 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSA-Med2D-20M Dataset: Segment Anything in 2D Medical Imaging with 20 Million masks
Nov 20, 2023



Segment Anything Model (SAM) has achieved impressive results for natural image segmentation with input prompts such as points and bounding boxes. Its success largely owes to massive labeled training data. However, directly applying SAM to medical image segmentation cannot perform well because SAM lacks medical knowledge -- it does not use medical images for training. To incorporate medical knowledge into SAM, we introduce SA-Med2D-20M, a large-scale segmentation dataset of 2D medical images built upon numerous public and private datasets. It consists of 4.6 million 2D medical images and 19.7 million corresponding masks, covering almost the whole body and showing significant diversity. This paper describes all the datasets collected in SA-Med2D-20M and details how to process these datasets. Furthermore, comprehensive statistics of SA-Med2D-20M are presented to facilitate the better use of our dataset, which can help the researchers build medical vision foundation models or apply their models to downstream medical applications. We hope that the large scale and diversity of SA-Med2D-20M can be leveraged to develop medical artificial intelligence for enhancing diagnosis, medical image analysis, knowledge sharing, and education. The data with the redistribution license is publicly available at https://github.com/OpenGVLab/SAM-Med2D.
SAM-Med3D
Oct 29, 2023



Although the Segment Anything Model (SAM) has demonstrated impressive performance in 2D natural image segmentation, its application to 3D volumetric medical images reveals significant shortcomings, namely suboptimal performance and unstable prediction, necessitating an excessive number of prompt points to attain the desired outcomes. These issues can hardly be addressed by fine-tuning SAM on medical data because the original 2D structure of SAM neglects 3D spatial information. In this paper, we introduce SAM-Med3D, the most comprehensive study to modify SAM for 3D medical images. Our approach is characterized by its comprehensiveness in two primary aspects: firstly, by comprehensively reformulating SAM to a thorough 3D architecture trained on a comprehensively processed large-scale volumetric medical dataset; and secondly, by providing a comprehensive evaluation of its performance. Specifically, we train SAM-Med3D with over 131K 3D masks and 247 categories. Our SAM-Med3D excels at capturing 3D spatial information, exhibiting competitive performance with significantly fewer prompt points than the top-performing fine-tuned SAM in the medical domain. We then evaluate its capabilities across 15 datasets and analyze it from multiple perspectives, including anatomical structures, modalities, targets, and generalization abilities. Our approach, compared with SAM, showcases pronouncedly enhanced efficiency and broad segmentation capabilities for 3D volumetric medical images. Our code is released at https://github.com/uni-medical/SAM-Med3D.
A-Eval: A Benchmark for Cross-Dataset Evaluation of Abdominal Multi-Organ Segmentation
Sep 07, 2023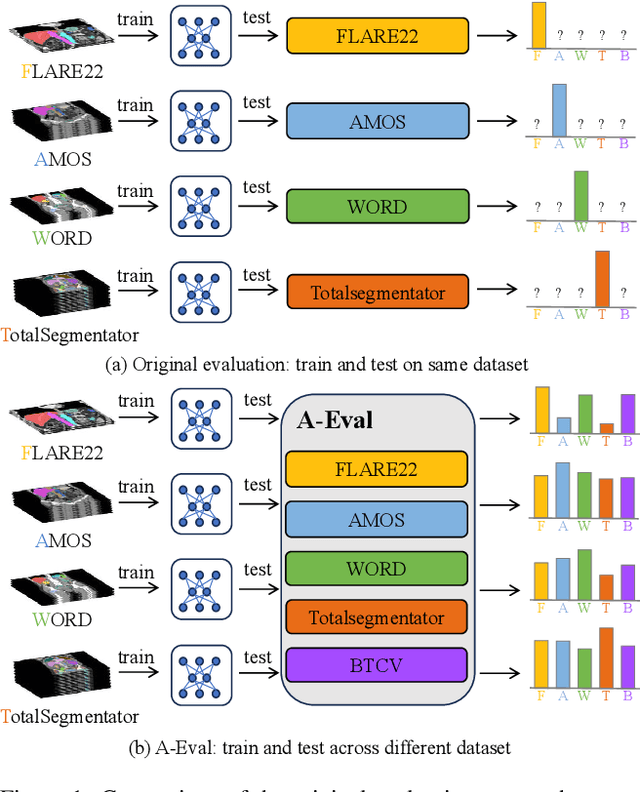
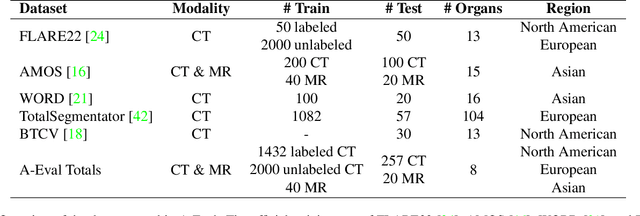

