 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Similarity: Trustworthy Memory Search for Personal AI Agents
Jun 04, 2026Personal AI agents increasingly rely on long-term memory to provide persistent personalization across sessions. However, existing memory pipelines are largely driven by semantic similarity: memory data close to the current query is retrieved and injected into the model context. This creates a critical trustworthiness gap, since a semantically related memory may still be contextually inappropriate, leading to threats such as cross-domain leakage, sycophancy, tool-call drift, or memory-induced jailbreaks. In this paper, we study memory search as a trust boundary in personal AI agents. We evaluate representative agentic memory frameworks, including A-Mem, Mem0, and MemOS, together with OpenClaw, a real-world personal-agent environment with persistent state and tool-use capability. Our results show that long-term memory is not merely a utility layer, but a durable control channel that can reshape how agents interpret tasks and execute actions, leaving them highly susceptible to the aforementioned threats. To mitigate these vulnerabilities, we propose MemGate, a lightweight and deployable memory plug-in for trustworthy memory search, with only 9M parameters and a 35.1MB footprint. MemGate is inserted between the vector memory store and the backbone LLM, requiring no LLM modification, memory-database rewriting, or inference-time LLM judge. It applies a query-conditioned neural gate to candidate memory representations, turning raw similarity search into task-conditioned memory admission. Across multiple mainstream memory frameworks, real-world agent settings, and diverse LLM backbones, MemGate reduces memory-induced threats while preserving long-term memory utility.
When Are Teacher Tokens Reliable? Position-Weighted On-Policy Self-Distillation for Reasoning
May 20, 2026On-policy self-distillation (OPSD) trains a student on its own rollouts using a privileged teacher, but its standard objective weights all generated tokens equally, implicitly treating the privileged teacher target as equally reliable at every student-visited prefix. Existing entropy-based OPD methods relax this uniformity by modulating token-level supervision with teacher entropy, but high teacher entropy in reasoning has an ambiguous reliability meaning: it can reflect either non-viable uncertainty or benign solution diversity. To identify this phenomenon, we introduce a branch-viability diagnostic. Specifically, we record next-token alternatives from the privileged-answer teacher prompt, force each alternative after the student prompt plus its on-policy spine prefix, and test whether the resulting student-template continuation recovers the correct answer. On Qwen3-4B, we find that an oriented within-sequence position score is the strongest tested predictor of teacher-token reliability, reaching an area-under-ROC-curve (AUROC) of 0.83; local uncertainty scores are at most 0.57. Motivated by this trajectory-level structure, we propose Position-Weighted On-Policy Self-Distillation (PW-OPSD), which applies an increasing position weight while keeping the same student rollout, privileged teacher pass, and clipped forward-KL target as OPSD. In our comprehensive evaluations with different random seeds, the diagnostic-derived PW-OPSD improves AIME 2024 and AIME 2025 Avg@12 by +1.0 and +1.1 points, and a generalization evaluation on two larger-scale models from different families, DeepSeek-R1-Distill-Llama-8B and Olmo-3-7B-Think, also demonstrates consistent aggregate Avg@12 improvements. These results show that teacher-token reliability in reasoning distillation is trajectory-structured and can be utilized without additional teacher computation.
VideoSEAL: Mitigating Evidence Misalignment in Agentic Long Video Understanding by Decoupling Answer Authority
May 12, 2026Long video question answering requires locating sparse, time-scattered visual evidence within highly redundant content. Although current MLLMs perform well on short videos, long videos introduce long-horizon search and verification, which often necessitates multi-turn, agentic interaction. We show that existing LVU agents can exhibit "evidence misalignment": they produce correct answers that are not supported by the retrieved or inspected evidence. To characterize this failure, we introduce two diagnostics (temporal groundedness and semantic groundedness) and use them to reveal two pressures that amplify misalignment: prompt pressure from shared-context saturation at inference time and reward pressure from outcome-only optimization during training. These findings point to a structural root cause: the coupled agent paradigm conflates long-horizon planning with answer authority. We therefore propose the decoupled planner-inspector framework, which separates planning from answer authority and gates final answering on pixel-level verification. Across four long-video benchmarks, our framework improves both answer accuracy and evidence alignment, achieving 55.1% on LVBench and 62.0% on LongVideoBench while producing interpretable search trajectories. Moreover, the decoupled architecture scales consistently with increased search budgets and supports plug-and-play upgrades of the MLLM backbone without retraining the planner. Code and models are available at https://github.com/Echochef/VideoSEAL.
