 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNTIRE 2025 Image Shadow Removal Challenge Report
Jun 18, 2025



This work examines the findings of the NTIRE 2025 Shadow Removal Challenge. A total of 306 participants have registered, with 17 teams successfully submitting their solutions during the final evaluation phase. Following the last two editions, this challenge had two evaluation tracks: one focusing on reconstruction fidelity and the other on visual perception through a user study. Both tracks were evaluated with images from the WSRD+ dataset, simulating interactions between self- and cast-shadows with a large number of diverse objects, textures, and materials.
Spectral-Spatial Self-Supervised Learning for Few-Shot Hyperspectral Image Classification
May 18, 2025Few-shot classification of hyperspectral images (HSI) faces the challenge of scarce labeled samples. Self-Supervised learning (SSL) and Few-Shot Learning (FSL) offer promising avenues to address this issue. However, existing methods often struggle to adapt to the spatial geometric diversity of HSIs and lack sufficient spectral prior knowledge. To tackle these challenges, we propose a method, Spectral-Spatial Self-Supervised Learning for Few-Shot Hyperspectral Image Classification (S4L-FSC), aimed at improving the performance of few-shot HSI classification. Specifically, we first leverage heterogeneous datasets to pretrain a spatial feature extractor using a designed Rotation-Mirror Self-Supervised Learning (RM-SSL) method, combined with FSL. This approach enables the model to learn the spatial geometric diversity of HSIs using rotation and mirroring labels as supervisory signals, while acquiring transferable spatial meta-knowledge through few-shot learning. Subsequently, homogeneous datasets are utilized to pretrain a spectral feature extractor via a combination of FSL and Masked Reconstruction Self-Supervised Learning (MR-SSL). The model learns to reconstruct original spectral information from randomly masked spectral vectors, inferring spectral dependencies. In parallel, FSL guides the model to extract pixel-level discriminative features, thereby embedding rich spectral priors into the model. This spectral-spatial pretraining method, along with the integration of knowledge from heterogeneous and homogeneous sources, significantly enhances model performance. Extensive experiments on four HSI datasets demonstrate the effectiveness and superiority of the proposed S4L-FSC approach for few-shot HSI classification.
NTIRE 2025 Challenge on Efficient Burst HDR and Restoration: Datasets, Methods, and Results
May 17, 2025
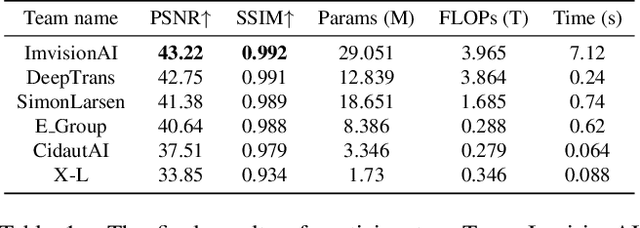

