. In particular, the CFSC module utilizes the GCN feature maps produced at different levels, as well as aggregated features from proceeding levels to consolidate fine-grained features. In addition, a dedicated temporal convolution is applied at each level to learn short-term temporal features, which will be carried over from shallow to deep layers to maximize the leverage of low-level details. This cross-block feature aggregation methodology, capable of mitigating the loss of fine-grained information, has resulted in improved performance. Last, FD-7, a new action recognition dataset for fencing sports, was collected and will be made publicly available. Experimental results and empirical analysis on public benchmarks (FSD-10) and self-collected (FD-7) demonstrate the advantage of our CFSC module on learning discriminative patterns for action classification over others.