 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInteractive Medical Image Segmentation: A Benchmark Dataset and Baseline
Nov 19, 2024Interactive Medical Image Segmentation (IMIS) has long been constrained by the limited availability of large-scale, diverse, and densely annotated datasets, which hinders model generalization and consistent evaluation across different models. In this paper, we introduce the IMed-361M benchmark dataset, a significant advancement in general IMIS research. First, we collect and standardize over 6.4 million medical images and their corresponding ground truth masks from multiple data sources. Then, leveraging the strong object recognition capabilities of a vision foundational model, we automatically generated dense interactive masks for each image and ensured their quality through rigorous quality control and granularity management. Unlike previous datasets, which are limited by specific modalities or sparse annotations, IMed-361M spans 14 modalities and 204 segmentation targets, totaling 361 million masks-an average of 56 masks per image. Finally, we developed an IMIS baseline network on this dataset that supports high-quality mask generation through interactive inputs, including clicks, bounding boxes, text prompts, and their combinations. We evaluate its performance on medical image segmentation tasks from multiple perspectives, demonstrating superior accuracy and scalability compared to existing interactive segmentation models. To facilitate research on foundational models in medical computer vision, we release the IMed-361M and model at https://github.com/uni-medical/IMIS-Bench.
SAM-Med3D-MoE: Towards a Non-Forgetting Segment Anything Model via Mixture of Experts for 3D Medical Image Segmentation
Jul 06, 2024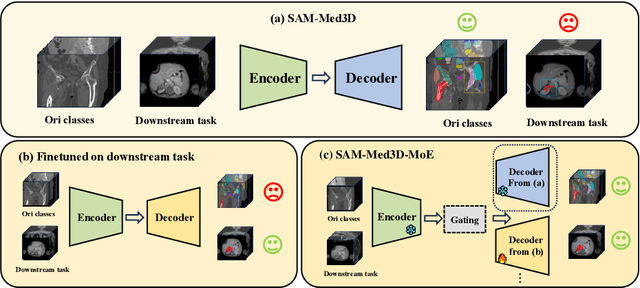

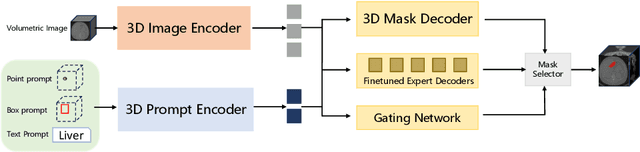

Volumetric medical image segmentation is pivotal in enhancing disease diagnosis, treatment planning, and advancing medical research. While existing volumetric foundation models for medical image segmentation, such as SAM-Med3D and SegVol, have shown remarkable performance on general organs and tumors, their ability to segment certain categories in clinical downstream tasks remains limited. Supervised Finetuning (SFT) serves as an effective way to adapt such foundation models for task-specific downstream tasks but at the cost of degrading the general knowledge previously stored in the original foundation model.To address this, we propose SAM-Med3D-MoE, a novel framework that seamlessly integrates task-specific finetuned models with the foundational model, creating a unified model at minimal additional training expense for an extra gating network. This gating network, in conjunction with a selection strategy, allows the unified model to achieve comparable performance of the original models in their respective tasks both general and specialized without updating any parameters of them.Our comprehensive experiments demonstrate the efficacy of SAM-Med3D-MoE, with an average Dice performance increase from 53 to 56.4 on 15 specific classes. It especially gets remarkable gains of 29.6, 8.5, 11.2 on the spinal cord, esophagus, and right hip, respectively. Additionally, it achieves 48.9 Dice on the challenging SPPIN2023 Challenge, significantly surpassing the general expert's performance of 32.3. We anticipate that SAM-Med3D-MoE can serve as a new framework for adapting the foundation model to specific areas in medical image analysis. Codes and datasets will be publicly available.
SA-Med2D-20M Dataset: Segment Anything in 2D Medical Imaging with 20 Million masks
Nov 20, 2023



Segment Anything Model (SAM) has achieved impressive results for natural image segmentation with input prompts such as points and bounding boxes. Its success largely owes to massive labeled training data. However, directly applying SAM to medical image segmentation cannot perform well because SAM lacks medical knowledge -- it does not use medical images for training. To incorporate medical knowledge into SAM, we introduce SA-Med2D-20M, a large-scale segmentation dataset of 2D medical images built upon numerous public and private datasets. It consists of 4.6 million 2D medical images and 19.7 million corresponding masks, covering almost the whole body and showing significant diversity. This paper describes all the datasets collected in SA-Med2D-20M and details how to process these datasets. Furthermore, comprehensive statistics of SA-Med2D-20M are presented to facilitate the better use of our dataset, which can help the researchers build medical vision foundation models or apply their models to downstream medical applications. We hope that the large scale and diversity of SA-Med2D-20M can be leveraged to develop medical artificial intelligence for enhancing diagnosis, medical image analysis, knowledge sharing, and education. The data with the redistribution license is publicly available at https://github.com/OpenGVLab/SAM-Med2D.
SAM-Med3D
Oct 29, 2023



