 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMMRareBench: A Rare-Disease Multimodal and Multi-Image Medical Benchmark
Apr 12, 2026Multimodal large language models (MLLMs) have advanced clinical tasks for common conditions, but their performance on rare diseases remains largely untested. In rare-disease scenarios, clinicians often lack prior clinical knowledge, forcing them to rely strictly on case-level evidence for clinical judgments. Existing benchmarks predominantly evaluate common-condition, single-image settings, leaving multimodal and multi-image evidence integration under rare-disease data scarcity systematically unevaluated. We introduce MMRareBench, to our knowledge the first rare-disease benchmark jointly evaluating multimodal and multi-image clinical capability across four workflow-aligned tracks: diagnosis, treatment planning, cross-image evidence alignment, and examination suggestion. The benchmark comprises 1,756 question-answer pairs with 7,958 associated medical images curated from PMC case reports, with Orphanet-anchored ontology alignment, track-specific leakage control, evidence-grounded annotations, and a two-level evaluation protocol. A systematic evaluation of 23 MLLMs reveals fragmented capability profiles and universally low treatment-planning performance, with medical-domain models trailing general-purpose MLLMs substantially on multi-image tracks despite competitive diagnostic scores. These patterns are consistent with a capacity dilution effect: medical fine-tuning can narrow the diagnostic gap but may erode the compositional multi-image capability that rare-disease evidence integration demands.
PHASOR: Anatomy- and Phase-Consistent Volumetric Diffusion for CT Virtual Contrast Enhancement
Apr 01, 2026Contrast-enhanced computed tomography (CECT) is pivotal for highlighting tissue perfusion and vascularity, yet its clinical ubiquity is impeded by the invasive nature of contrast agents and radiation risks. While virtual contrast enhancement (VCE) offers an alternative to synthesizing CECT from non-contrast CT (NCCT), existing methods struggle with anatomical heterogeneity and spatial misalignment, leading to inconsistent enhancement patterns and incorrect details. This paper introduces PHASOR, a volumetric diffusion framework for high-fidelity CT VCE. By treating CT volumes as coherent sequences, we leverage a video diffusion model to enhance structural coherence and volumetric accuracy. To ensure anatomy-phase consistent synthesis, we introduce two complementary modules. First, anatomy-routed mixture-of-experts (AR-MoE) anchors distinct enhancement patterns to anatomical semantics, with organ-specific memory to capture salient details. Second, intensity-phase aware representation alignment (IP-REPA) highlights intricate contrast signals while mitigating the impact of imperfect spatial alignment. Extensive experiments across three datasets demonstrate that PHASOR significantly outperforms state-of-the-art methods in both synthesis quality and enhancement accuracy.
Project Imaging-X: A Survey of 1000+ Open-Access Medical Imaging Datasets for Foundation Model Development
Mar 29, 2026Foundation models have demonstrated remarkable success across diverse domains and tasks, primarily due to the thrive of large-scale, diverse, and high-quality datasets. However, in the field of medical imaging, the curation and assembling of such medical datasets are highly challenging due to the reliance on clinical expertise and strict ethical and privacy constraints, resulting in a scarcity of large-scale unified medical datasets and hindering the development of powerful medical foundation models. In this work, we present the largest survey to date of medical image datasets, covering over 1,000 open-access datasets with a systematic catalog of their modalities, tasks, anatomies, annotations, limitations, and potential for integration. Our analysis exposes a landscape that is modest in scale, fragmented across narrowly scoped tasks, and unevenly distributed across organs and modalities, which in turn limits the utility of existing medical image datasets for developing versatile and robust medical foundation models. To turn fragmentation into scale, we propose a metadata-driven fusion paradigm (MDFP) that integrates public datasets with shared modalities or tasks, thereby transforming multiple small data silos into larger, more coherent resources. Building on MDFP, we release an interactive discovery portal that enables end-to-end, automated medical image dataset integration, and compile all surveyed datasets into a unified, structured table that clearly summarizes their key characteristics and provides reference links, offering the community an accessible and comprehensive repository. By charting the current terrain and offering a principled path to dataset consolidation, our survey provides a practical roadmap for scaling medical imaging corpora, supporting faster data discovery, more principled dataset creation, and more capable medical foundation models.
MedQ-Engine: A Closed-Loop Data Engine for Evolving MLLMs in Medical Image Quality Assessment
Mar 20, 2026Medical image quality assessment (Med-IQA) is a prerequisite for clinical AI deployment, yet multimodal large language models (MLLMs) still fall substantially short of human experts, particularly when required to provide descriptive assessments with clinical reasoning beyond simple quality scores. However, improving them is hindered by the high cost of acquiring descriptive annotations and by the inability of one-time data collection to adapt to the model's evolving weaknesses. To address these challenges, we propose MedQ-Engine, a closed-loop data engine that iteratively evaluates the model to discover failure prototypes via data-driven clustering, explores a million-scale image pool using these prototypes as retrieval anchors with progressive human-in-the-loop annotation, and evolves through quality-assured fine-tuning, forming a self-improving cycle. Models are evaluated on complementary perception and description tasks. An entropy-guided routing mechanism triages annotations to minimize labeling cost. Experiments across five medical imaging modalities show that MedQ-Engine elevates an 8B-parameter model to surpass GPT-4o by over 13% and narrow the gap with human experts to only 4.34%, using only 10K annotations with more than 4x sample efficiency over random sampling.