Mind Your HEARTBEAT! Claw Background Execution Inherently Enables Silent Memory Pollution
Mar 25, 2026We identify a critical security vulnerability in mainstream Claw personal AI agents: untrusted content encountered during heartbeat-driven background execution can silently pollute agent memory and subsequently influence user-facing behavior without the user's awareness. This vulnerability arises from an architectural design shared across the Claw ecosystem: heartbeat background execution runs in the same session as user-facing conversation, so content ingested from any external source monitored in the background (including email, message channels, news feeds, code repositories, and social platforms) can enter the same memory context used for foreground interaction, often with limited user visibility and without clear source provenance. We formalize this process as an Exposure (E) $\rightarrow$ Memory (M) $\rightarrow$ Behavior (B) pathway: misinformation encountered during heartbeat execution enters the agent's short-term session context, potentially gets written into long-term memory, and later shapes downstream user-facing behavior. We instantiate this pathway in an agent-native social setting using MissClaw, a controlled research replica of Moltbook. We find that (1) social credibility cues, especially perceived consensus, are the dominant driver of short-term behavioral influence, with misleading rates up to 61%; (2) routine memory-saving behavior can promote short-term pollution into durable long-term memory at rates up to 91%, with cross-session behavioral influence reaching 76%; (3) under naturalistic browsing with content dilution and context pruning, pollution still crosses session boundaries. Overall, prompt injection is not required: ordinary social misinformation is sufficient to silently shape agent memory and behavior under heartbeat-driven background execution.
ReasoningBomb: A Stealthy Denial-of-Service Attack by Inducing Pathologically Long Reasoning in Large Reasoning Models
Jan 29, 2026Large reasoning models (LRMs) extend large language models with explicit multi-step reasoning traces, but this capability introduces a new class of prompt-induced inference-time denial-of-service (PI-DoS) attacks that exploit the high computational cost of reasoning. We first formalize inference cost for LRMs and define PI-DoS, then prove that any practical PI-DoS attack should satisfy three properties: (1) a high amplification ratio, where each query induces a disproportionately long reasoning trace relative to its own length; (ii) stealthiness, in which prompts and responses remain on the natural language manifold and evade distribution shift detectors; and (iii) optimizability, in which the attack supports efficient optimization without being slowed by its own success. Under this framework, we present ReasoningBomb, a reinforcement-learning-based PI-DoS framework that is guided by a constant-time surrogate reward and trains a large reasoning-model attacker to generate short natural prompts that drive victim LRMs into pathologically long and often effectively non-terminating reasoning. Across seven open-source models (including LLMs and LRMs) and three commercial LRMs, ReasoningBomb induces 18,759 completion tokens on average and 19,263 reasoning tokens on average across reasoning models. It outperforms the the runner-up baseline by 35% in completion tokens and 38% in reasoning tokens, while inducing 6-7x more tokens than benign queries and achieving 286.7x input-to-output amplification ratio averaged across all samples. Additionally, our method achieves 99.8% bypass rate on input-based detection, 98.7% on output-based detection, and 98.4% against strict dual-stage joint detection.
Dual-View Inference Attack: Machine Unlearning Amplifies Privacy Exposure
Dec 18, 2025Machine unlearning is a newly popularized technique for removing specific training data from a trained model, enabling it to comply with data deletion requests. While it protects the rights of users requesting unlearning, it also introduces new privacy risks. Prior works have primarily focused on the privacy of data that has been unlearned, while the risks to retained data remain largely unexplored. To address this gap, we focus on the privacy risks of retained data and, for the first time, reveal the vulnerabilities introduced by machine unlearning under the dual-view setting, where an adversary can query both the original and the unlearned models. From an information-theoretic perspective, we introduce the concept of {privacy knowledge gain} and demonstrate that the dual-view setting allows adversaries to obtain more information than querying either model alone, thereby amplifying privacy leakage. To effectively demonstrate this threat, we propose DVIA, a Dual-View Inference Attack, which extracts membership information on retained data using black-box queries to both models. DVIA eliminates the need to train an attack model and employs a lightweight likelihood ratio inference module for efficient inference. Experiments across different datasets and model architectures validate the effectiveness of DVIA and highlight the privacy risks inherent in the dual-view setting.
