 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDual-branch Robust Unlearnable Examples
May 03, 2026Unlearnable examples (UEs) aim to compromise model training by injecting imperceptible perturbations to clean samples. However, existing UE schemes exhibit limited robustness against advanced defenses due to their heuristic design or narrowly scoped domain perturbations. To address this, we propose \texttt{DUNE}, a \underline{\textbf{D}}ual-branch \underline{\textbf{UN}}learnable \underline{\textbf{E}}nsemble perturbation optimization approach. Specifically, \texttt{DUNE} separately optimizes perturbations in the spatial and color domains to establish the mapping between perturbations and shift-induced labels. This design extends the perturbation domain to increase noise intensity for improving robustness and drives the models to learn perturbation-oriented features with degraded generalization, thereby achieving unlearnability. To strengthen \texttt{DUNE}'s performance, we further propose an unlearnability-enhancing ensemble strategy that aggregates diverse pre-trained models during the dual-branch optimization. Extensive experiments on benchmark datasets CIFAR-10 and ImageNet verify that \texttt{DUNE}'s robustness outperforms 12 SOTA UE schemes under 7 mainstream defenses, yielding a lower average test accuracy of 14.95\% to 50.82\%.
Towards Long-Horizon Interpretability: Efficient and Faithful Multi-Token Attribution for Reasoning LLMs
Feb 02, 2026Token attribution methods provide intuitive explanations for language model outputs by identifying causally important input tokens. However, as modern LLMs increasingly rely on extended reasoning chains, existing schemes face two critical challenges: (1) efficiency bottleneck, where attributing a target span of M tokens within a context of length N requires O(M*N) operations, making long-context attribution prohibitively slow; and (2) faithfulness drop, where intermediate reasoning tokens absorb attribution mass, preventing importance from propagating back to the original input. To address these, we introduce FlashTrace, an efficient multi-token attribution method that employs span-wise aggregation to compute attribution over multi-token targets in a single pass, while maintaining faithfulness. Moreover, we design a recursive attribution mechanism that traces importance through intermediate reasoning chains back to source inputs. Extensive experiments on long-context retrieval (RULER) and multi-step reasoning (MATH, MorehopQA) tasks demonstrate that FlashTrace achieves over 130x speedup over existing baselines while maintaining superior faithfulness. We further analyze the dynamics of recursive attribution, showing that even a single recursive hop improves faithfulness by tracing importance through the reasoning chain.
PB-UAP: Hybrid Universal Adversarial Attack For Image Segmentation
Dec 21, 2024



With the rapid advancement of deep learning, the model robustness has become a significant research hotspot, \ie, adversarial attacks on deep neural networks. Existing works primarily focus on image classification tasks, aiming to alter the model's predicted labels. Due to the output complexity and deeper network architectures, research on adversarial examples for segmentation models is still limited, particularly for universal adversarial perturbations. In this paper, we propose a novel universal adversarial attack method designed for segmentation models, which includes dual feature separation and low-frequency scattering modules. The two modules guide the training of adversarial examples in the pixel and frequency space, respectively. Experiments demonstrate that our method achieves high attack success rates surpassing the state-of-the-art methods, and exhibits strong transferability across different models.
TrojanRobot: Backdoor Attacks Against Robotic Manipulation in the Physical World
Nov 18, 2024Robotic manipulation refers to the autonomous handling and interaction of robots with objects using advanced techniques in robotics and artificial intelligence. The advent of powerful tools such as large language models (LLMs) and large vision-language models (LVLMs) has significantly enhanced the capabilities of these robots in environmental perception and decision-making. However, the introduction of these intelligent agents has led to security threats such as jailbreak attacks and adversarial attacks. In this research, we take a further step by proposing a backdoor attack specifically targeting robotic manipulation and, for the first time, implementing backdoor attack in the physical world. By embedding a backdoor visual language model into the visual perception module within the robotic system, we successfully mislead the robotic arm's operation in the physical world, given the presence of common items as triggers. Experimental evaluations in the physical world demonstrate the effectiveness of the proposed backdoor attack.
