 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCMOSE: Comprehensive Multi-Modality Online Student Engagement Dataset with High-Quality Labels
Dec 14, 2023


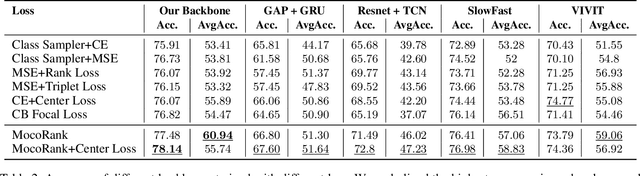
Online learning is a rapidly growing industry due to its convenience. However, a major challenge in online learning is whether students are as engaged as they are in face-to-face classes. An engagement recognition system can significantly improve the learning experience in online classes. Current challenges in engagement detection involve poor label quality in the dataset, intra-class variation, and extreme data imbalance. To address these problems, we present the CMOSE dataset, which contains a large number of data in different engagement levels and high-quality labels generated according to the psychological advice. We demonstrate the advantage of transferability by analyzing the model performance on other engagement datasets. We also developed a training mechanism, MocoRank, to handle the intra-class variation, the ordinal relationship between different classes, and the data imbalance problem. MocoRank outperforms prior engagement detection losses, achieving a 1.32% enhancement in overall accuracy and 5.05% improvement in average accuracy. We further demonstrate the effectiveness of multi-modality by conducting ablation studies on features such as pre-trained video features, high-level facial features, and audio features.
DemoGrasp: Few-Shot Learning for Robotic Grasping with Human Demonstration
Dec 06, 2021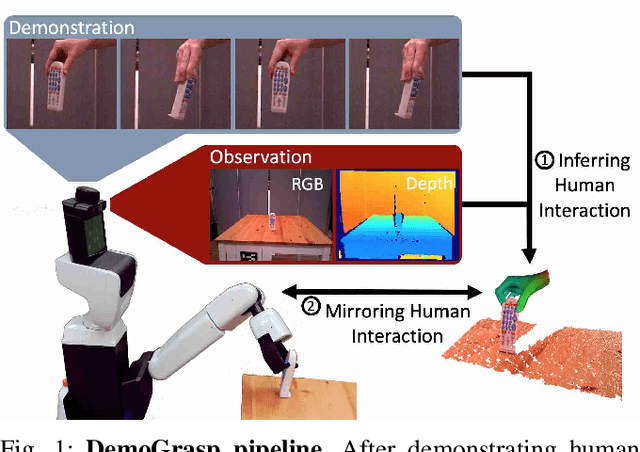
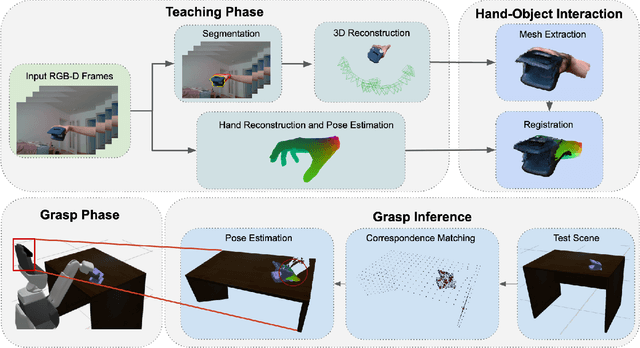


The ability to successfully grasp objects is crucial in robotics, as it enables several interactive downstream applications. To this end, most approaches either compute the full 6D pose for the object of interest or learn to predict a set of grasping points. While the former approaches do not scale well to multiple object instances or classes yet, the latter require large annotated datasets and are hampered by their poor generalization capabilities to new geometries. To overcome these shortcomings, we propose to teach a robot how to grasp an object with a simple and short human demonstration. Hence, our approach neither requires many annotated images nor is it restricted to a specific geometry. We first present a small sequence of RGB-D images displaying a human-object interaction. This sequence is then leveraged to build associated hand and object meshes that represent the depicted interaction. Subsequently, we complete missing parts of the reconstructed object shape and estimate the relative transformation between the reconstruction and the visible object in the scene. Finally, we transfer the a-priori knowledge from the relative pose between object and human hand with the estimate of the current object pose in the scene into necessary grasping instructions for the robot. Exhaustive evaluations with Toyota's Human Support Robot (HSR) in real and synthetic environments demonstrate the applicability of our proposed methodology and its advantage in comparison to previous approaches.
