 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMedP-CLIP: Medical CLIP with Region-Aware Prompt Integration
Apr 13, 2026Contrastive Language-Image Pre-training (CLIP) has demonstrated outstanding performance in global image understanding and zero-shot transfer through large-scale text-image alignment. However, the core of medical image analysis often lies in the fine-grained understanding of specific anatomical structures or lesion regions. Therefore, precisely comprehending region-of-interest (RoI) information provided by medical professionals or perception models becomes crucial. To address this need, we propose MedP-CLIP, a region-aware medical vision-language model (VLM). MedP-CLIP innovatively integrates medical prior knowledge and designs a feature-level region prompt integration mechanism, enabling it to flexibly respond to various prompt forms (e.g., points, bounding boxes, masks) while maintaining global contextual awareness when focusing on local regions. We pre-train the model on a meticulously constructed large-scale dataset (containing over 6.4 million medical images and 97.3 million region-level annotations), equipping it with cross-disease and cross-modality fine-grained spatial semantic understanding capabilities. Experiments demonstrate that MedP-CLIP significantly outperforms baseline methods in various medical tasks, including zero-shot recognition, interactive segmentation, and empowering multimodal large language models. This model provides a scalable, plug-and-play visual backbone for medical AI, combining holistic image understanding with precise regional analysis.
Project Imaging-X: A Survey of 1000+ Open-Access Medical Imaging Datasets for Foundation Model Development
Mar 29, 2026Foundation models have demonstrated remarkable success across diverse domains and tasks, primarily due to the thrive of large-scale, diverse, and high-quality datasets. However, in the field of medical imaging, the curation and assembling of such medical datasets are highly challenging due to the reliance on clinical expertise and strict ethical and privacy constraints, resulting in a scarcity of large-scale unified medical datasets and hindering the development of powerful medical foundation models. In this work, we present the largest survey to date of medical image datasets, covering over 1,000 open-access datasets with a systematic catalog of their modalities, tasks, anatomies, annotations, limitations, and potential for integration. Our analysis exposes a landscape that is modest in scale, fragmented across narrowly scoped tasks, and unevenly distributed across organs and modalities, which in turn limits the utility of existing medical image datasets for developing versatile and robust medical foundation models. To turn fragmentation into scale, we propose a metadata-driven fusion paradigm (MDFP) that integrates public datasets with shared modalities or tasks, thereby transforming multiple small data silos into larger, more coherent resources. Building on MDFP, we release an interactive discovery portal that enables end-to-end, automated medical image dataset integration, and compile all surveyed datasets into a unified, structured table that clearly summarizes their key characteristics and provides reference links, offering the community an accessible and comprehensive repository. By charting the current terrain and offering a principled path to dataset consolidation, our survey provides a practical roadmap for scaling medical imaging corpora, supporting faster data discovery, more principled dataset creation, and more capable medical foundation models.
SegMoTE: Token-Level Mixture of Experts for Medical Image Segmentation
Feb 22, 2026Medical image segmentation is vital for clinical diagnosis and quantitative analysis, yet remains challenging due to the heterogeneity of imaging modalities and the high cost of pixel-level annotations. Although general interactive segmentation models like SAM have achieved remarkable progress, their transfer to medical imaging still faces two key bottlenecks: (i) the lack of adaptive mechanisms for modality- and anatomy-specific tasks, which limits generalization in out-of-distribution medical scenarios; and (ii) current medical adaptation methods fine-tune on large, heterogeneous datasets without selection, leading to noisy supervision, higher cost, and negative transfer. To address these issues, we propose SegMoTE, an efficient and adaptive framework for medical image segmentation. SegMoTE preserves SAM's original prompt interface, efficient inference, and zero-shot generalization while introducing only a small number of learnable parameters to dynamically adapt across modalities and tasks. In addition, we design a progressive prompt tokenization mechanism that enables fully automatic segmentation, significantly reducing annotation dependence. Trained on MedSeg-HQ, a curated dataset less than 1% of existing large-scale datasets, SegMoTE achieves SOTA performance across diverse imaging modalities and anatomical tasks. It represents the first efficient, robust, and scalable adaptation of general segmentation models to the medical domain under extremely low annotation cost, advancing the practical deployment of foundation vision models in clinical applications.
