 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA-Eval: A Benchmark for Cross-Dataset Evaluation of Abdominal Multi-Organ Segmentation
Paper and Code
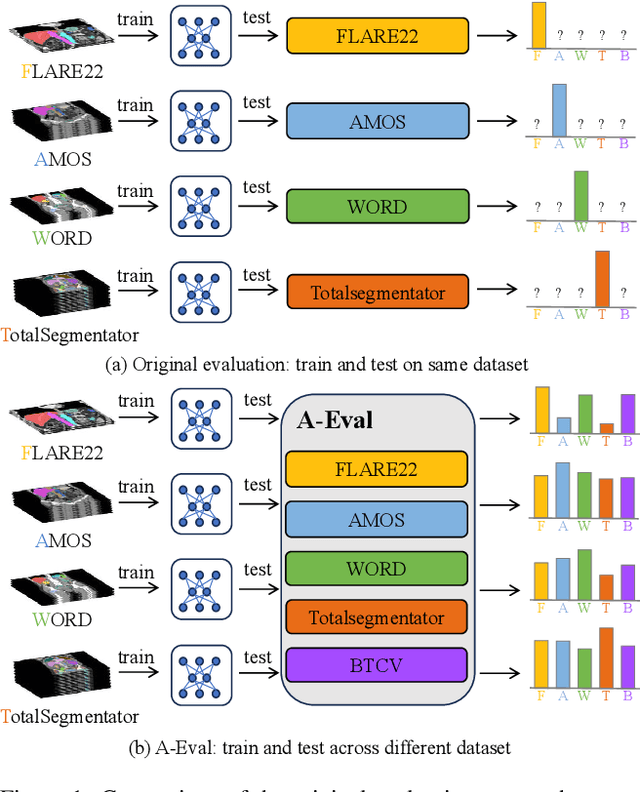
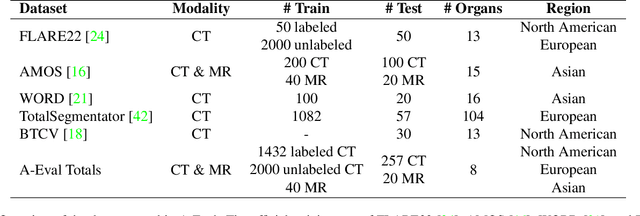

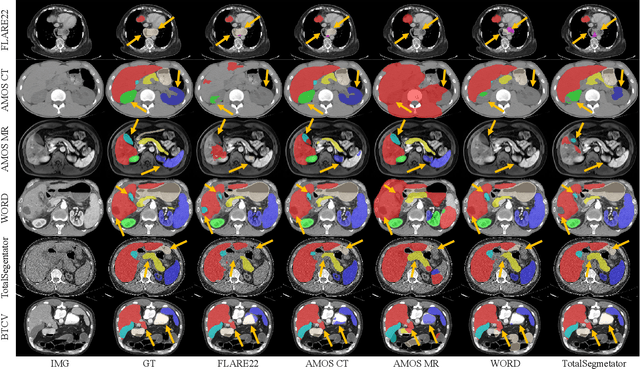
Although deep learning have revolutionized abdominal multi-organ segmentation, models often struggle with generalization due to training on small, specific datasets. With the recent emergence of large-scale datasets, some important questions arise: \textbf{Can models trained on these datasets generalize well on different ones? If yes/no, how to further improve their generalizability?} To address these questions, we introduce A-Eval, a benchmark for the cross-dataset Evaluation ('Eval') of Abdominal ('A') multi-organ segmentation. We employ training sets from four large-scale public datasets: FLARE22, AMOS, WORD, and TotalSegmentator, each providing extensive labels for abdominal multi-organ segmentation. For evaluation, we incorporate the validation sets from these datasets along with the training set from the BTCV dataset, forming a robust benchmark comprising five distinct datasets. We evaluate the generalizability of various models using the A-Eval benchmark, with a focus on diverse data usage scenarios: training on individual datasets independently, utilizing unlabeled data via pseudo-labeling, mixing different modalities, and joint training across all available datasets. Additionally, we explore the impact of model sizes on cross-dataset generalizability. Through these analyses, we underline the importance of effective data usage in enhancing models' generalization capabilities, offering valuable insights for assembling large-scale datasets and improving training strategies. The code and pre-trained models are available at \href{https://github.com/uni-medical/A-Eval}{https://github.com/uni-medical/A-Eval}.