Selective Spatio-Temporal Aggregation Based Pose Refinement System: Towards Understanding Human Activities in Real-World Videos
Nov 10, 2020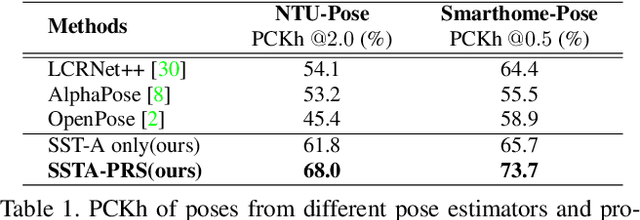
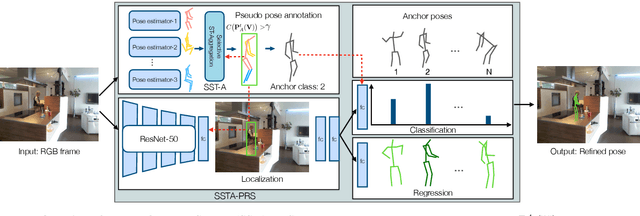
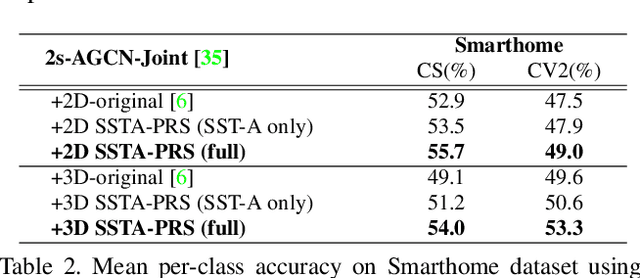
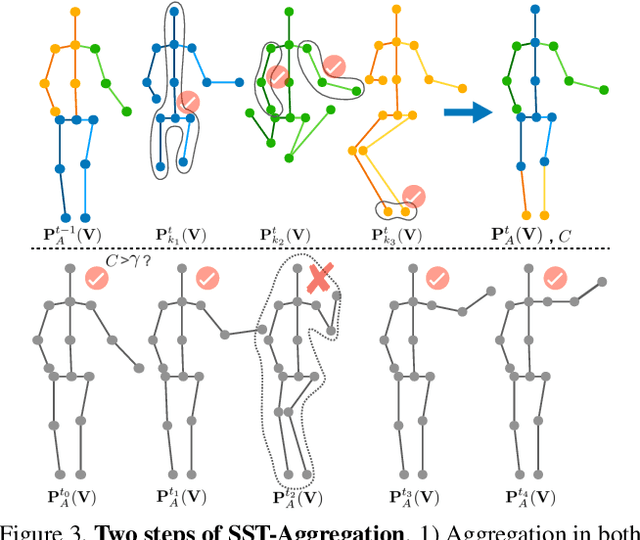
Taking advantage of human pose data for understanding human activities has attracted much attention these days. However, state-of-the-art pose estimators struggle in obtaining high-quality 2D or 3D pose data due to occlusion, truncation and low-resolution in real-world un-annotated videos. Hence, in this work, we propose 1) a Selective Spatio-Temporal Aggregation mechanism, named SST-A, that refines and smooths the keypoint locations extracted by multiple expert pose estimators, 2) an effective weakly-supervised self-training framework which leverages the aggregated poses as pseudo ground-truth instead of handcrafted annotations for real-world pose estimation. Extensive experiments are conducted for evaluating not only the upstream pose refinement but also the downstream action recognition performance on four datasets, Toyota Smarthome, NTU-RGB+D, Charades, and Kinetics-50. We demonstrate that the skeleton data refined by our Pose-Refinement system (SSTA-PRS) is effective at boosting various existing action recognition models, which achieves competitive or state-of-the-art performance.
Toyota Smarthome Untrimmed: Real-World Untrimmed Videos for Activity Detection
Oct 28, 2020
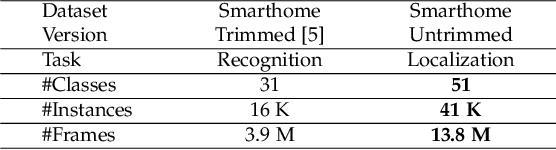

This work aims at building a large scale dataset with daily-living activities performed in a natural manner. Activities performed in a spontaneous manner lead to many real-world challenges that are often ignored by the vision community. This includes low inter-class due to the presence of similar activities and high intra-class variance, low camera framing, low resolution, long-tail distribution of activities, and occlusions. To this end, we propose the Toyota Smarthome Untrimmed (TSU) dataset, which provides spontaneous activities with rich and dense annotations to address the detection of complex activities in real-world scenarios.