Unlearnable 3D Point Clouds: Class-wise Transformation Is All You Need
Oct 04, 2024Traditional unlearnable strategies have been proposed to prevent unauthorized users from training on the 2D image data. With more 3D point cloud data containing sensitivity information, unauthorized usage of this new type data has also become a serious concern. To address this, we propose the first integral unlearnable framework for 3D point clouds including two processes: (i) we propose an unlearnable data protection scheme, involving a class-wise setting established by a category-adaptive allocation strategy and multi-transformations assigned to samples; (ii) we propose a data restoration scheme that utilizes class-wise inverse matrix transformation, thus enabling authorized-only training for unlearnable data. This restoration process is a practical issue overlooked in most existing unlearnable literature, \ie, even authorized users struggle to gain knowledge from 3D unlearnable data. Both theoretical and empirical results (including 6 datasets, 16 models, and 2 tasks) demonstrate the effectiveness of our proposed unlearnable framework. Our code is available at \url{https://github.com/CGCL-codes/UnlearnablePC}
DarkSAM: Fooling Segment Anything Model to Segment Nothing
Sep 26, 2024

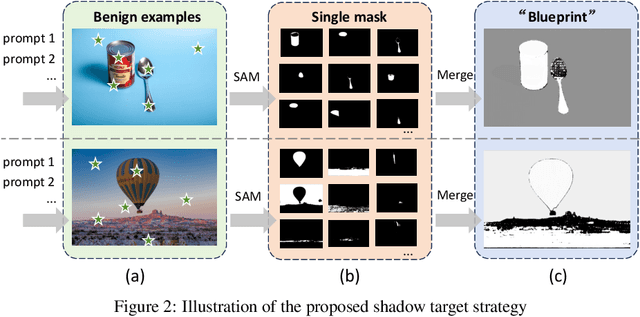
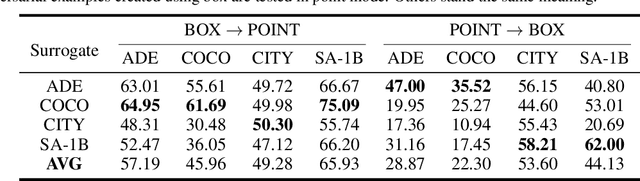
Segment Anything Model (SAM) has recently gained much attention for its outstanding generalization to unseen data and tasks. Despite its promising prospect, the vulnerabilities of SAM, especially to universal adversarial perturbation (UAP) have not been thoroughly investigated yet. In this paper, we propose DarkSAM, the first prompt-free universal attack framework against SAM, including a semantic decoupling-based spatial attack and a texture distortion-based frequency attack. We first divide the output of SAM into foreground and background. Then, we design a shadow target strategy to obtain the semantic blueprint of the image as the attack target. DarkSAM is dedicated to fooling SAM by extracting and destroying crucial object features from images in both spatial and frequency domains. In the spatial domain, we disrupt the semantics of both the foreground and background in the image to confuse SAM. In the frequency domain, we further enhance the attack effectiveness by distorting the high-frequency components (i.e., texture information) of the image. Consequently, with a single UAP, DarkSAM renders SAM incapable of segmenting objects across diverse images with varying prompts. Experimental results on four datasets for SAM and its two variant models demonstrate the powerful attack capability and transferability of DarkSAM.
Deep Learning Techniques for Automatic Lateral X-ray Cephalometric Landmark Detection: Is the Problem Solved?
Sep 24, 2024Localization of the craniofacial landmarks from lateral cephalograms is a fundamental task in cephalometric analysis. The automation of the corresponding tasks has thus been the subject of intense research over the past decades. In this paper, we introduce the "Cephalometric Landmark Detection (CL-Detection)" dataset, which is the largest publicly available and comprehensive dataset for cephalometric landmark detection. This multi-center and multi-vendor dataset includes 600 lateral X-ray images with 38 landmarks acquired with different equipment from three medical centers. The overarching objective of this paper is to measure how far state-of-the-art deep learning methods can go for cephalometric landmark detection. Following the 2023 MICCAI CL-Detection Challenge, we report the results of the top ten research groups using deep learning methods. Results show that the best methods closely approximate the expert analysis, achieving a mean detection rate of 75.719% and a mean radial error of 1.518 mm. While there is room for improvement, these findings undeniably open the door to highly accurate and fully automatic location of craniofacial landmarks. We also identify scenarios for which deep learning methods are still failing. Both the dataset and detailed results are publicly available online, while the platform will remain open for the community to benchmark future algorithm developments at https://cl-detection2023.grand-challenge.org/.
