 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Synergy Scoring Filter for Unsupervised Anomaly Detection with Noisy Data
Feb 19, 2025Noise-inclusive fully unsupervised anomaly detection (FUAD) holds significant practical relevance. Although various methods exist to address this problem, they are limited in both performance and scalability. Our work seeks to overcome these obstacles, enabling broader adaptability of unsupervised anomaly detection (UAD) models to FUAD. To achieve this, we introduce the Synergy Scoring Filter (SSFilter), the first fully unsupervised anomaly detection approach to leverage sample-level filtering. SSFilter facilitates end-to-end robust training and applies filtering to the complete training set post-training, offering a model-agnostic solution for FUAD. Specifically, SSFilter integrates a batch-level anomaly scoring mechanism based on mutual patch comparison and utilizes regression errors in anomalous regions, alongside prediction uncertainty, to estimate sample-level uncertainty scores that calibrate the anomaly scoring mechanism. This design produces a synergistic, robust filtering approach. Furthermore, we propose a realistic anomaly synthesis method and an integrity enhancement strategy to improve model training and mitigate missed noisy samples. Our method establishes state-of-the-art performance on the FUAD benchmark of the recent large-scale industrial anomaly detection dataset, Real-IAD. Additionally, dataset-level filtering enhances the performance of various UAD methods on the FUAD benchmark, and the high scalability of our approach significantly boosts its practical applicability.
MiniMaxAD: A Lightweight Autoencoder for Feature-Rich Anomaly Detection
May 16, 2024
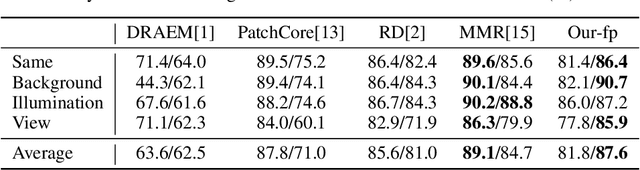
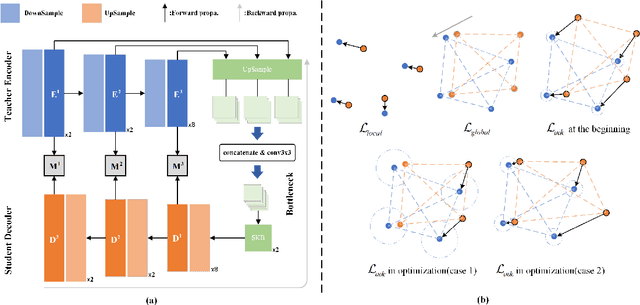

Previous unsupervised anomaly detection (UAD) methods often struggle with significant intra-class diversity; i.e., a class in a dataset contains multiple subclasses, which we categorize as Feature-Rich Anomaly Detection Datasets (FRADs). This is evident in applications such as unified setting and unmanned supermarket scenarios. To address this challenge, we developed MiniMaxAD: a lightweight autoencoder designed to efficiently compress and memorize extensive information from normal images. Our model utilizes a large kernel convolutional network equipped with a Global Response Normalization (GRN) unit and employs a multi-scale feature reconstruction strategy. The GRN unit significantly increases the upper limit of the network's capacity, while the large kernel convolution facilitates the extraction of highly abstract patterns, leading to compact normal feature modeling. Additionally, we introduce an Adaptive Contraction Loss (ADCLoss), tailored to FRADs to overcome the limitations of global cosine distance loss. MiniMaxAD was comprehensively tested across six challenging UAD benchmarks, achieving state-of-the-art results in four and highly competitive outcomes in the remaining two. Notably, our model achieved a detection AUROC of up to 97.0\% in ViSA under the unified setting. Moreover, it not only achieved state-of-the-art performance in unmanned supermarket tasks but also exhibited an inference speed 37 times faster than the previous best method, demonstrating its effectiveness in complex UAD tasks.
VideoPro: A Visual Analytics Approach for Interactive Video Programming
Aug 01, 2023


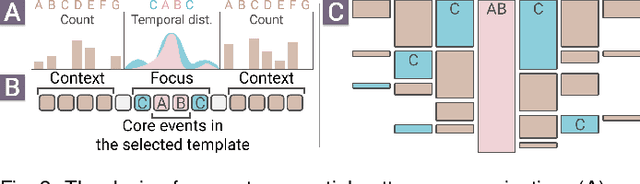
Constructing supervised machine learning models for real-world video analysis require substantial labeled data, which is costly to acquire due to scarce domain expertise and laborious manual inspection. While data programming shows promise in generating labeled data at scale with user-defined labeling functions, the high dimensional and complex temporal information in videos poses additional challenges for effectively composing and evaluating labeling functions. In this paper, we propose VideoPro, a visual analytics approach to support flexible and scalable video data programming for model steering with reduced human effort. We first extract human-understandable events from videos using computer vision techniques and treat them as atomic components of labeling functions. We further propose a two-stage template mining algorithm that characterizes the sequential patterns of these events to serve as labeling function templates for efficient data labeling. The visual interface of VideoPro facilitates multifaceted exploration, examination, and application of the labeling templates, allowing for effective programming of video data at scale. Moreover, users can monitor the impact of programming on model performance and make informed adjustments during the iterative programming process. We demonstrate the efficiency and effectiveness of our approach with two case studies and expert interviews.
SegNetr: Rethinking the local-global interactions and skip connections in U-shaped networks
Jul 21, 2023


