 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhy Does Little Robustness Help? Understanding Adversarial Transferability From Surrogate Training
Paper and Code
Jul 19, 2023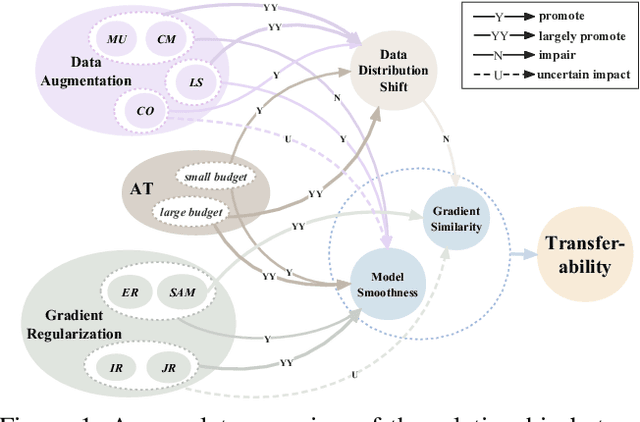
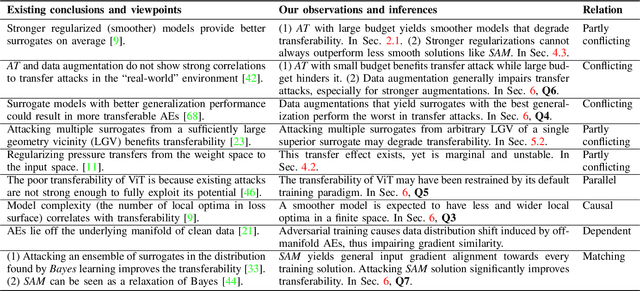
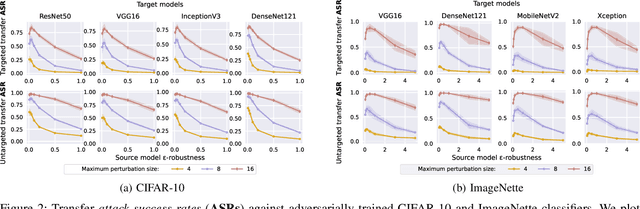
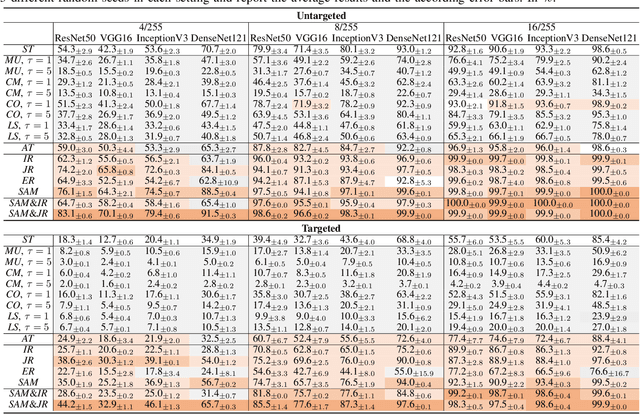
Adversarial examples (AEs) for DNNs have been shown to be transferable: AEs that successfully fool white-box surrogate models can also deceive other black-box models with different architectures. Although a bunch of empirical studies have provided guidance on generating highly transferable AEs, many of these findings lack explanations and even lead to inconsistent advice. In this paper, we take a further step towards understanding adversarial transferability, with a particular focus on surrogate aspects. Starting from the intriguing little robustness phenomenon, where models adversarially trained with mildly perturbed adversarial samples can serve as better surrogates, we attribute it to a trade-off between two predominant factors: model smoothness and gradient similarity. Our investigations focus on their joint effects, rather than their separate correlations with transferability. Through a series of theoretical and empirical analyses, we conjecture that the data distribution shift in adversarial training explains the degradation of gradient similarity. Building on these insights, we explore the impacts of data augmentation and gradient regularization on transferability and identify that the trade-off generally exists in the various training mechanisms, thus building a comprehensive blueprint for the regulation mechanism behind transferability. Finally, we provide a general route for constructing better surrogates to boost transferability which optimizes both model smoothness and gradient similarity simultaneously, e.g., the combination of input gradient regularization and sharpness-aware minimization (SAM), validated by extensive experiments. In summary, we call for attention to the united impacts of these two factors for launching effective transfer attacks, rather than optimizing one while ignoring the other, and emphasize the crucial role of manipulating surrogate models.