Although the Segment Anything Model (SAM) has demonstrated impressive performance in 2D natural image segmentation, its application to 3D volumetric medical images reveals significant shortcomings, namely suboptimal performance and unstable prediction, necessitating an excessive number of prompt points to attain the desired outcomes. These issues can hardly be addressed by fine-tuning SAM on medical data because the original 2D structure of SAM neglects 3D spatial information. In this paper, we introduce SAM-Med3D, the most comprehensive study to modify SAM for 3D medical images. Our approach is characterized by its comprehensiveness in two primary aspects: firstly, by comprehensively reformulating SAM to a thorough 3D architecture trained on a comprehensively processed large-scale volumetric medical dataset; and secondly, by providing a comprehensive evaluation of its performance. Specifically, we train SAM-Med3D with over 131K 3D masks and 247 categories. Our SAM-Med3D excels at capturing 3D spatial information, exhibiting competitive performance with significantly fewer prompt points than the top-performing fine-tuned SAM in the medical domain. We then evaluate its capabilities across 15 datasets and analyze it from multiple perspectives, including anatomical structures, modalities, targets, and generalization abilities. Our approach, compared with SAM, showcases pronouncedly enhanced efficiency and broad segmentation capabilities for 3D volumetric medical images. Our code is released at https://github.com/uni-medical/SAM-Med3D.
A-Eval: A Benchmark for Cross-Dataset Evaluation of Abdominal Multi-Organ Segmentation
Sep 07, 2023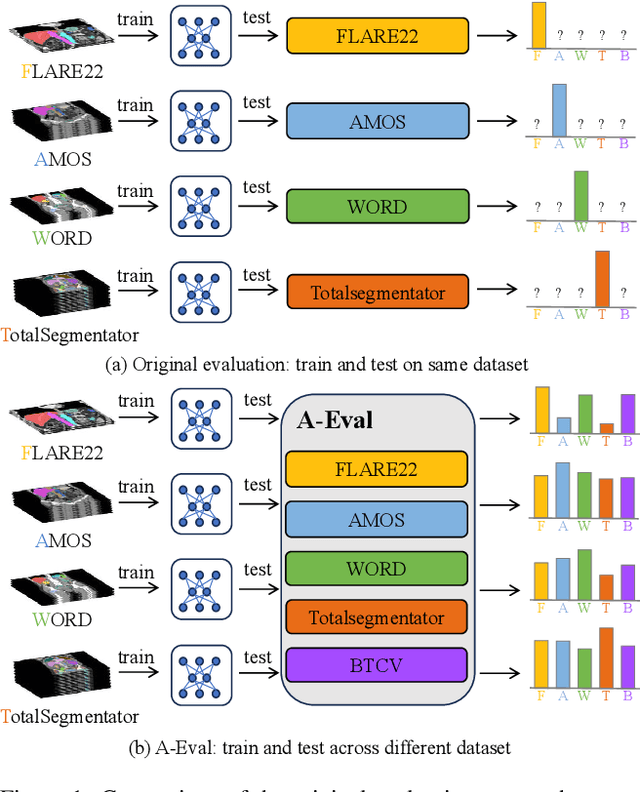
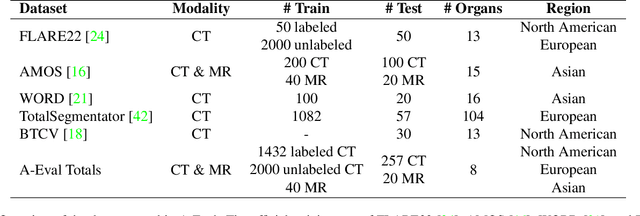

