 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDual-branch Robust Unlearnable Examples
May 03, 2026Unlearnable examples (UEs) aim to compromise model training by injecting imperceptible perturbations to clean samples. However, existing UE schemes exhibit limited robustness against advanced defenses due to their heuristic design or narrowly scoped domain perturbations. To address this, we propose \texttt{DUNE}, a \underline{\textbf{D}}ual-branch \underline{\textbf{UN}}learnable \underline{\textbf{E}}nsemble perturbation optimization approach. Specifically, \texttt{DUNE} separately optimizes perturbations in the spatial and color domains to establish the mapping between perturbations and shift-induced labels. This design extends the perturbation domain to increase noise intensity for improving robustness and drives the models to learn perturbation-oriented features with degraded generalization, thereby achieving unlearnability. To strengthen \texttt{DUNE}'s performance, we further propose an unlearnability-enhancing ensemble strategy that aggregates diverse pre-trained models during the dual-branch optimization. Extensive experiments on benchmark datasets CIFAR-10 and ImageNet verify that \texttt{DUNE}'s robustness outperforms 12 SOTA UE schemes under 7 mainstream defenses, yielding a lower average test accuracy of 14.95\% to 50.82\%.
TSCAN: Context-Aware Uplift Modeling via Two-Stage Training for Online Merchant Business Diagnosis
Apr 26, 2025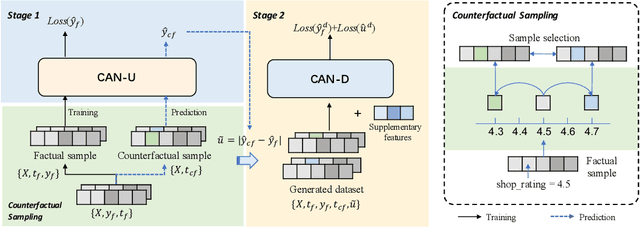

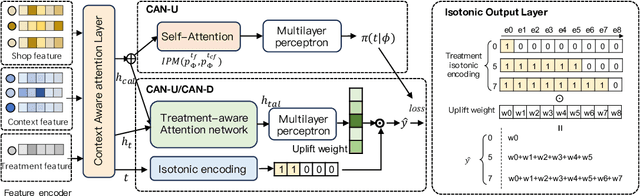

A primary challenge in ITE estimation is sample selection bias. Traditional approaches utilize treatment regularization techniques such as the Integral Probability Metrics (IPM), re-weighting, and propensity score modeling to mitigate this bias. However, these regularizations may introduce undesirable information loss and limit the performance of the model. Furthermore, treatment effects vary across different external contexts, and the existing methods are insufficient in fully interacting with and utilizing these contextual features. To address these issues, we propose a Context-Aware uplift model based on the Two-Stage training approach (TSCAN), comprising CAN-U and CAN-D sub-models. In the first stage, we train an uplift model, called CAN-U, which includes the treatment regularizations of IPM and propensity score prediction, to generate a complete dataset with counterfactual uplift labels. In the second stage, we train a model named CAN-D, which utilizes an isotonic output layer to directly model uplift effects, thereby eliminating the reliance on the regularization components. CAN-D adaptively corrects the errors estimated by CAN-U through reinforcing the factual samples, while avoiding the negative impacts associated with the aforementioned regularizations. Additionally, we introduce a Context-Aware Attention Layer throughout the two-stage process to manage the interactions between treatment, merchant, and contextual features, thereby modeling the varying treatment effect in different contexts. We conduct extensive experiments on two real-world datasets to validate the effectiveness of TSCAN. Ultimately, the deployment of our model for real-world merchant diagnosis on one of China's largest online food ordering platforms validates its practical utility and impact.
Test-Time Backdoor Detection for Object Detection Models
Mar 19, 2025Object detection models are vulnerable to backdoor attacks, where attackers poison a small subset of training samples by embedding a predefined trigger to manipulate prediction. Detecting poisoned samples (i.e., those containing triggers) at test time can prevent backdoor activation. However, unlike image classification tasks, the unique characteristics of object detection -- particularly its output of numerous objects -- pose fresh challenges for backdoor detection. The complex attack effects (e.g., "ghost" object emergence or "vanishing" object) further render current defenses fundamentally inadequate. To this end, we design TRAnsformation Consistency Evaluation (TRACE), a brand-new method for detecting poisoned samples at test time in object detection. Our journey begins with two intriguing observations: (1) poisoned samples exhibit significantly more consistent detection results than clean ones across varied backgrounds. (2) clean samples show higher detection consistency when introduced to different focal information. Based on these phenomena, TRACE applies foreground and background transformations to each test sample, then assesses transformation consistency by calculating the variance in objects confidences. TRACE achieves black-box, universal backdoor detection, with extensive experiments showing a 30% improvement in AUROC over state-of-the-art defenses and resistance to adaptive attacks.
Breaking Barriers in Physical-World Adversarial Examples: Improving Robustness and Transferability via Robust Feature
Dec 22, 2024