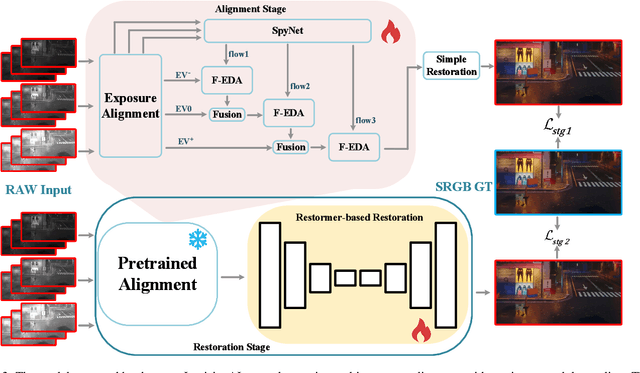
This paper reviews the NTIRE 2025 Efficient Burst HDR and Restoration Challenge, which aims to advance efficient multi-frame high dynamic range (HDR) and restoration techniques. The challenge is based on a novel RAW multi-frame fusion dataset, comprising nine noisy and misaligned RAW frames with various exposure levels per scene. Participants were tasked with developing solutions capable of effectively fusing these frames while adhering to strict efficiency constraints: fewer than 30 million model parameters and a computational budget under 4.0 trillion FLOPs. A total of 217 participants registered, with six teams finally submitting valid solutions. The top-performing approach achieved a PSNR of 43.22 dB, showcasing the potential of novel methods in this domain. This paper provides a comprehensive overview of the challenge, compares the proposed solutions, and serves as a valuable reference for researchers and practitioners in efficient burst HDR and restoration.
NTIRE 2025 Challenge on Event-Based Image Deblurring: Methods and Results
Apr 16, 2025This paper presents an overview of NTIRE 2025 the First Challenge on Event-Based Image Deblurring, detailing the proposed methodologies and corresponding results. The primary goal of the challenge is to design an event-based method that achieves high-quality image deblurring, with performance quantitatively assessed using Peak Signal-to-Noise Ratio (PSNR). Notably, there are no restrictions on computational complexity or model size. The task focuses on leveraging both events and images as inputs for single-image deblurring. A total of 199 participants registered, among whom 15 teams successfully submitted valid results, offering valuable insights into the current state of event-based image deblurring. We anticipate that this challenge will drive further advancements in event-based vision research.
Exploring Personalized Health Support through Data-Driven, Theory-Guided LLMs: A Case Study in Sleep Health
Feb 19, 2025Despite the prevalence of sleep-tracking devices, many individuals struggle to translate data into actionable improvements in sleep health. Current methods often provide data-driven suggestions but may not be feasible and adaptive to real-life constraints and individual contexts. We present HealthGuru, a novel large language model-powered chatbot to enhance sleep health through data-driven, theory-guided, and adaptive recommendations with conversational behavior change support. HealthGuru's multi-agent framework integrates wearable device data, contextual information, and a contextual multi-armed bandit model to suggest tailored sleep-enhancing activities. The system facilitates natural conversations while incorporating data-driven insights and theoretical behavior change techniques. Our eight-week in-the-wild deployment study with 16 participants compared HealthGuru to a baseline chatbot. Results show improved metrics like sleep duration and activity scores, higher quality responses, and increased user motivation for behavior change with HealthGuru. We also identify challenges and design considerations for personalization and user engagement in health chatbots.
AdaSociety: An Adaptive Environment with Social Structures for Multi-Agent Decision-Making
Nov 06, 2024Traditional interactive environments limit agents' intelligence growth with fixed tasks. Recently, single-agent environments address this by generating new tasks based on agent actions, enhancing task diversity. We consider the decision-making problem in multi-agent settings, where tasks are further influenced by social connections, affecting rewards and information access. However, existing multi-agent environments lack a combination of adaptive physical surroundings and social connections, hindering the learning of intelligent behaviors. To address this, we introduce AdaSociety, a customizable multi-agent environment featuring expanding state and action spaces, alongside explicit and alterable social structures. As agents progress, the environment adaptively generates new tasks with social structures for agents to undertake. In AdaSociety, we develop three mini-games showcasing distinct social structures and tasks. Initial results demonstrate that specific social structures can promote both individual and collective benefits, though current reinforcement learning and LLM-based algorithms show limited effectiveness in leveraging social structures to enhance performance. Overall, AdaSociety serves as a valuable research platform for exploring intelligence in diverse physical and social settings. The code is available at https://github.com/bigai-ai/AdaSociety.
From gymnastics to virtual nonholonomic constraints: energy injection, dissipation, and regulation for the acrobot
Oct 11, 2024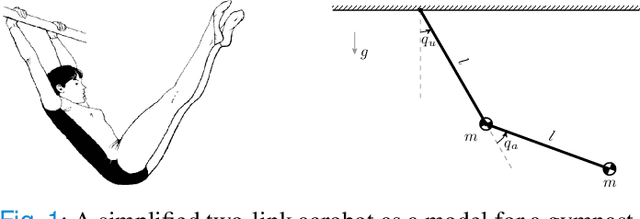

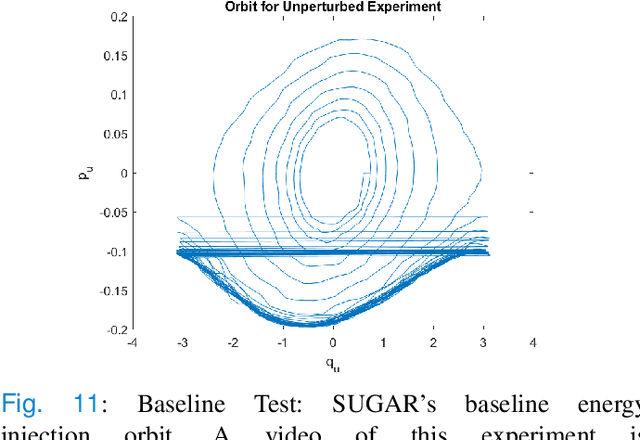
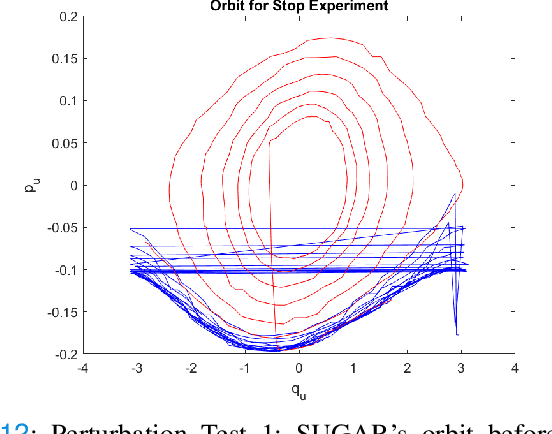
In this article we study virtual nonholonomic constraints, which are relations between the generalized coordinates and momenta of a mechanical system that can be enforced via feedback control. We design a constraint which emulates gymnastics giant motion in an acrobot, and prove that this constraint can inject or dissipate energy based on the sign of a design parameter. The proposed constraint is tested both in simulation and experimentally on a real-world acrobot, demonstrating highly effective energy regulation properties and robustness to a variety of disturbances.
POEM: Interactive Prompt Optimization for Enhancing Multimodal Reasoning of Large Language Models
Jun 06, 2024