A Survey of Scientific Large Language Models: From Data Foundations to Agent Frontiers
Aug 28, 2025



Scientific Large Language Models (Sci-LLMs) are transforming how knowledge is represented, integrated, and applied in scientific research, yet their progress is shaped by the complex nature of scientific data. This survey presents a comprehensive, data-centric synthesis that reframes the development of Sci-LLMs as a co-evolution between models and their underlying data substrate. We formulate a unified taxonomy of scientific data and a hierarchical model of scientific knowledge, emphasizing the multimodal, cross-scale, and domain-specific challenges that differentiate scientific corpora from general natural language processing datasets. We systematically review recent Sci-LLMs, from general-purpose foundations to specialized models across diverse scientific disciplines, alongside an extensive analysis of over 270 pre-/post-training datasets, showing why Sci-LLMs pose distinct demands -- heterogeneous, multi-scale, uncertainty-laden corpora that require representations preserving domain invariance and enabling cross-modal reasoning. On evaluation, we examine over 190 benchmark datasets and trace a shift from static exams toward process- and discovery-oriented assessments with advanced evaluation protocols. These data-centric analyses highlight persistent issues in scientific data development and discuss emerging solutions involving semi-automated annotation pipelines and expert validation. Finally, we outline a paradigm shift toward closed-loop systems where autonomous agents based on Sci-LLMs actively experiment, validate, and contribute to a living, evolving knowledge base. Collectively, this work provides a roadmap for building trustworthy, continually evolving artificial intelligence (AI) systems that function as a true partner in accelerating scientific discovery.
Enhancing LLMs' Reasoning-Intensive Multimedia Search Capabilities through Fine-Tuning and Reinforcement Learning
May 24, 2025Existing large language models (LLMs) driven search agents typically rely on prompt engineering to decouple the user queries into search plans, limiting their effectiveness in complex scenarios requiring reasoning. Furthermore, they suffer from excessive token consumption due to Python-based search plan representations and inadequate integration of multimedia elements for both input processing and response generation. To address these challenges, we introduce SearchExpert, a training method for LLMs to improve their multimedia search capabilities in response to complex search queries. Firstly, we reformulate the search plan in an efficient natural language representation to reduce token consumption. Then, we propose the supervised fine-tuning for searching (SFTS) to fine-tune LLM to adapt to these representations, together with an automated dataset construction pipeline. Secondly, to improve reasoning-intensive search capabilities, we propose the reinforcement learning from search feedback (RLSF) that takes the search results planned by LLM as the reward signals. Thirdly, we propose a multimedia understanding and generation agent that enables the fine-tuned LLM to process visual input and produce visual output during inference. Finally, we establish an automated benchmark construction pipeline and a human evaluation framework. Our resulting benchmark, SearchExpertBench-25, comprises 200 multiple-choice questions spanning financial and international news scenarios that require reasoning in searching. Experiments demonstrate that SearchExpert outperforms the commercial LLM search method (Perplexity Pro) by 36.60% on the existing FinSearchBench-24 benchmark and 54.54% on our proposed SearchExpertBench-25. Human evaluations further confirm the superior readability.