As deep neural networks (DNNs) are widely applied in the physical world, many researches are focusing on physical-world adversarial examples (PAEs), which introduce perturbations to inputs and cause the model's incorrect outputs. However, existing PAEs face two challenges: unsatisfactory attack performance (i.e., poor transferability and insufficient robustness to environment conditions), and difficulty in balancing attack effectiveness with stealthiness, where better attack effectiveness often makes PAEs more perceptible. In this paper, we explore a novel perturbation-based method to overcome the challenges. For the first challenge, we introduce a strategy Deceptive RF injection based on robust features (RFs) that are predictive, robust to perturbations, and consistent across different models. Specifically, it improves the transferability and robustness of PAEs by covering RFs of other classes onto the predictive features in clean images. For the second challenge, we introduce another strategy Adversarial Semantic Pattern Minimization, which removes most perturbations and retains only essential adversarial patterns in AEsBased on the two strategies, we design our method Robust Feature Coverage Attack (RFCoA), comprising Robust Feature Disentanglement and Adversarial Feature Fusion. In the first stage, we extract target class RFs in feature space. In the second stage, we use attention-based feature fusion to overlay these RFs onto predictive features of clean images and remove unnecessary perturbations. Experiments show our method's superior transferability, robustness, and stealthiness compared to existing state-of-the-art methods. Additionally, our method's effectiveness can extend to Large Vision-Language Models (LVLMs), indicating its potential applicability to more complex tasks.
TrojanRobot: Backdoor Attacks Against Robotic Manipulation in the Physical World
Nov 18, 2024Robotic manipulation refers to the autonomous handling and interaction of robots with objects using advanced techniques in robotics and artificial intelligence. The advent of powerful tools such as large language models (LLMs) and large vision-language models (LVLMs) has significantly enhanced the capabilities of these robots in environmental perception and decision-making. However, the introduction of these intelligent agents has led to security threats such as jailbreak attacks and adversarial attacks. In this research, we take a further step by proposing a backdoor attack specifically targeting robotic manipulation and, for the first time, implementing backdoor attack in the physical world. By embedding a backdoor visual language model into the visual perception module within the robotic system, we successfully mislead the robotic arm's operation in the physical world, given the presence of common items as triggers. Experimental evaluations in the physical world demonstrate the effectiveness of the proposed backdoor attack.
Unlearnable 3D Point Clouds: Class-wise Transformation Is All You Need
Oct 04, 2024Traditional unlearnable strategies have been proposed to prevent unauthorized users from training on the 2D image data. With more 3D point cloud data containing sensitivity information, unauthorized usage of this new type data has also become a serious concern. To address this, we propose the first integral unlearnable framework for 3D point clouds including two processes: (i) we propose an unlearnable data protection scheme, involving a class-wise setting established by a category-adaptive allocation strategy and multi-transformations assigned to samples; (ii) we propose a data restoration scheme that utilizes class-wise inverse matrix transformation, thus enabling authorized-only training for unlearnable data. This restoration process is a practical issue overlooked in most existing unlearnable literature, \ie, even authorized users struggle to gain knowledge from 3D unlearnable data. Both theoretical and empirical results (including 6 datasets, 16 models, and 2 tasks) demonstrate the effectiveness of our proposed unlearnable framework. Our code is available at \url{https://github.com/CGCL-codes/UnlearnablePC}
Detector Collapse: Backdooring Object Detection to Catastrophic Overload or Blindness
Apr 17, 2024Object detection tasks, crucial in safety-critical systems like autonomous driving, focus on pinpointing object locations. These detectors are known to be susceptible to backdoor attacks. However, existing backdoor techniques have primarily been adapted from classification tasks, overlooking deeper vulnerabilities specific to object detection. This paper is dedicated to bridging this gap by introducing Detector Collapse} (DC), a brand-new backdoor attack paradigm tailored for object detection. DC is designed to instantly incapacitate detectors (i.e., severely impairing detector's performance and culminating in a denial-of-service). To this end, we develop two innovative attack schemes: Sponge for triggering widespread misidentifications and Blinding for rendering objects invisible. Remarkably, we introduce a novel poisoning strategy exploiting natural objects, enabling DC to act as a practical backdoor in real-world environments. Our experiments on different detectors across several benchmarks show a significant improvement ($\sim$10\%-60\% absolute and $\sim$2-7$\times$ relative) in attack efficacy over state-of-the-art attacks.
AdvCLIP: Downstream-agnostic Adversarial Examples in Multimodal Contrastive Learning
Aug 14, 2023



