 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOET: Optimization-based prompt injection Evaluation Toolkit
May 01, 2025Large Language Models (LLMs) have demonstrated remarkable capabilities in natural language understanding and generation, enabling their widespread adoption across various domains. However, their susceptibility to prompt injection attacks poses significant security risks, as adversarial inputs can manipulate model behavior and override intended instructions. Despite numerous defense strategies, a standardized framework to rigorously evaluate their effectiveness, especially under adaptive adversarial scenarios, is lacking. To address this gap, we introduce OET, an optimization-based evaluation toolkit that systematically benchmarks prompt injection attacks and defenses across diverse datasets using an adaptive testing framework. Our toolkit features a modular workflow that facilitates adversarial string generation, dynamic attack execution, and comprehensive result analysis, offering a unified platform for assessing adversarial robustness. Crucially, the adaptive testing framework leverages optimization methods with both white-box and black-box access to generate worst-case adversarial examples, thereby enabling strict red-teaming evaluations. Extensive experiments underscore the limitations of current defense mechanisms, with some models remaining susceptible even after implementing security enhancements.
FATH: Authentication-based Test-time Defense against Indirect Prompt Injection Attacks
Oct 28, 2024



Large language models (LLMs) have been widely deployed as the backbone with additional tools and text information for real-world applications. However, integrating external information into LLM-integrated applications raises significant security concerns. Among these, prompt injection attacks are particularly threatening, where malicious instructions injected in the external text information can exploit LLMs to generate answers as the attackers desire. While both training-time and test-time defense methods have been developed to mitigate such attacks, the unaffordable training costs associated with training-time methods and the limited effectiveness of existing test-time methods make them impractical. This paper introduces a novel test-time defense strategy, named Formatting AuThentication with Hash-based tags (FATH). Unlike existing approaches that prevent LLMs from answering additional instructions in external text, our method implements an authentication system, requiring LLMs to answer all received instructions with a security policy and selectively filter out responses to user instructions as the final output. To achieve this, we utilize hash-based authentication tags to label each response, facilitating accurate identification of responses according to the user's instructions and improving the robustness against adaptive attacks. Comprehensive experiments demonstrate that our defense method can effectively defend against indirect prompt injection attacks, achieving state-of-the-art performance under Llama3 and GPT3.5 models across various attack methods. Our code is released at: https://github.com/Jayfeather1024/FATH
Evolver: Chain-of-Evolution Prompting to Boost Large Multimodal Models for Hateful Meme Detection
Jul 30, 2024



Recent advances show that two-stream approaches have achieved outstanding performance in hateful meme detection. However, hateful memes constantly evolve as new memes emerge by fusing progressive cultural ideas, making existing methods obsolete or ineffective. In this work, we explore the potential of Large Multimodal Models (LMMs) for hateful meme detection. To this end, we propose Evolver, which incorporates LMMs via Chain-of-Evolution (CoE) Prompting, by integrating the evolution attribute and in-context information of memes. Specifically, Evolver simulates the evolving and expressing process of memes and reasons through LMMs in a step-by-step manner. First, an evolutionary pair mining module retrieves the top-k most similar memes in the external curated meme set with the input meme. Second, an evolutionary information extractor is designed to summarize the semantic regularities between the paired memes for prompting. Finally, a contextual relevance amplifier enhances the in-context hatefulness information to boost the search for evolutionary processes. Extensive experiments on public FHM, MAMI, and HarM datasets show that CoE prompting can be incorporated into existing LMMs to improve their performance. More encouragingly, it can serve as an interpretive tool to promote the understanding of the evolution of social memes.
GPT-4V as A Social Media Analysis Engine
Nov 13, 2023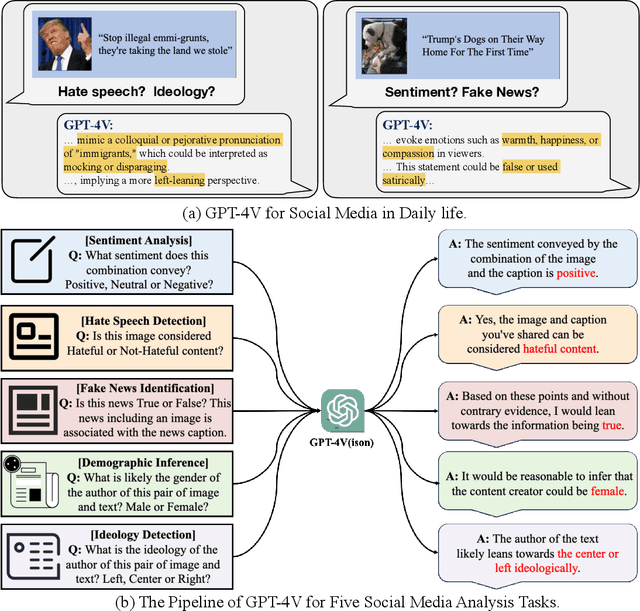