A Systematic Study of Code Obfuscation Against LLM-based Vulnerability Detection
Dec 18, 2025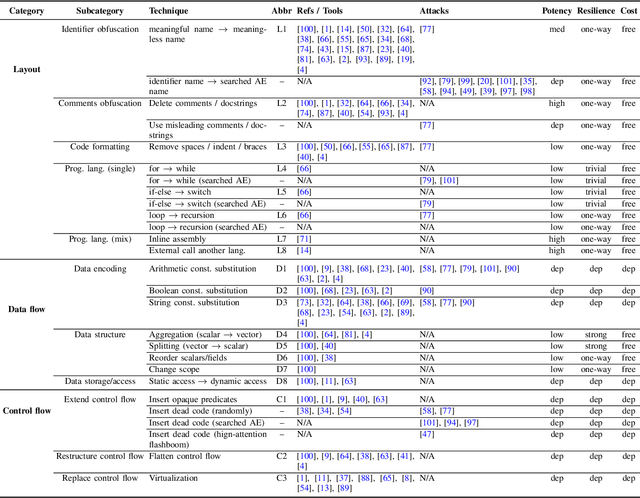
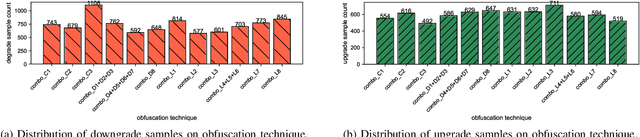

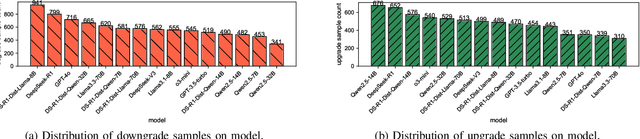
As large language models (LLMs) are increasingly adopted for code vulnerability detection, their reliability and robustness across diverse vulnerability types have become a pressing concern. In traditional adversarial settings, code obfuscation has long been used as a general strategy to bypass auditing tools, preserving exploitability without tampering with the tools themselves. Numerous efforts have explored obfuscation methods and tools, yet their capabilities differ in terms of supported techniques, granularity, and programming languages, making it difficult to systematically assess their impact on LLM-based vulnerability detection. To address this gap, we provide a structured systematization of obfuscation techniques and evaluate them under a unified framework. Specifically, we categorize existing obfuscation methods into three major classes (layout, data flow, and control flow) covering 11 subcategories and 19 concrete techniques. We implement these techniques across four programming languages (Solidity, C, C++, and Python) using a consistent LLM-driven approach, and evaluate their effects on 15 LLMs spanning four model families (DeepSeek, OpenAI, Qwen, and LLaMA), as well as on two coding agents (GitHub Copilot and Codex). Our findings reveal both positive and negative impacts of code obfuscation on LLM-based vulnerability detection, highlighting conditions under which obfuscation leads to performance improvements or degradations. We further analyze these outcomes with respect to vulnerability characteristics, code properties, and model attributes. Finally, we outline several open problems and propose future directions to enhance the robustness of LLMs for real-world vulnerability detection.
Towards Real-World Deepfake Detection: A Diverse In-the-wild Dataset of Forgery Faces
Oct 09, 2025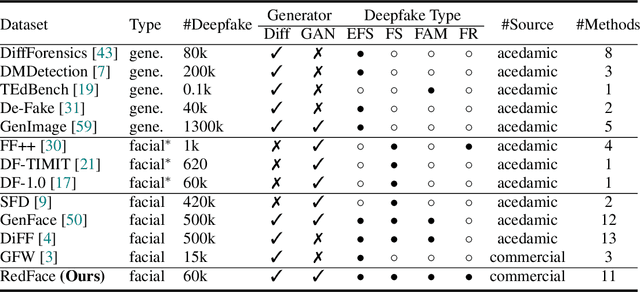


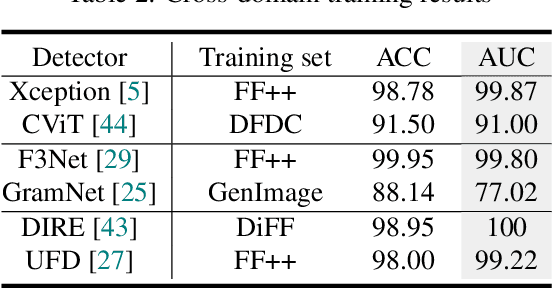
Deepfakes, leveraging advanced AIGC (Artificial Intelligence-Generated Content) techniques, create hyper-realistic synthetic images and videos of human faces, posing a significant threat to the authenticity of social media. While this real-world threat is increasingly prevalent, existing academic evaluations and benchmarks for detecting deepfake forgery often fall short to achieve effective application for their lack of specificity, limited deepfake diversity, restricted manipulation techniques.To address these limitations, we introduce RedFace (Real-world-oriented Deepfake Face), a specialized facial deepfake dataset, comprising over 60,000 forged images and 1,000 manipulated videos derived from authentic facial features, to bridge the gap between academic evaluations and real-world necessity. Unlike prior benchmarks, which typically rely on academic methods to generate deepfakes, RedFace utilizes 9 commercial online platforms to integrate the latest deepfake technologies found "in the wild", effectively simulating real-world black-box scenarios.Moreover, RedFace's deepfakes are synthesized using bespoke algorithms, allowing it to capture diverse and evolving methods used by real-world deepfake creators. Extensive experimental results on RedFace (including cross-domain, intra-domain, and real-world social network dissemination simulations) verify the limited practicality of existing deepfake detection schemes against real-world applications. We further perform a detailed analysis of the RedFace dataset, elucidating the reason of its impact on detection performance compared to conventional datasets. Our dataset is available at: https://github.com/kikyou-220/RedFace.
