 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXChoice: Explainable Evaluation of AI-Human Alignment in LLM-based Constrained Choice Decision Making
Jan 16, 2026We present XChoice, an explainable framework for evaluating AI-human alignment in constrained decision making. Moving beyond outcome agreement such as accuracy and F1 score, XChoice fits a mechanism-based decision model to human data and LLM-generated decisions, recovering interpretable parameters that capture the relative importance of decision factors, constraint sensitivity, and implied trade-offs. Alignment is assessed by comparing these parameter vectors across models, options, and subgroups. We demonstrate XChoice on Americans' daily time allocation using the American Time Use Survey (ATUS) as human ground truth, revealing heterogeneous alignment across models and activities and salient misalignment concentrated in Black and married groups. We further validate robustness of XChoice via an invariance analysis and evaluate targeted mitigation with a retrieval augmented generation (RAG) intervention. Overall, XChoice provides mechanism-based metrics that diagnose misalignment and support informed improvements beyond surface outcome matching.
SocioVerse: A World Model for Social Simulation Powered by LLM Agents and A Pool of 10 Million Real-World Users
Apr 14, 2025


Social simulation is transforming traditional social science research by modeling human behavior through interactions between virtual individuals and their environments. With recent advances in large language models (LLMs), this approach has shown growing potential in capturing individual differences and predicting group behaviors. However, existing methods face alignment challenges related to the environment, target users, interaction mechanisms, and behavioral patterns. To this end, we introduce SocioVerse, an LLM-agent-driven world model for social simulation. Our framework features four powerful alignment components and a user pool of 10 million real individuals. To validate its effectiveness, we conducted large-scale simulation experiments across three distinct domains: politics, news, and economics. Results demonstrate that SocioVerse can reflect large-scale population dynamics while ensuring diversity, credibility, and representativeness through standardized procedures and minimal manual adjustments.
ElectionSim: Massive Population Election Simulation Powered by Large Language Model Driven Agents
Oct 28, 2024



The massive population election simulation aims to model the preferences of specific groups in particular election scenarios. It has garnered significant attention for its potential to forecast real-world social trends. Traditional agent-based modeling (ABM) methods are constrained by their ability to incorporate complex individual background information and provide interactive prediction results. In this paper, we introduce ElectionSim, an innovative election simulation framework based on large language models, designed to support accurate voter simulations and customized distributions, together with an interactive platform to dialogue with simulated voters. We present a million-level voter pool sampled from social media platforms to support accurate individual simulation. We also introduce PPE, a poll-based presidential election benchmark to assess the performance of our framework under the U.S. presidential election scenario. Through extensive experiments and analyses, we demonstrate the effectiveness and robustness of our framework in U.S. presidential election simulations.
Representation Bias in Political Sample Simulations with Large Language Models
Jul 16, 2024
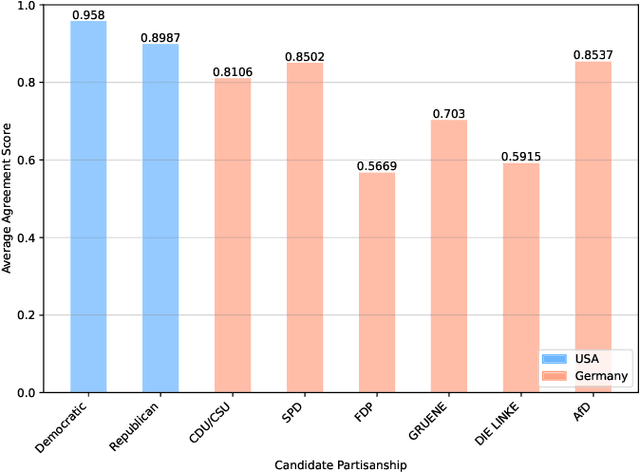
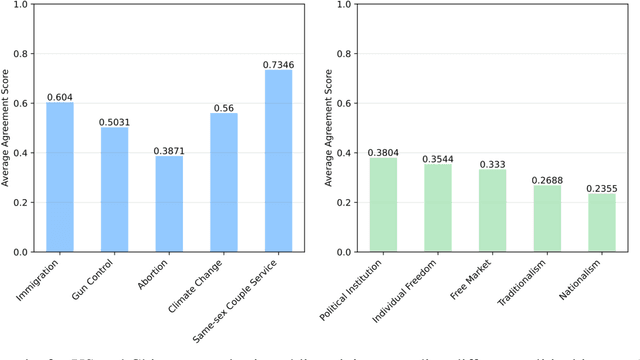
This study seeks to identify and quantify biases in simulating political samples with Large Language Models, specifically focusing on vote choice and public opinion. Using the GPT-3.5-Turbo model, we leverage data from the American National Election Studies, German Longitudinal Election Study, Zuobiao Dataset, and China Family Panel Studies to simulate voting behaviors and public opinions. This methodology enables us to examine three types of representation bias: disparities based on the the country's language, demographic groups, and political regime types. The findings reveal that simulation performance is generally better for vote choice than for public opinions, more accurate in English-speaking countries, more effective in bipartisan systems than in multi-partisan systems, and stronger in democratic settings than in authoritarian regimes. These results contribute to enhancing our understanding and developing strategies to mitigate biases in AI applications within the field of computational social science.
Human vs. LMMs: Exploring the Discrepancy in Emoji Interpretation and Usage in Digital Communication
Jan 16, 2024