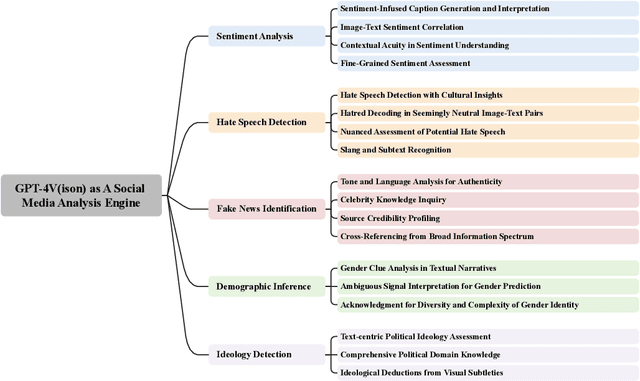
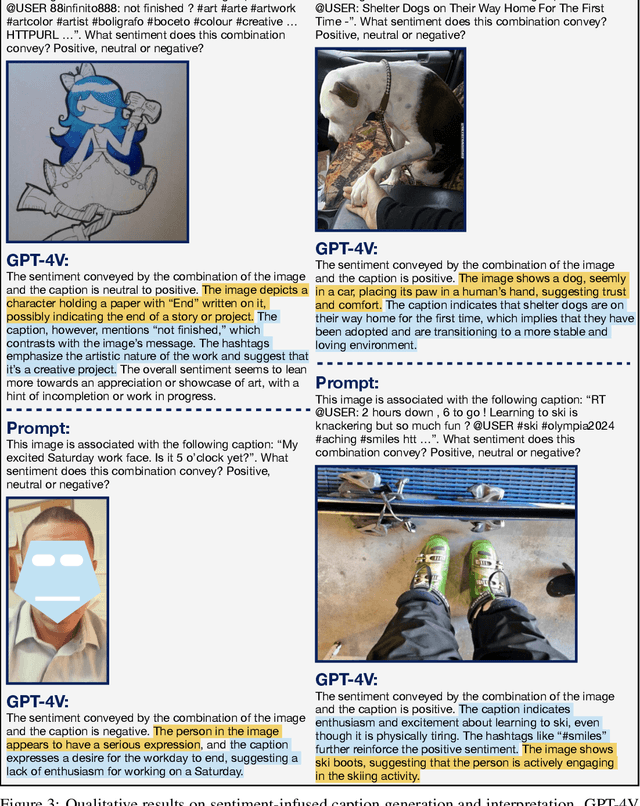
Recent research has offered insights into the extraordinary capabilities of Large Multimodal Models (LMMs) in various general vision and language tasks. There is growing interest in how LMMs perform in more specialized domains. Social media content, inherently multimodal, blends text, images, videos, and sometimes audio. Understanding social multimedia content remains a challenging problem for contemporary machine learning frameworks. In this paper, we explore GPT-4V(ision)'s capabilities for social multimedia analysis. We select five representative tasks, including sentiment analysis, hate speech detection, fake news identification, demographic inference, and political ideology detection, to evaluate GPT-4V. Our investigation begins with a preliminary quantitative analysis for each task using existing benchmark datasets, followed by a careful review of the results and a selection of qualitative samples that illustrate GPT-4V's potential in understanding multimodal social media content. GPT-4V demonstrates remarkable efficacy in these tasks, showcasing strengths such as joint understanding of image-text pairs, contextual and cultural awareness, and extensive commonsense knowledge. Despite the overall impressive capacity of GPT-4V in the social media domain, there remain notable challenges. GPT-4V struggles with tasks involving multilingual social multimedia comprehension and has difficulties in generalizing to the latest trends in social media. Additionally, it exhibits a tendency to generate erroneous information in the context of evolving celebrity and politician knowledge, reflecting the known hallucination problem. The insights gleaned from our findings underscore a promising future for LMMs in enhancing our comprehension of social media content and its users through the analysis of multimodal information.
Understanding Divergent Framing of the Supreme Court Controversies: Social Media vs. News Outlets
Sep 18, 2023