Large language models (LLMs) have exhibited impressive abilities for multimodal content comprehension and reasoning with proper prompting in zero- or few-shot settings. Despite the proliferation of interactive systems developed to support prompt engineering for LLMs across various tasks, most have primarily focused on textual or visual inputs, thus neglecting the complex interplay between modalities within multimodal inputs. This oversight hinders the development of effective prompts that guide model multimodal reasoning processes by fully exploiting the rich context provided by multiple modalities. In this paper, we present POEM, a visual analytics system to facilitate efficient prompt engineering for enhancing the multimodal reasoning performance of LLMs. The system enables users to explore the interaction patterns across modalities at varying levels of detail for a comprehensive understanding of the multimodal knowledge elicited by various prompts. Through diverse recommendations of demonstration examples and instructional principles, POEM supports users in iteratively crafting and refining prompts to better align and enhance model knowledge with human insights. The effectiveness and efficiency of our system are validated through two case studies and interviews with experts.
CMOSE: Comprehensive Multi-Modality Online Student Engagement Dataset with High-Quality Labels
Dec 14, 2023


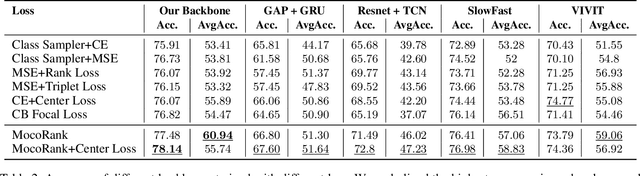
Online learning is a rapidly growing industry due to its convenience. However, a major challenge in online learning is whether students are as engaged as they are in face-to-face classes. An engagement recognition system can significantly improve the learning experience in online classes. Current challenges in engagement detection involve poor label quality in the dataset, intra-class variation, and extreme data imbalance. To address these problems, we present the CMOSE dataset, which contains a large number of data in different engagement levels and high-quality labels generated according to the psychological advice. We demonstrate the advantage of transferability by analyzing the model performance on other engagement datasets. We also developed a training mechanism, MocoRank, to handle the intra-class variation, the ordinal relationship between different classes, and the data imbalance problem. MocoRank outperforms prior engagement detection losses, achieving a 1.32% enhancement in overall accuracy and 5.05% improvement in average accuracy. We further demonstrate the effectiveness of multi-modality by conducting ablation studies on features such as pre-trained video features, high-level facial features, and audio features.
Storyfier: Exploring Vocabulary Learning Support with Text Generation Models
Aug 07, 2023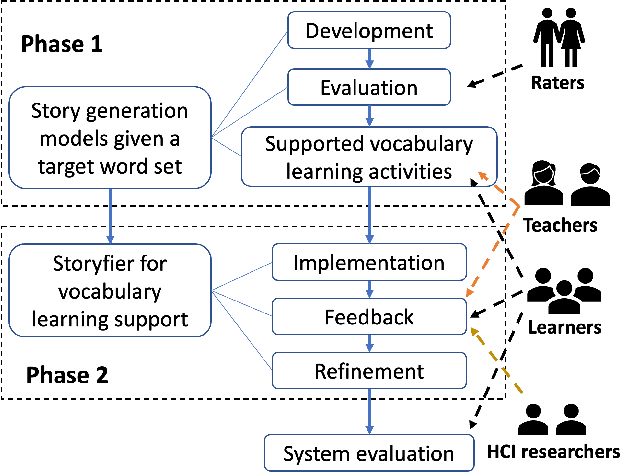
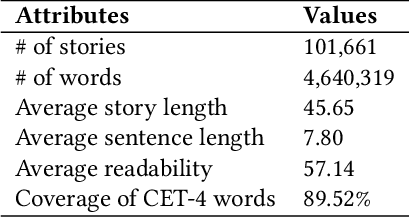
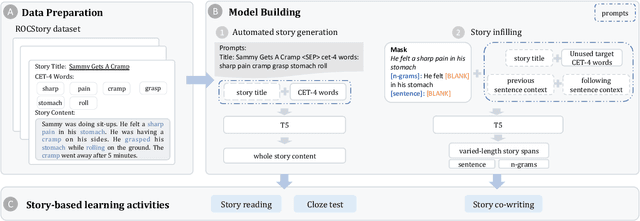

Vocabulary learning support tools have widely exploited existing materials, e.g., stories or video clips, as contexts to help users memorize each target word. However, these tools could not provide a coherent context for any target words of learners' interests, and they seldom help practice word usage. In this paper, we work with teachers and students to iteratively develop Storyfier, which leverages text generation models to enable learners to read a generated story that covers any target words, conduct a story cloze test, and use these words to write a new story with adaptive AI assistance. Our within-subjects study (N=28) shows that learners generally favor the generated stories for connecting target words and writing assistance for easing their learning workload. However, in the read-cloze-write learning sessions, participants using Storyfier perform worse in recalling and using target words than learning with a baseline tool without our AI features. We discuss insights into supporting learning tasks with generative models.