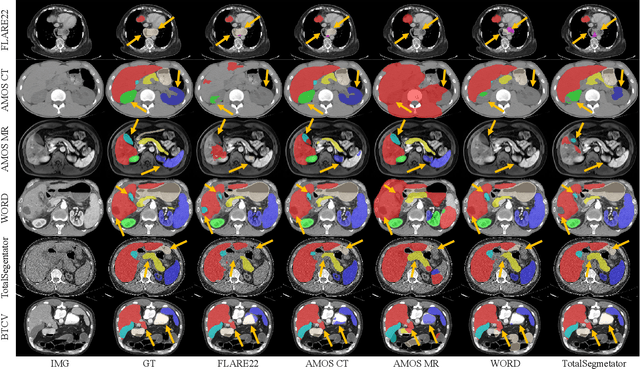
Although deep learning have revolutionized abdominal multi-organ segmentation, models often struggle with generalization due to training on small, specific datasets. With the recent emergence of large-scale datasets, some important questions arise: \textbf{Can models trained on these datasets generalize well on different ones? If yes/no, how to further improve their generalizability?} To address these questions, we introduce A-Eval, a benchmark for the cross-dataset Evaluation ('Eval') of Abdominal ('A') multi-organ segmentation. We employ training sets from four large-scale public datasets: FLARE22, AMOS, WORD, and TotalSegmentator, each providing extensive labels for abdominal multi-organ segmentation. For evaluation, we incorporate the validation sets from these datasets along with the training set from the BTCV dataset, forming a robust benchmark comprising five distinct datasets. We evaluate the generalizability of various models using the A-Eval benchmark, with a focus on diverse data usage scenarios: training on individual datasets independently, utilizing unlabeled data via pseudo-labeling, mixing different modalities, and joint training across all available datasets. Additionally, we explore the impact of model sizes on cross-dataset generalizability. Through these analyses, we underline the importance of effective data usage in enhancing models' generalization capabilities, offering valuable insights for assembling large-scale datasets and improving training strategies. The code and pre-trained models are available at \href{https://github.com/uni-medical/A-Eval}{https://github.com/uni-medical/A-Eval}.
SAM-Med2D
Aug 30, 2023



The Segment Anything Model (SAM) represents a state-of-the-art research advancement in natural image segmentation, achieving impressive results with input prompts such as points and bounding boxes. However, our evaluation and recent research indicate that directly applying the pretrained SAM to medical image segmentation does not yield satisfactory performance. This limitation primarily arises from significant domain gap between natural images and medical images. To bridge this gap, we introduce SAM-Med2D, the most comprehensive studies on applying SAM to medical 2D images. Specifically, we first collect and curate approximately 4.6M images and 19.7M masks from public and private datasets, constructing a large-scale medical image segmentation dataset encompassing various modalities and objects. Then, we comprehensively fine-tune SAM on this dataset and turn it into SAM-Med2D. Unlike previous methods that only adopt bounding box or point prompts as interactive segmentation approach, we adapt SAM to medical image segmentation through more comprehensive prompts involving bounding boxes, points, and masks. We additionally fine-tune the encoder and decoder of the original SAM to obtain a well-performed SAM-Med2D, leading to the most comprehensive fine-tuning strategies to date. Finally, we conducted a comprehensive evaluation and analysis to investigate the performance of SAM-Med2D in medical image segmentation across various modalities, anatomical structures, and organs. Concurrently, we validated the generalization capability of SAM-Med2D on 9 datasets from MICCAI 2023 challenge. Overall, our approach demonstrated significantly superior performance and generalization capability compared to SAM.
SegNetr: Rethinking the local-global interactions and skip connections in U-shaped networks
Jul 21, 2023