ECLIPSE: Expunging Clean-label Indiscriminate Poisons via Sparse Diffusion Purification
Jun 25, 2024
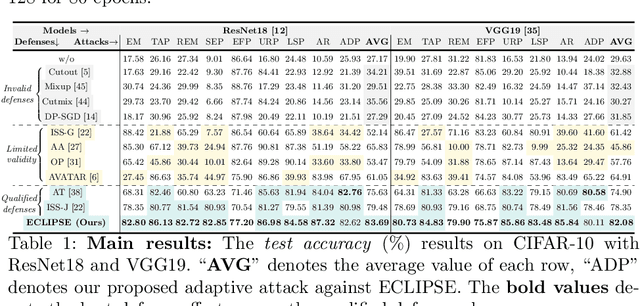
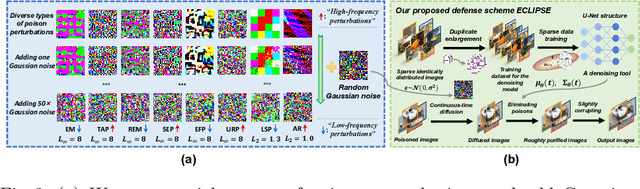
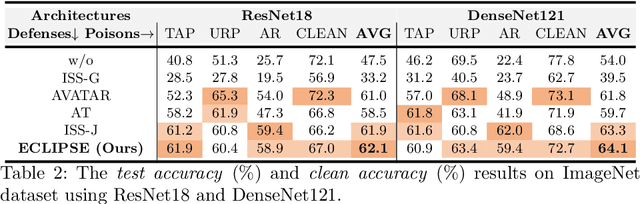
Clean-label indiscriminate poisoning attacks add invisible perturbations to correctly labeled training images, thus dramatically reducing the generalization capability of the victim models. Recently, some defense mechanisms have been proposed such as adversarial training, image transformation techniques, and image purification. However, these schemes are either susceptible to adaptive attacks, built on unrealistic assumptions, or only effective against specific poison types, limiting their universal applicability. In this research, we propose a more universally effective, practical, and robust defense scheme called ECLIPSE. We first investigate the impact of Gaussian noise on the poisons and theoretically prove that any kind of poison will be largely assimilated when imposing sufficient random noise. In light of this, we assume the victim has access to an extremely limited number of clean images (a more practical scene) and subsequently enlarge this sparse set for training a denoising probabilistic model (a universal denoising tool). We then begin by introducing Gaussian noise to absorb the poisons and then apply the model for denoising, resulting in a roughly purified dataset. Finally, to address the trade-off of the inconsistency in the assimilation sensitivity of different poisons by Gaussian noise, we propose a lightweight corruption compensation module to effectively eliminate residual poisons, providing a more universal defense approach. Extensive experiments demonstrate that our defense approach outperforms 10 state-of-the-art defenses. We also propose an adaptive attack against ECLIPSE and verify the robustness of our defense scheme. Our code is available at https://github.com/CGCL-codes/ECLIPSE.
Detector Collapse: Backdooring Object Detection to Catastrophic Overload or Blindness
Apr 17, 2024Object detection tasks, crucial in safety-critical systems like autonomous driving, focus on pinpointing object locations. These detectors are known to be susceptible to backdoor attacks. However, existing backdoor techniques have primarily been adapted from classification tasks, overlooking deeper vulnerabilities specific to object detection. This paper is dedicated to bridging this gap by introducing Detector Collapse} (DC), a brand-new backdoor attack paradigm tailored for object detection. DC is designed to instantly incapacitate detectors (i.e., severely impairing detector's performance and culminating in a denial-of-service). To this end, we develop two innovative attack schemes: Sponge for triggering widespread misidentifications and Blinding for rendering objects invisible. Remarkably, we introduce a novel poisoning strategy exploiting natural objects, enabling DC to act as a practical backdoor in real-world environments. Our experiments on different detectors across several benchmarks show a significant improvement ($\sim$10\%-60\% absolute and $\sim$2-7$\times$ relative) in attack efficacy over state-of-the-art attacks.
Corrupting Convolution-based Unlearnable Datasets with Pixel-based Image Transformations
Nov 30, 2023



Unlearnable datasets lead to a drastic drop in the generalization performance of models trained on them by introducing elaborate and imperceptible perturbations into clean training sets. Many existing defenses, e.g., JPEG compression and adversarial training, effectively counter UDs based on norm-constrained additive noise. However, a fire-new type of convolution-based UDs have been proposed and render existing defenses all ineffective, presenting a greater challenge to defenders. To address this, we express the convolution-based unlearnable sample as the result of multiplying a matrix by a clean sample in a simplified scenario, and formalize the intra-class matrix inconsistency as $\Theta_{imi}$, inter-class matrix consistency as $\Theta_{imc}$ to investigate the working mechanism of the convolution-based UDs. We conjecture that increasing both of these metrics will mitigate the unlearnability effect. Through validation experiments that commendably support our hypothesis, we further design a random matrix to boost both $\Theta_{imi}$ and $\Theta_{imc}$, achieving a notable degree of defense effect. Hence, by building upon and extending these facts, we first propose a brand-new image COrruption that employs randomly multiplicative transformation via INterpolation operation to successfully defend against convolution-based UDs. Our approach leverages global pixel random interpolations, effectively suppressing the impact of multiplicative noise in convolution-based UDs. Additionally, we have also designed two new forms of convolution-based UDs, and find that our defense is the most effective against them.