RetinaLogos: Fine-Grained Synthesis of High-Resolution Retinal Images Through Captions
May 19, 2025The scarcity of high-quality, labelled retinal imaging data, which presents a significant challenge in the development of machine learning models for ophthalmology, hinders progress in the field. To synthesise Colour Fundus Photographs (CFPs), existing methods primarily relying on predefined disease labels face significant limitations. However, current methods remain limited, thus failing to generate images for broader categories with diverse and fine-grained anatomical structures. To overcome these challenges, we first introduce an innovative pipeline that creates a large-scale, synthetic Caption-CFP dataset comprising 1.4 million entries, called RetinaLogos-1400k. Specifically, RetinaLogos-1400k uses large language models (LLMs) to describe retinal conditions and key structures, such as optic disc configuration, vascular distribution, nerve fibre layers, and pathological features. Furthermore, based on this dataset, we employ a novel three-step training framework, called RetinaLogos, which enables fine-grained semantic control over retinal images and accurately captures different stages of disease progression, subtle anatomical variations, and specific lesion types. Extensive experiments demonstrate state-of-the-art performance across multiple datasets, with 62.07% of text-driven synthetic images indistinguishable from real ones by ophthalmologists. Moreover, the synthetic data improves accuracy by 10%-25% in diabetic retinopathy grading and glaucoma detection, thereby providing a scalable solution to augment ophthalmic datasets.
GMAI-VL-R1: Harnessing Reinforcement Learning for Multimodal Medical Reasoning
Apr 02, 2025Recent advances in general medical AI have made significant strides, but existing models often lack the reasoning capabilities needed for complex medical decision-making. This paper presents GMAI-VL-R1, a multimodal medical reasoning model enhanced by reinforcement learning (RL) to improve its reasoning abilities. Through iterative training, GMAI-VL-R1 optimizes decision-making, significantly boosting diagnostic accuracy and clinical support. We also develop a reasoning data synthesis method, generating step-by-step reasoning data via rejection sampling, which further enhances the model's generalization. Experimental results show that after RL training, GMAI-VL-R1 excels in tasks such as medical image diagnosis and visual question answering. While the model demonstrates basic memorization with supervised fine-tuning, RL is crucial for true generalization. Our work establishes new evaluation benchmarks and paves the way for future advancements in medical reasoning models. Code, data, and model will be released at \href{https://github.com/uni-medical/GMAI-VL-R1}{this link}.
A Continual Learning-driven Model for Accurate and Generalizable Segmentation of Clinically Comprehensive and Fine-grained Whole-body Anatomies in CT
Mar 16, 2025Precision medicine in the quantitative management of chronic diseases and oncology would be greatly improved if the Computed Tomography (CT) scan of any patient could be segmented, parsed and analyzed in a precise and detailed way. However, there is no such fully annotated CT dataset with all anatomies delineated for training because of the exceptionally high manual cost, the need for specialized clinical expertise, and the time required to finish the task. To this end, we proposed a novel continual learning-driven CT model that can segment complete anatomies presented using dozens of previously partially labeled datasets, dynamically expanding its capacity to segment new ones without compromising previously learned organ knowledge. Existing multi-dataset approaches are not able to dynamically segment new anatomies without catastrophic forgetting and would encounter optimization difficulty or infeasibility when segmenting hundreds of anatomies across the whole range of body regions. Our single unified CT segmentation model, CL-Net, can highly accurately segment a clinically comprehensive set of 235 fine-grained whole-body anatomies. Composed of a universal encoder, multiple optimized and pruned decoders, CL-Net is developed using 13,952 CT scans from 20 public and 16 private high-quality partially labeled CT datasets of various vendors, different contrast phases, and pathologies. Extensive evaluation demonstrates that CL-Net consistently outperforms the upper limit of an ensemble of 36 specialist nnUNets trained per dataset with the complexity of 5% model size and significantly surpasses the segmentation accuracy of recent leading Segment Anything-style medical image foundation models by large margins. Our continual learning-driven CL-Net model would lay a solid foundation to facilitate many downstream tasks of oncology and chronic diseases using the most widely adopted CT imaging.