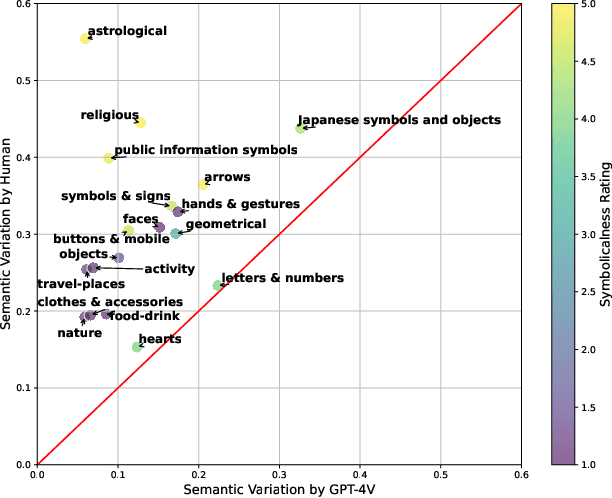

Leveraging Large Multimodal Models (LMMs) to simulate human behaviors when processing multimodal information, especially in the context of social media, has garnered immense interest due to its broad potential and far-reaching implications. Emojis, as one of the most unique aspects of digital communication, are pivotal in enriching and often clarifying the emotional and tonal dimensions. Yet, there is a notable gap in understanding how these advanced models, such as GPT-4V, interpret and employ emojis in the nuanced context of online interaction. This study intends to bridge this gap by examining the behavior of GPT-4V in replicating human-like use of emojis. The findings reveal a discernible discrepancy between human and GPT-4V behaviors, likely due to the subjective nature of human interpretation and the limitations of GPT-4V's English-centric training, suggesting cultural biases and inadequate representation of non-English cultures.
Beyond Sentiment: Leveraging Topic Metrics for Political Stance Classification
Oct 24, 2023Sentiment analysis, widely critiqued for capturing merely the overall tone of a corpus, falls short in accurately reflecting the latent structures and political stances within texts. This study introduces topic metrics, dummy variables converted from extracted topics, as both an alternative and complement to sentiment metrics in stance classification. By employing three datasets identified by Bestvater and Monroe (2023), this study demonstrates BERTopic's proficiency in extracting coherent topics and the effectiveness of topic metrics in stance classification. The experiment results show that BERTopic improves coherence scores by 17.07% to 54.20% when compared to traditional approaches such as Dirichlet Allocation (LDA) and Non-negative Matrix Factorization (NMF), prevalent in earlier political science research. Additionally, our results indicate topic metrics outperform sentiment metrics in stance classification, increasing performance by as much as 18.95%. Our findings suggest topic metrics are especially effective for context-rich texts and corpus where stance and sentiment correlations are weak. The combination of sentiment and topic metrics achieve an optimal performance in most of the scenarios and can further address the limitations of relying solely on sentiment as well as the low coherence score of topic metrics.
Understanding Divergent Framing of the Supreme Court Controversies: Social Media vs. News Outlets
Sep 18, 2023



Understanding the framing of political issues is of paramount importance as it significantly shapes how individuals perceive, interpret, and engage with these matters. While prior research has independently explored framing within news media and by social media users, there remains a notable gap in our comprehension of the disparities in framing political issues between these two distinct groups. To address this gap, we conduct a comprehensive investigation, focusing on the nuanced distinctions both qualitatively and quantitatively in the framing of social media and traditional media outlets concerning a series of American Supreme Court rulings on affirmative action, student loans, and abortion rights. Our findings reveal that, while some overlap in framing exists between social media and traditional media outlets, substantial differences emerge both across various topics and within specific framing categories. Compared to traditional news media, social media platforms tend to present more polarized stances across all framing categories. Further, we observe significant polarization in the news media's treatment (i.e., Left vs. Right leaning media) of affirmative action and abortion rights, whereas the topic of student loans tends to exhibit a greater degree of consensus. The disparities in framing between traditional and social media platforms carry significant implications for the formation of public opinion, policy decision-making, and the broader political landscape.
Bias or Diversity? Unraveling Semantic Discrepancy in U.S. News Headlines
Mar 28, 2023



There is a broad consensus that news media outlets incorporate ideological biases in their news articles. However, prior studies on measuring the discrepancies among media outlets and further dissecting the origins of semantic differences suffer from small sample sizes and limited scope. In this study, we collect a large dataset of 1.8 million news headlines from major U.S. media outlets spanning from 2014 to 2022 to thoroughly track and dissect the semantic discrepancy in U.S. news media. We employ multiple correspondence analysis (MCA) to quantify the semantic discrepancy relating to four prominent topics - domestic politics, economic issues, social issues, and foreign affairs. Additionally, we compare the most frequent n-grams in media headlines to provide further qualitative insights into our analysis. Our findings indicate that on domestic politics and social issues, the discrepancy can be attributed to a certain degree of media bias. Meanwhile, the discrepancy in reporting foreign affairs is largely attributed to the diversity in individual journalistic styles. Finally, U.S. media outlets show consistency and high similarity in their coverage of economic issues.