 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynaGraph: Lightweight Multi-Model Interaction Framework via Dynamic Topological Reconfiguration
May 28, 2026Tackling complex reasoning tasks typically relies on massive monolithic LLMs, which suffer from severe computational redundancy. While task decomposition through structured pipelines or multi-agent collaborations offers an alternative, these approaches inevitably fall into a critical dilemma: predefined static topologies are highly vulnerable to cascading errors, whereas unconstrained dynamic agents suffer from trajectory divergence and unpredictable memory bloat. To address this, we present DynaGraph, a lightweight multi-model framework driven by dynamic topological reconfiguration. At the execution level, DynaGraph multiplexes time-division PEFT adapters over a shared base model, enabling both full system training and inference deployment on a single consumer-grade GPU. At the routing level, the Evaluator continuously monitors execution confidence to trigger hierarchical self-healing: Fine-grained Patching for localized data gaps and Subgraph Reconstruction for severe logical ruptures. Experiments on StrategyQA, MATH, and FinQA demonstrate our 8B model closely approximates the reasoning capabilities of a 72B monolithic model (e.g., 87.6% on StrategyQA, 82.7% on MATH). Furthermore, it reduces latency by up to 68.1% and token consumption by 68.6% compared to unconstrained dynamic architectures.
Randomization Boosts KV Caching, Learning Balances Query Load: A Joint Perspective
Jan 26, 2026KV caching is a fundamental technique for accelerating Large Language Model (LLM) inference by reusing key-value (KV) pairs from previous queries, but its effectiveness under limited memory is highly sensitive to the eviction policy. The default Least Recently Used (LRU) eviction algorithm struggles with dynamic online query arrivals, especially in multi-LLM serving scenarios, where balancing query load across workers and maximizing cache hit rate of each worker are inherently conflicting objectives. We give the first unified mathematical model that captures the core trade-offs between KV cache eviction and query routing. Our analysis reveals the theoretical limitations of existing methods and leads to principled algorithms that integrate provably competitive randomized KV cache eviction with learning-based methods to adaptively route queries with evolving patterns, thus balancing query load and cache hit rate. Our theoretical results are validated by extensive experiments across 4 benchmarks and 3 prefix-sharing settings, demonstrating improvements of up to 6.92$\times$ in cache hit rate, 11.96$\times$ reduction in latency, 14.06$\times$ reduction in time-to-first-token (TTFT), and 77.4% increase in throughput over the state-of-the-art methods. Our code is available at https://github.com/fzwark/KVRouting.
FATH: Authentication-based Test-time Defense against Indirect Prompt Injection Attacks
Oct 28, 2024



Large language models (LLMs) have been widely deployed as the backbone with additional tools and text information for real-world applications. However, integrating external information into LLM-integrated applications raises significant security concerns. Among these, prompt injection attacks are particularly threatening, where malicious instructions injected in the external text information can exploit LLMs to generate answers as the attackers desire. While both training-time and test-time defense methods have been developed to mitigate such attacks, the unaffordable training costs associated with training-time methods and the limited effectiveness of existing test-time methods make them impractical. This paper introduces a novel test-time defense strategy, named Formatting AuThentication with Hash-based tags (FATH). Unlike existing approaches that prevent LLMs from answering additional instructions in external text, our method implements an authentication system, requiring LLMs to answer all received instructions with a security policy and selectively filter out responses to user instructions as the final output. To achieve this, we utilize hash-based authentication tags to label each response, facilitating accurate identification of responses according to the user's instructions and improving the robustness against adaptive attacks. Comprehensive experiments demonstrate that our defense method can effectively defend against indirect prompt injection attacks, achieving state-of-the-art performance under Llama3 and GPT3.5 models across various attack methods. Our code is released at: https://github.com/Jayfeather1024/FATH
A New Era in LLM Security: Exploring Security Concerns in Real-World LLM-based Systems
Feb 28, 2024