From Slices to Sequences: Autoregressive Tracking Transformer for Cohesive and Consistent 3D Lymph Node Detection in CT Scans
Mar 11, 2025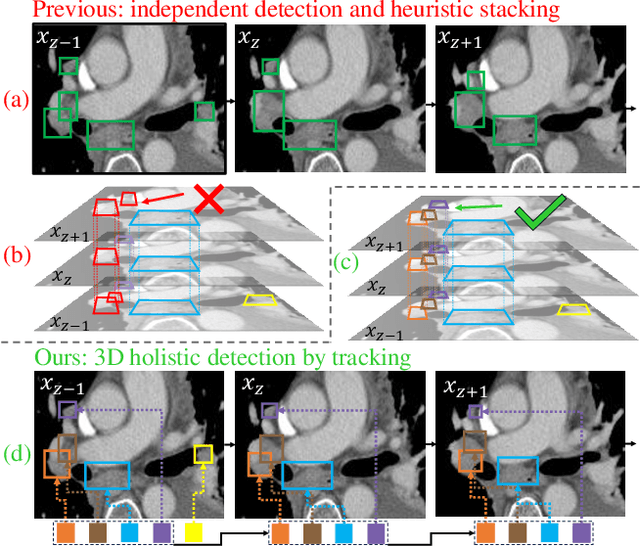

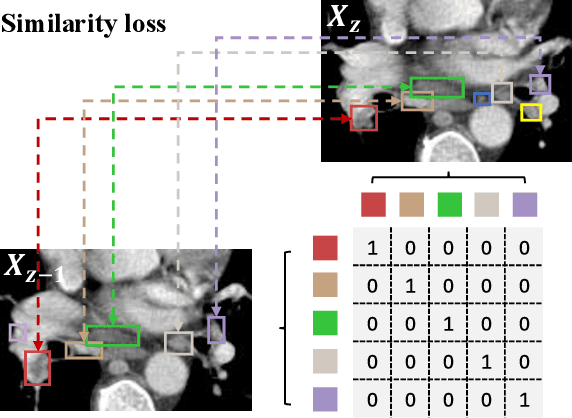
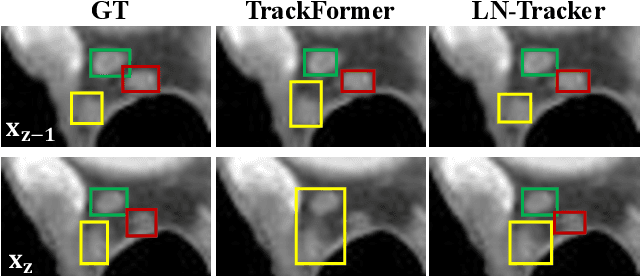
Lymph node (LN) assessment is an essential task in the routine radiology workflow, providing valuable insights for cancer staging, treatment planning and beyond. Identifying scatteredly-distributed and low-contrast LNs in 3D CT scans is highly challenging, even for experienced clinicians. Previous lesion and LN detection methods demonstrate effectiveness of 2.5D approaches (i.e, using 2D network with multi-slice inputs), leveraging pretrained 2D model weights and showing improved accuracy as compared to separate 2D or 3D detectors. However, slice-based 2.5D detectors do not explicitly model inter-slice consistency for LN as a 3D object, requiring heuristic post-merging steps to generate final 3D LN instances, which can involve tuning a set of parameters for each dataset. In this work, we formulate 3D LN detection as a tracking task and propose LN-Tracker, a novel LN tracking transformer, for joint end-to-end detection and 3D instance association. Built upon DETR-based detector, LN-Tracker decouples transformer decoder's query into the track and detection groups, where the track query autoregressively follows previously tracked LN instances along the z-axis of a CT scan. We design a new transformer decoder with masked attention module to align track query's content to the context of current slice, meanwhile preserving detection query's high accuracy in current slice. An inter-slice similarity loss is introduced to encourage cohesive LN association between slices. Extensive evaluation on four lymph node datasets shows LN-Tracker's superior performance, with at least 2.7% gain in average sensitivity when compared to other top 3D/2.5D detectors. Further validation on public lung nodule and prostate tumor detection tasks confirms the generalizability of LN-Tracker as it achieves top performance on both tasks. Datasets will be released upon acceptance.