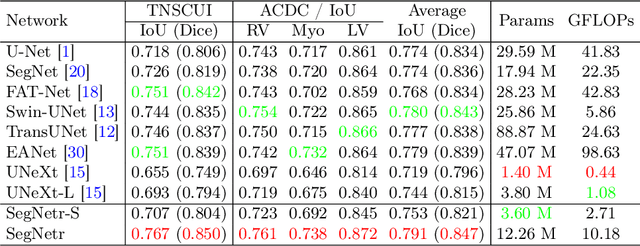
Recently, U-shaped networks have dominated the field of medical image segmentation due to their simple and easily tuned structure. However, existing U-shaped segmentation networks: 1) mostly focus on designing complex self-attention modules to compensate for the lack of long-term dependence based on convolution operation, which increases the overall number of parameters and computational complexity of the network; 2) simply fuse the features of encoder and decoder, ignoring the connection between their spatial locations. In this paper, we rethink the above problem and build a lightweight medical image segmentation network, called SegNetr. Specifically, we introduce a novel SegNetr block that can perform local-global interactions dynamically at any stage and with only linear complexity. At the same time, we design a general information retention skip connection (IRSC) to preserve the spatial location information of encoder features and achieve accurate fusion with the decoder features. We validate the effectiveness of SegNetr on four mainstream medical image segmentation datasets, with 59\% and 76\% fewer parameters and GFLOPs than vanilla U-Net, while achieving segmentation performance comparable to state-of-the-art methods. Notably, the components proposed in this paper can be applied to other U-shaped networks to improve their segmentation performance.
Global-Local Dynamic Feature Alignment Network for Person Re-Identification
Sep 13, 2021
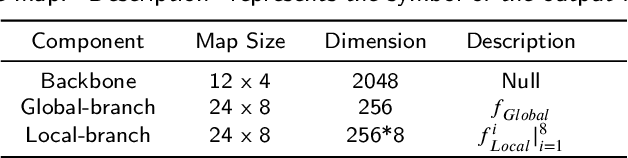
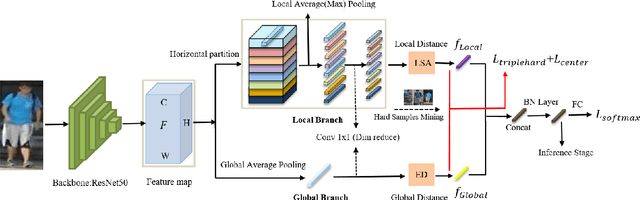
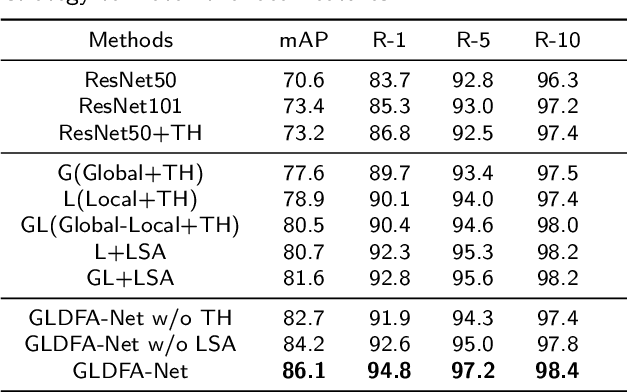
The misalignment of human images caused by pedestrian detection bounding box errors or partial occlusions is one of the main challenges in person Re-Identification (Re-ID) tasks. Previous local-based methods mainly focus on learning local features in predefined semantic regions of pedestrians, usually use local hard alignment methods or introduce auxiliary information such as key human pose points to match local features. These methods are often not applicable when large scene differences are encountered. Targeting to solve these problems, we propose a simple and efficient Local Sliding Alignment (LSA) strategy to dynamically align the local features of two images by setting a sliding window on the local stripes of the pedestrian. LSA can effectively suppress spatial misalignment and does not need to introduce extra supervision information. Then, we design a Global-Local Dynamic Feature Alignment Network (GLDFA-Net) framework, which contains both global and local branches. We introduce LSA into the local branch of GLDFA-Net to guide the computation of distance metrics, which can further improve the accuracy of the testing phase. Evaluation experiments on several mainstream evaluation datasets including Market-1501, DukeMTMC-reID, and CUHK03 show that our method has competitive accuracy over the several state-of-the-art person Re-ID methods. Additionally, it achieves 86.1% mAP and 94.8% Rank-1 accuracy on Market1501.