Large Language Model (LLM) systems are inherently compositional, with individual LLM serving as the core foundation with additional layers of objects such as plugins, sandbox, and so on. Along with the great potential, there are also increasing concerns over the security of such probabilistic intelligent systems. However, existing studies on LLM security often focus on individual LLM, but without examining the ecosystem through the lens of LLM systems with other objects (e.g., Frontend, Webtool, Sandbox, and so on). In this paper, we systematically analyze the security of LLM systems, instead of focusing on the individual LLMs. To do so, we build on top of the information flow and formulate the security of LLM systems as constraints on the alignment of the information flow within LLM and between LLM and other objects. Based on this construction and the unique probabilistic nature of LLM, the attack surface of the LLM system can be decomposed into three key components: (1) multi-layer security analysis, (2) analysis of the existence of constraints, and (3) analysis of the robustness of these constraints. To ground this new attack surface, we propose a multi-layer and multi-step approach and apply it to the state-of-art LLM system, OpenAI GPT4. Our investigation exposes several security issues, not just within the LLM model itself but also in its integration with other components. We found that although the OpenAI GPT4 has designed numerous safety constraints to improve its safety features, these safety constraints are still vulnerable to attackers. To further demonstrate the real-world threats of our discovered vulnerabilities, we construct an end-to-end attack where an adversary can illicitly acquire the user's chat history, all without the need to manipulate the user's input or gain direct access to OpenAI GPT4. Our demo is in the link: https://fzwark.github.io/LLM-System-Attack-Demo/
WIPI: A New Web Threat for LLM-Driven Web Agents
Feb 26, 2024



With the fast development of large language models (LLMs), LLM-driven Web Agents (Web Agents for short) have obtained tons of attention due to their superior capability where LLMs serve as the core part of making decisions like the human brain equipped with multiple web tools to actively interact with external deployed websites. As uncountable Web Agents have been released and such LLM systems are experiencing rapid development and drawing closer to widespread deployment in our daily lives, an essential and pressing question arises: "Are these Web Agents secure?". In this paper, we introduce a novel threat, WIPI, that indirectly controls Web Agent to execute malicious instructions embedded in publicly accessible webpages. To launch a successful WIPI works in a black-box environment. This methodology focuses on the form and content of indirect instructions within external webpages, enhancing the efficiency and stealthiness of the attack. To evaluate the effectiveness of the proposed methodology, we conducted extensive experiments using 7 plugin-based ChatGPT Web Agents, 8 Web GPTs, and 3 different open-source Web Agents. The results reveal that our methodology achieves an average attack success rate (ASR) exceeding 90% even in pure black-box scenarios. Moreover, through an ablation study examining various user prefix instructions, we demonstrated that the WIPI exhibits strong robustness, maintaining high performance across diverse prefix instructions.
DeceptPrompt: Exploiting LLM-driven Code Generation via Adversarial Natural Language Instructions
Dec 12, 2023



With the advancement of Large Language Models (LLMs), significant progress has been made in code generation, enabling LLMs to transform natural language into programming code. These Code LLMs have been widely accepted by massive users and organizations. However, a dangerous nature is hidden in the code, which is the existence of fatal vulnerabilities. While some LLM providers have attempted to address these issues by aligning with human guidance, these efforts fall short of making Code LLMs practical and robust. Without a deep understanding of the performance of the LLMs under the practical worst cases, it would be concerning to apply them to various real-world applications. In this paper, we answer the critical issue: Are existing Code LLMs immune to generating vulnerable code? If not, what is the possible maximum severity of this issue in practical deployment scenarios? In this paper, we introduce DeceptPrompt, a novel algorithm that can generate adversarial natural language instructions that drive the Code LLMs to generate functionality correct code with vulnerabilities. DeceptPrompt is achieved through a systematic evolution-based algorithm with a fine grain loss design. The unique advantage of DeceptPrompt enables us to find natural prefix/suffix with totally benign and non-directional semantic meaning, meanwhile, having great power in inducing the Code LLMs to generate vulnerable code. This feature can enable us to conduct the almost-worstcase red-teaming on these LLMs in a real scenario, where users are using natural language. Our extensive experiments and analyses on DeceptPrompt not only validate the effectiveness of our approach but also shed light on the huge weakness of LLMs in the code generation task. When applying the optimized prefix/suffix, the attack success rate (ASR) will improve by average 50% compared with no prefix/suffix applying.
Exploring the Limits of ChatGPT in Software Security Applications
Dec 08, 2023