Multimodal contrastive learning aims to train a general-purpose feature extractor, such as CLIP, on vast amounts of raw, unlabeled paired image-text data. This can greatly benefit various complex downstream tasks, including cross-modal image-text retrieval and image classification. Despite its promising prospect, the security issue of cross-modal pre-trained encoder has not been fully explored yet, especially when the pre-trained encoder is publicly available for commercial use. In this work, we propose AdvCLIP, the first attack framework for generating downstream-agnostic adversarial examples based on cross-modal pre-trained encoders. AdvCLIP aims to construct a universal adversarial patch for a set of natural images that can fool all the downstream tasks inheriting the victim cross-modal pre-trained encoder. To address the challenges of heterogeneity between different modalities and unknown downstream tasks, we first build a topological graph structure to capture the relevant positions between target samples and their neighbors. Then, we design a topology-deviation based generative adversarial network to generate a universal adversarial patch. By adding the patch to images, we minimize their embeddings similarity to different modality and perturb the sample distribution in the feature space, achieving unviersal non-targeted attacks. Our results demonstrate the excellent attack performance of AdvCLIP on two types of downstream tasks across eight datasets. We also tailor three popular defenses to mitigate AdvCLIP, highlighting the need for new defense mechanisms to defend cross-modal pre-trained encoders.
Denial-of-Service or Fine-Grained Control: Towards Flexible Model Poisoning Attacks on Federated Learning
Apr 21, 2023



Federated learning (FL) is vulnerable to poisoning attacks, where adversaries corrupt the global aggregation results and cause denial-of-service (DoS). Unlike recent model poisoning attacks that optimize the amplitude of malicious perturbations along certain prescribed directions to cause DoS, we propose a Flexible Model Poisoning Attack (FMPA) that can achieve versatile attack goals. We consider a practical threat scenario where no extra knowledge about the FL system (e.g., aggregation rules or updates on benign devices) is available to adversaries. FMPA exploits the global historical information to construct an estimator that predicts the next round of the global model as a benign reference. It then fine-tunes the reference model to obtain the desired poisoned model with low accuracy and small perturbations. Besides the goal of causing DoS, FMPA can be naturally extended to launch a fine-grained controllable attack, making it possible to precisely reduce the global accuracy. Armed with precise control, malicious FL service providers can gain advantages over their competitors without getting noticed, hence opening a new attack surface in FL other than DoS. Even for the purpose of DoS, experiments show that FMPA significantly decreases the global accuracy, outperforming six state-of-the-art attacks.