Towards Effective and Efficient Context-aware Nucleus Detection in Histopathology Whole Slide Images
Mar 04, 2025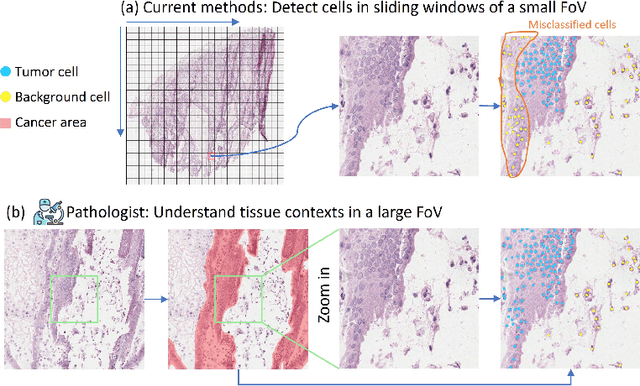
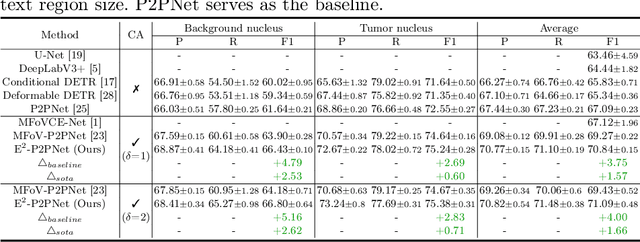
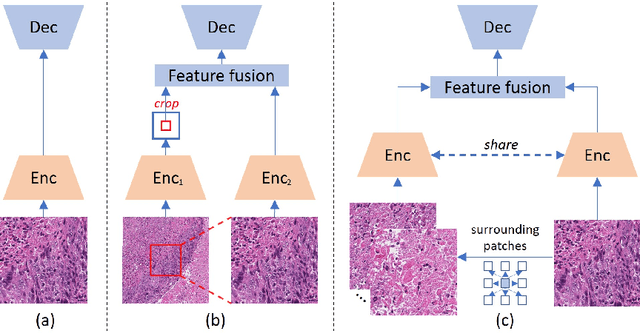
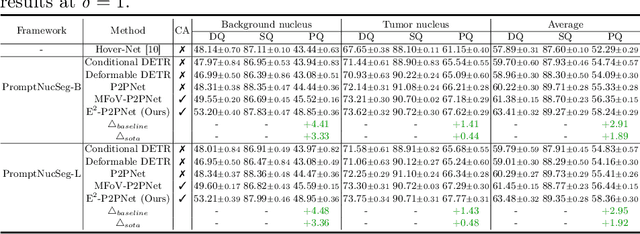
Nucleus detection in histopathology whole slide images (WSIs) is crucial for a broad spectrum of clinical applications. Current approaches for nucleus detection in gigapixel WSIs utilize a sliding window methodology, which overlooks boarder contextual information (eg, tissue structure) and easily leads to inaccurate predictions. To address this problem, recent studies additionally crops a large Filed-of-View (FoV) region around each sliding window to extract contextual features. However, such methods substantially increases the inference latency. In this paper, we propose an effective and efficient context-aware nucleus detection algorithm. Specifically, instead of leveraging large FoV regions, we aggregate contextual clues from off-the-shelf features of historically visited sliding windows. This design greatly reduces computational overhead. Moreover, compared to large FoV regions at a low magnification, the sliding window patches have higher magnification and provide finer-grained tissue details, thereby enhancing the detection accuracy. To further improve the efficiency, we propose a grid pooling technique to compress dense feature maps of each patch into a few contextual tokens. Finally, we craft OCELOT-seg, the first benchmark dedicated to context-aware nucleus instance segmentation. Code, dataset, and model checkpoints will be available at https://github.com/windygoo/PathContext.