MedQ-UNI: Toward Unified Medical Image Quality Assessment and Restoration via Vision-Language Modeling
Mar 19, 2026Existing medical image restoration (Med-IR) methods are typically modality-specific or degradation-specific, failing to generalize across the heterogeneous degradations encountered in clinical practice. We argue this limitation stems from the isolation of Med-IR from medical image quality assessment (Med-IQA), as restoration models without explicit quality understanding struggle to adapt to diverse degradation types across modalities. To address these challenges, we propose MedQ-UNI, a unified vision-language model that follows an assess-then-restore paradigm, explicitly leveraging Med-IQA to guide Med-IR across arbitrary modalities and degradation types. MedQ-UNI adopts a multimodal autoregressive dual-expert architecture with shared attention: a quality assessment expert first identifies degradation issues through structured natural language descriptions, and a restoration expert then conditions on these descriptions to perform targeted image restoration. To support this paradigm, we construct a large-scale dataset of approximately 50K paired samples spanning three imaging modalities and five restoration tasks, each annotated with structured quality descriptions for joint Med-IQA and Med-IR training, along with a 2K-sample benchmark for evaluation. Extensive experiments demonstrate that a single MedQ-UNI model, without any task-specific adaptation, achieves state-of-the-art restoration performance across all tasks while generating superior descriptions, confirming that explicit quality understanding meaningfully improves restoration fidelity and interpretability.
MedQ-Deg: A Multidimensional Benchmark for Evaluating MLLMs Across Medical Image Quality Degradations
Mar 08, 2026Despite impressive performance on standard benchmarks, multimodal large language models (MLLMs) face critical challenges in real-world clinical environments where medical images inevitably suffer various quality degradations. Existing benchmarks exhibit two key limitations: (1) absence of large-scale, multidimensional assessment across medical image quality gradients and (2) no systematic confidence calibration analysis. To address these gaps, we present MedQ-Deg, a comprehensive benchmark for evaluating medical MLLMs under image quality degradations. MedQ-Deg provides multi-dimensional evaluation spanning 18 distinct degradation types, 30 fine-grained capability dimensions, and 7 imaging modalities, with 24,894 question-answer pairs. Each degradation is implemented at 3 severity degrees, calibrated by expert radiologists. We further introduce Calibration Shift metric, which quantifies the gap between a model's perceived confidence and actual performance to assess metacognitive reliability under degradation. Our comprehensive evaluation of 40 mainstream MLLMs reveals several critical findings: (1) overall model performance degrades systematically as degradation severity increases, (2) models universally exhibit the AI Dunning-Kruger Effect, maintaining inappropriately high confidence despite severe accuracy collapse, and (3) models display markedly differentiated behavioral patterns across capability dimensions, imaging modalities, and degradation types. We hope MedQ-Deg drives progress toward medical MLLMs that are robust and trustworthy in real clinical practice.
RMIT-ADM+S at the MMU-RAG NeurIPS 2025 Competition
Feb 24, 2026This paper presents the award-winning RMIT-ADM+S system for the Text-to-Text track of the NeurIPS~2025 MMU-RAG Competition. We introduce Routing-to-RAG (R2RAG), a research-focused retrieval-augmented generation (RAG) architecture composed of lightweight components that dynamically adapt the retrieval strategy based on inferred query complexity and evidence sufficiency. The system uses smaller LLMs, enabling operation on a single consumer-grade GPU while supporting complex research tasks. It builds on the G-RAG system, winner of the ACM~SIGIR~2025 LiveRAG Challenge, and extends it with modules informed by qualitative review of outputs. R2RAG won the Best Dynamic Evaluation award in the Open Source category, demonstrating high effectiveness with careful design and efficient use of resources.
MedScope: Incentivizing "Think with Videos" for Clinical Reasoning via Coarse-to-Fine Tool Calling
Feb 11, 2026Long-form clinical videos are central to visual evidence-based decision-making, with growing importance for applications such as surgical robotics and related settings. However, current multimodal large language models typically process videos with passive sampling or weakly grounded inspection, which limits their ability to iteratively locate, verify, and justify predictions with temporally targeted evidence. To close this gap, we propose MedScope, a tool-using clinical video reasoning model that performs coarse-to-fine evidence seeking over long-form procedures. By interleaving intermediate reasoning with targeted tool calls and verification on retrieved observations, MedScope produces more accurate and trustworthy predictions that are explicitly grounded in temporally localized visual evidence. To address the lack of high-fidelity supervision, we build ClinVideoSuite, an evidence-centric, fine-grained clinical video suite. We then optimize MedScope with Grounding-Aware Group Relative Policy Optimization (GA-GRPO), which directly reinforces tool use with grounding-aligned rewards and evidence-weighted advantages. On full and fine-grained video understanding benchmarks, MedScope achieves state-of-the-art performance in both in-domain and out-of-domain evaluations. Our approach illuminates a path toward medical AI agents that can genuinely "think with videos" through tool-integrated reasoning. We will release our code, models, and data.