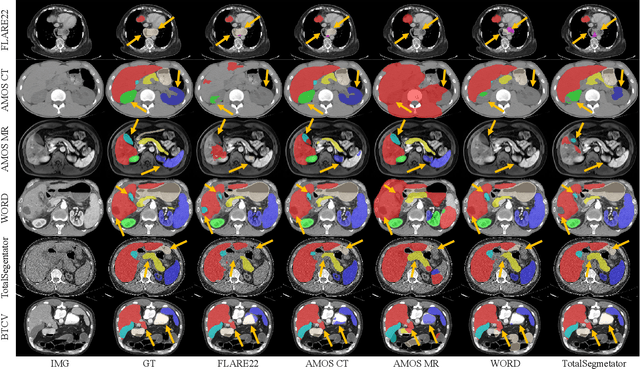
Although deep learning have revolutionized abdominal multi-organ segmentation, models often struggle with generalization due to training on small, specific datasets. With the recent emergence of large-scale datasets, some important questions arise: \textbf{Can models trained on these datasets generalize well on different ones? If yes/no, how to further improve their generalizability?} To address these questions, we introduce A-Eval, a benchmark for the cross-dataset Evaluation ('Eval') of Abdominal ('A') multi-organ segmentation. We employ training sets from four large-scale public datasets: FLARE22, AMOS, WORD, and TotalSegmentator, each providing extensive labels for abdominal multi-organ segmentation. For evaluation, we incorporate the validation sets from these datasets along with the training set from the BTCV dataset, forming a robust benchmark comprising five distinct datasets. We evaluate the generalizability of various models using the A-Eval benchmark, with a focus on diverse data usage scenarios: training on individual datasets independently, utilizing unlabeled data via pseudo-labeling, mixing different modalities, and joint training across all available datasets. Additionally, we explore the impact of model sizes on cross-dataset generalizability. Through these analyses, we underline the importance of effective data usage in enhancing models' generalization capabilities, offering valuable insights for assembling large-scale datasets and improving training strategies. The code and pre-trained models are available at \href{https://github.com/uni-medical/A-Eval}{https://github.com/uni-medical/A-Eval}.
SAM-Med2D
Aug 30, 2023



The Segment Anything Model (SAM) represents a state-of-the-art research advancement in natural image segmentation, achieving impressive results with input prompts such as points and bounding boxes. However, our evaluation and recent research indicate that directly applying the pretrained SAM to medical image segmentation does not yield satisfactory performance. This limitation primarily arises from significant domain gap between natural images and medical images. To bridge this gap, we introduce SAM-Med2D, the most comprehensive studies on applying SAM to medical 2D images. Specifically, we first collect and curate approximately 4.6M images and 19.7M masks from public and private datasets, constructing a large-scale medical image segmentation dataset encompassing various modalities and objects. Then, we comprehensively fine-tune SAM on this dataset and turn it into SAM-Med2D. Unlike previous methods that only adopt bounding box or point prompts as interactive segmentation approach, we adapt SAM to medical image segmentation through more comprehensive prompts involving bounding boxes, points, and masks. We additionally fine-tune the encoder and decoder of the original SAM to obtain a well-performed SAM-Med2D, leading to the most comprehensive fine-tuning strategies to date. Finally, we conducted a comprehensive evaluation and analysis to investigate the performance of SAM-Med2D in medical image segmentation across various modalities, anatomical structures, and organs. Concurrently, we validated the generalization capability of SAM-Med2D on 9 datasets from MICCAI 2023 challenge. Overall, our approach demonstrated significantly superior performance and generalization capability compared to SAM.