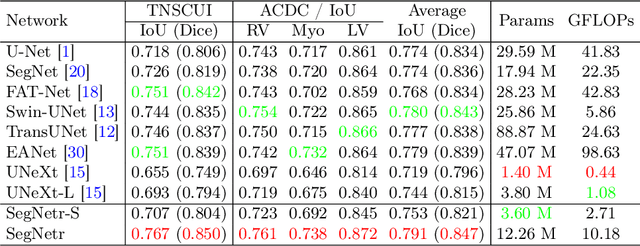
Recently, U-shaped networks have dominated the field of medical image segmentation due to their simple and easily tuned structure. However, existing U-shaped segmentation networks: 1) mostly focus on designing complex self-attention modules to compensate for the lack of long-term dependence based on convolution operation, which increases the overall number of parameters and computational complexity of the network; 2) simply fuse the features of encoder and decoder, ignoring the connection between their spatial locations. In this paper, we rethink the above problem and build a lightweight medical image segmentation network, called SegNetr. Specifically, we introduce a novel SegNetr block that can perform local-global interactions dynamically at any stage and with only linear complexity. At the same time, we design a general information retention skip connection (IRSC) to preserve the spatial location information of encoder features and achieve accurate fusion with the decoder features. We validate the effectiveness of SegNetr on four mainstream medical image segmentation datasets, with 59\% and 76\% fewer parameters and GFLOPs than vanilla U-Net, while achieving segmentation performance comparable to state-of-the-art methods. Notably, the components proposed in this paper can be applied to other U-shaped networks to improve their segmentation performance.
PL-Net: Progressive Learning Network for Medical Image Segmentation
Oct 27, 2021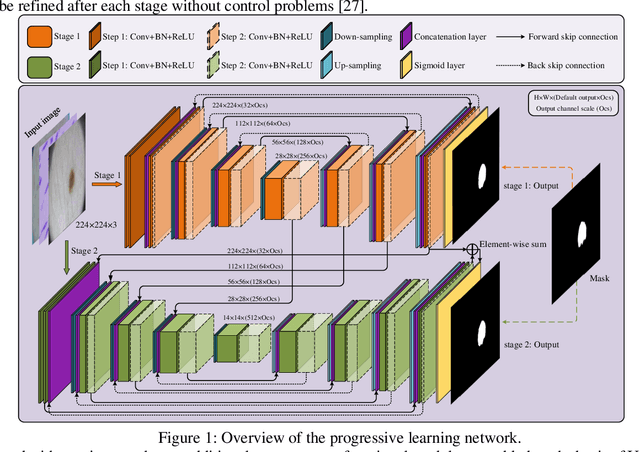
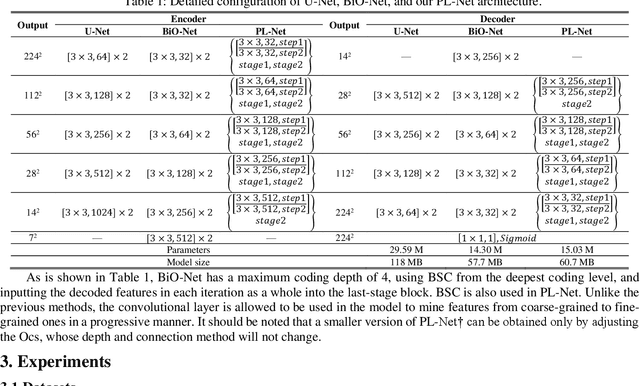
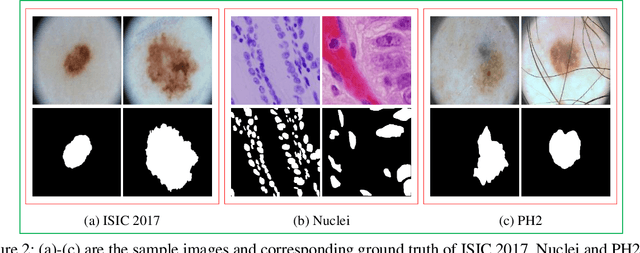
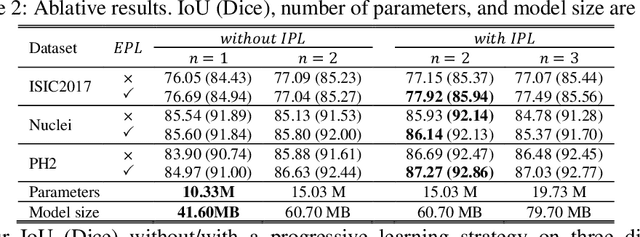
In recent years, segmentation methods based on deep convolutional neural networks (CNNs) have made state-of-the-art achievements for many medical analysis tasks. However, most of these approaches improve performance by optimizing the structure or adding new functional modules of the U-Net, which ignoring the complementation and fusion of the coarse-grained and fine-grained semantic information. To solve the above problems, we propose a medical image segmentation framework called progressive learning network (PL-Net), which includes internal progressive learning (IPL) and external progressive learning (EPL). PL-Net has the following advantages: (1) IPL divides feature extraction into two "steps", which can mix different size receptive fields and capture semantic information from coarse to fine granularity without introducing additional parameters; (2) EPL divides the training process into two "stages" to optimize parameters, and realizes the fusion of coarse-grained information in the previous stage and fine-grained information in the latter stage. We evaluate our method in different medical image analysis tasks, and the results show that the segmentation performance of PL-Net is better than the state-of-the-art methods of U-Net and its variants.
Deep learning-based person re-identification methods: A survey and outlook of recent works
Oct 16, 2021



In recent years, with the increasing demand for public safety and the rapid development of intelligent surveillance networks, person re-identification (Re-ID) has become one of the hot research topics in the field of computer vision. The main research goal of person Re-ID is to retrieve persons with the same identity from different cameras. However, traditional person Re-ID methods require manual marking of person targets, which consumes a lot of labor cost. With the widespread application of deep neural networks in the field of computer vision, a large number of deep learning-based person Re-ID methods have emerged. Therefore, this paper is to facilitate researchers to better understand the latest research results and the future trends in the field. Firstly, we summarize the main study of several recently published person re-identification surveys and try to fill the gaps between them. Secondly, We propose a multi-dimensional taxonomy to categorize the most current deep learning-based person Re-ID methods according to different characteristics, including methods for deep metric learning, local feature learning, generate adversarial networks, sequence feature learning and graph convolutional networks. Furthermore, we subdivide the above five categories according to their technique types, discussing and comparing the experimental performance of part subcategories. Finally, we conclude this paper and discuss future research directions for person Re-ID.