Probing Scientific General Intelligence of LLMs with Scientist-Aligned Workflows
Dec 18, 2025Despite advances in scientific AI, a coherent framework for Scientific General Intelligence (SGI)-the ability to autonomously conceive, investigate, and reason across scientific domains-remains lacking. We present an operational SGI definition grounded in the Practical Inquiry Model (PIM: Deliberation, Conception, Action, Perception) and operationalize it via four scientist-aligned tasks: deep research, idea generation, dry/wet experiments, and experimental reasoning. SGI-Bench comprises over 1,000 expert-curated, cross-disciplinary samples inspired by Science's 125 Big Questions, enabling systematic evaluation of state-of-the-art LLMs. Results reveal gaps: low exact match (10--20%) in deep research despite step-level alignment; ideas lacking feasibility and detail; high code executability but low execution result accuracy in dry experiments; low sequence fidelity in wet protocols; and persistent multimodal comparative-reasoning challenges. We further introduce Test-Time Reinforcement Learning (TTRL), which optimizes retrieval-augmented novelty rewards at inference, enhancing hypothesis novelty without reference answer. Together, our PIM-grounded definition, workflow-centric benchmark, and empirical insights establish a foundation for AI systems that genuinely participate in scientific discovery.
MedQ-Bench: Evaluating and Exploring Medical Image Quality Assessment Abilities in MLLMs
Oct 02, 2025
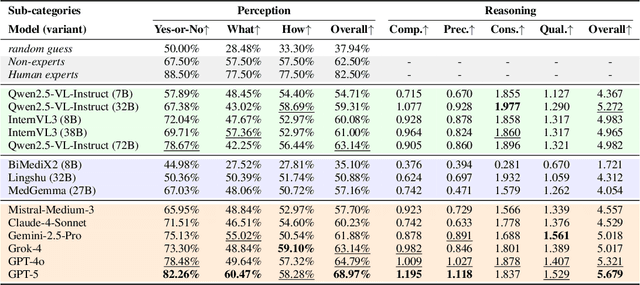
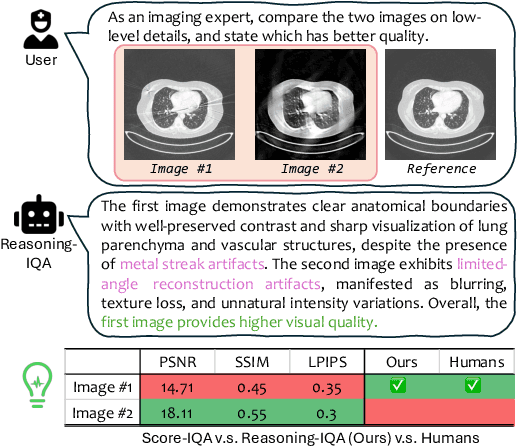

Medical Image Quality Assessment (IQA) serves as the first-mile safety gate for clinical AI, yet existing approaches remain constrained by scalar, score-based metrics and fail to reflect the descriptive, human-like reasoning process central to expert evaluation. To address this gap, we introduce MedQ-Bench, a comprehensive benchmark that establishes a perception-reasoning paradigm for language-based evaluation of medical image quality with Multi-modal Large Language Models (MLLMs). MedQ-Bench defines two complementary tasks: (1) MedQ-Perception, which probes low-level perceptual capability via human-curated questions on fundamental visual attributes; and (2) MedQ-Reasoning, encompassing both no-reference and comparison reasoning tasks, aligning model evaluation with human-like reasoning on image quality. The benchmark spans five imaging modalities and over forty quality attributes, totaling 2,600 perceptual queries and 708 reasoning assessments, covering diverse image sources including authentic clinical acquisitions, images with simulated degradations via physics-based reconstructions, and AI-generated images. To evaluate reasoning ability, we propose a multi-dimensional judging protocol that assesses model outputs along four complementary axes. We further conduct rigorous human-AI alignment validation by comparing LLM-based judgement with radiologists. Our evaluation of 14 state-of-the-art MLLMs demonstrates that models exhibit preliminary but unstable perceptual and reasoning skills, with insufficient accuracy for reliable clinical use. These findings highlight the need for targeted optimization of MLLMs in medical IQA. We hope that MedQ-Bench will catalyze further exploration and unlock the untapped potential of MLLMs for medical image quality evaluation.