Transferable Direct Prompt Injection via Activation-Guided MCMC Sampling
Sep 09, 2025Direct Prompt Injection (DPI) attacks pose a critical security threat to Large Language Models (LLMs) due to their low barrier of execution and high potential damage. To address the impracticality of existing white-box/gray-box methods and the poor transferability of black-box methods, we propose an activations-guided prompt injection attack framework. We first construct an Energy-based Model (EBM) using activations from a surrogate model to evaluate the quality of adversarial prompts. Guided by the trained EBM, we employ the token-level Markov Chain Monte Carlo (MCMC) sampling to adaptively optimize adversarial prompts, thereby enabling gradient-free black-box attacks. Experimental results demonstrate our superior cross-model transferability, achieving 49.6% attack success rate (ASR) across five mainstream LLMs and 34.6% improvement over human-crafted prompts, and maintaining 36.6% ASR on unseen task scenarios. Interpretability analysis reveals a correlation between activations and attack effectiveness, highlighting the critical role of semantic patterns in transferable vulnerability exploitation.
Say What You Mean: Natural Language Access Control with Large Language Models for Internet of Things
May 28, 2025

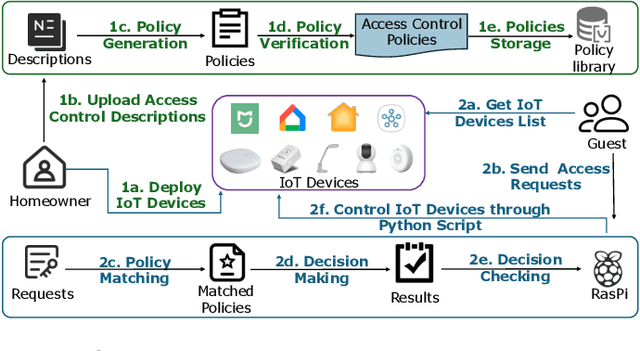

Access control in the Internet of Things (IoT) is becoming increasingly complex, as policies must account for dynamic and contextual factors such as time, location, user behavior, and environmental conditions. However, existing platforms either offer only coarse-grained controls or rely on rigid rule matching, making them ill-suited for semantically rich or ambiguous access scenarios. Moreover, the policy authoring process remains fragmented: domain experts describe requirements in natural language, but developers must manually translate them into code, introducing semantic gaps and potential misconfiguration. In this work, we present LACE, the Language-based Access Control Engine, a hybrid framework that leverages large language models (LLMs) to bridge the gap between human intent and machine-enforceable logic. LACE combines prompt-guided policy generation, retrieval-augmented reasoning, and formal validation to support expressive, interpretable, and verifiable access control. It enables users to specify policies in natural language, automatically translates them into structured rules, validates semantic correctness, and makes access decisions using a hybrid LLM-rule-based engine. We evaluate LACE in smart home environments through extensive experiments. LACE achieves 100% correctness in verified policy generation and up to 88% decision accuracy with 0.79 F1-score using DeepSeek-V3, outperforming baselines such as GPT-3.5 and Gemini. The system also demonstrates strong scalability under increasing policy volume and request concurrency. Our results highlight LACE's potential to enable secure, flexible, and user-friendly access control across real-world IoT platforms.