Large language models (LLMs) have undergone rapid evolution and achieved remarkable results in recent times. OpenAI's ChatGPT, backed by GPT-3.5 or GPT-4, has gained instant popularity due to its strong capability across a wide range of tasks, including natural language tasks, coding, mathematics, and engaging conversations. However, the impacts and limits of such LLMs in system security domain are less explored. In this paper, we delve into the limits of LLMs (i.e., ChatGPT) in seven software security applications including vulnerability detection/repair, debugging, debloating, decompilation, patching, root cause analysis, symbolic execution, and fuzzing. Our exploration reveals that ChatGPT not only excels at generating code, which is the conventional application of language models, but also demonstrates strong capability in understanding user-provided commands in natural languages, reasoning about control and data flows within programs, generating complex data structures, and even decompiling assembly code. Notably, GPT-4 showcases significant improvements over GPT-3.5 in most security tasks. Also, certain limitations of ChatGPT in security-related tasks are identified, such as its constrained ability to process long code contexts.
Towards Efficient Data-Centric Robust Machine Learning with Noise-based Augmentation
Mar 08, 2022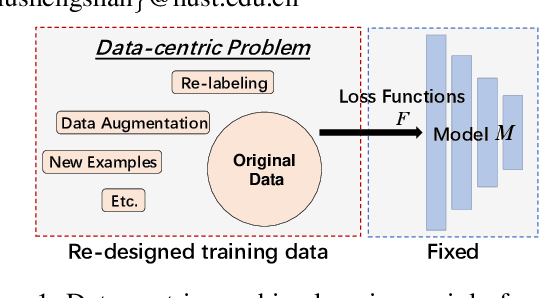

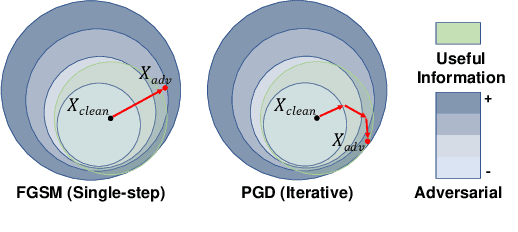
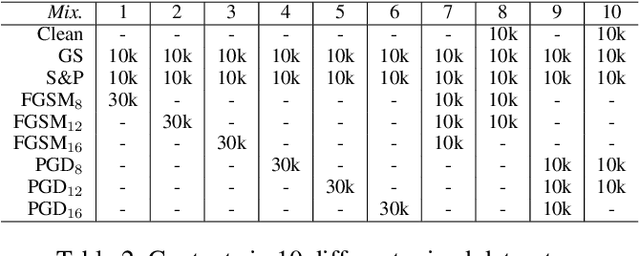
The data-centric machine learning aims to find effective ways to build appropriate datasets which can improve the performance of AI models. In this paper, we mainly focus on designing an efficient data-centric scheme to improve robustness for models towards unforeseen malicious inputs in the black-box test settings. Specifically, we introduce a noised-based data augmentation method which is composed of Gaussian Noise, Salt-and-Pepper noise, and the PGD adversarial perturbations. The proposed method is built on lightweight algorithms and proved highly effective based on comprehensive evaluations, showing good efficiency on computation cost and robustness enhancement. In addition, we share our insights about the data-centric robust machine learning gained from our experiments.