Understanding the framing of political issues is of paramount importance as it significantly shapes how individuals perceive, interpret, and engage with these matters. While prior research has independently explored framing within news media and by social media users, there remains a notable gap in our comprehension of the disparities in framing political issues between these two distinct groups. To address this gap, we conduct a comprehensive investigation, focusing on the nuanced distinctions both qualitatively and quantitatively in the framing of social media and traditional media outlets concerning a series of American Supreme Court rulings on affirmative action, student loans, and abortion rights. Our findings reveal that, while some overlap in framing exists between social media and traditional media outlets, substantial differences emerge both across various topics and within specific framing categories. Compared to traditional news media, social media platforms tend to present more polarized stances across all framing categories. Further, we observe significant polarization in the news media's treatment (i.e., Left vs. Right leaning media) of affirmative action and abortion rights, whereas the topic of student loans tends to exhibit a greater degree of consensus. The disparities in framing between traditional and social media platforms carry significant implications for the formation of public opinion, policy decision-making, and the broader political landscape.
NEOLAF, an LLM-powered neural-symbolic cognitive architecture
Aug 08, 2023This paper presents the Never Ending Open Learning Adaptive Framework (NEOLAF), an integrated neural-symbolic cognitive architecture that models and constructs intelligent agents. The NEOLAF framework is a superior approach to constructing intelligent agents than both the pure connectionist and pure symbolic approaches due to its explainability, incremental learning, efficiency, collaborative and distributed learning, human-in-the-loop enablement, and self-improvement. The paper further presents a compelling experiment where a NEOLAF agent, built as a problem-solving agent, is fed with complex math problems from the open-source MATH dataset. The results demonstrate NEOLAF's superior learning capability and its potential to revolutionize the field of cognitive architectures and self-improving adaptive instructional systems.
Bias or Diversity? Unraveling Semantic Discrepancy in U.S. News Headlines
Mar 28, 2023



There is a broad consensus that news media outlets incorporate ideological biases in their news articles. However, prior studies on measuring the discrepancies among media outlets and further dissecting the origins of semantic differences suffer from small sample sizes and limited scope. In this study, we collect a large dataset of 1.8 million news headlines from major U.S. media outlets spanning from 2014 to 2022 to thoroughly track and dissect the semantic discrepancy in U.S. news media. We employ multiple correspondence analysis (MCA) to quantify the semantic discrepancy relating to four prominent topics - domestic politics, economic issues, social issues, and foreign affairs. Additionally, we compare the most frequent n-grams in media headlines to provide further qualitative insights into our analysis. Our findings indicate that on domestic politics and social issues, the discrepancy can be attributed to a certain degree of media bias. Meanwhile, the discrepancy in reporting foreign affairs is largely attributed to the diversity in individual journalistic styles. Finally, U.S. media outlets show consistency and high similarity in their coverage of economic issues.
Computational Assessment of Hyperpartisanship in News Titles
Jan 16, 2023We first adopt a human-guided machine learning framework to develop a new dataset for hyperpartisan news title detection with 2,200 manually labeled and 1.8 million machine-labeled titles that were posted from 2014 to the present by nine representative media organizations across three media bias groups - Left, Central, and Right in an active learning manner. The fine-tuned transformer-based language model achieves an overall accuracy of 0.84 and an F1 score of 0.78 on an external validation set. Next, we conduct a computational analysis to quantify the extent and dynamics of partisanship in news titles. While some aspects are as expected, our study reveals new or nuanced differences between the three media groups. We find that overall the Right media tends to use proportionally more hyperpartisan titles. Roughly around the 2016 Presidential Election, the proportions of hyperpartisan titles increased in all media bias groups where the relative increase in the proportion of hyperpartisan titles of the Left media was the most. We identify three major topics including foreign issues, political systems, and societal issues that are suggestive of hyperpartisanship in news titles using logistic regression models and the Shapley values. Through an analysis of the topic distribution, we find that societal issues gradually receive more attention from all media groups. We further apply a lexicon-based language analysis tool to the titles of each topic and quantify the linguistic distance between any pairs of the three media groups. Three distinct patterns are discovered. The Left media is linguistically more different from Central and Right in terms of foreign issues. The linguistic distance between the three media groups becomes smaller over recent years. In addition, a seasonal pattern where linguistic difference is associated with elections is observed for societal issues.