On Evaluating Weakly Supervised Action Segmentation Methods
May 21, 2020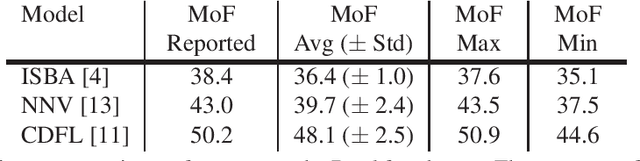
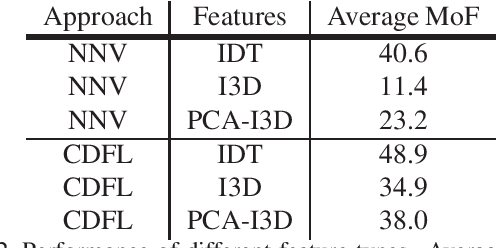

Action segmentation is the task of temporally segmenting every frame of an untrimmed video. Weakly supervised approaches to action segmentation, especially from transcripts have been of considerable interest to the computer vision community. In this work, we focus on two aspects of the use and evaluation of weakly supervised action segmentation approaches that are often overlooked: the performance variance over multiple training runs and the impact of selecting feature extractors for this task. To tackle the first problem, we train each method on the Breakfast dataset 5 times and provide average and standard deviation of the results. Our experiments show that the standard deviation over these repetitions is between 1 and 2.5% and significantly affects the comparison between different approaches. Furthermore, our investigation on feature extraction shows that, for the studied weakly-supervised action segmentation methods, higher-level I3D features perform worse than classical IDT features.
CPS: Class-level 6D Pose and Shape Estimation From Monocular Images
Mar 13, 2020
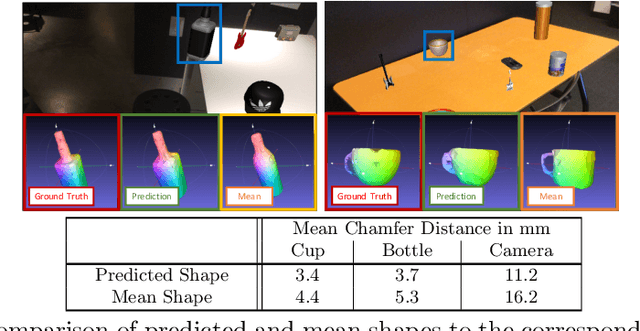
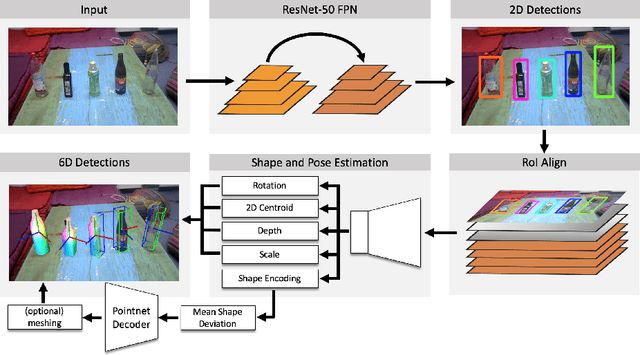
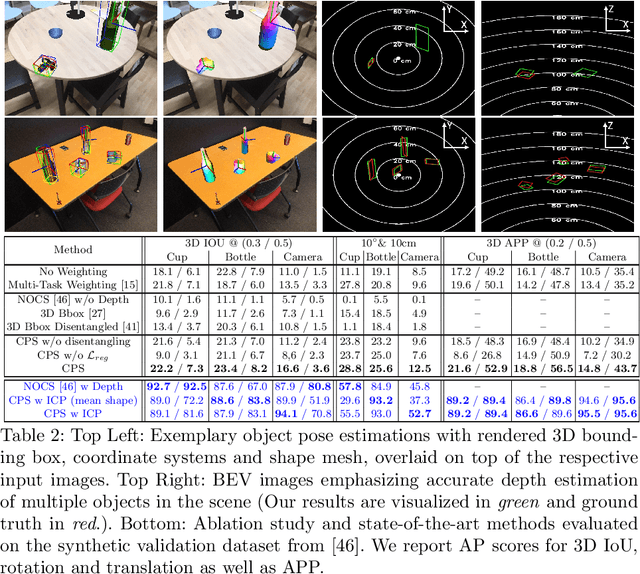
Contemporary monocular 6D pose estimation methods can only cope with a handful of object instances. This naturally limits possible applications as, for instance, robots need to work with hundreds of different objects in a real environment. In this paper, we propose the first deep learning approach for class-wise monocular 6D pose estimation, coupled with metric shape retrieval. We propose a new loss formulation which directly optimizes over all parameters, i.e. 3D orientation, translation, scale and shape at the same time. Instead of decoupling each parameter, we transform the regressed shape, in the form of a point cloud, to 3D and directly measure its metric misalignment. We experimentally demonstrate that we can retrieve precise metric point clouds from a single image, which can also be further processed for e.g. subsequent rendering. Moreover, we show that our new 3D point cloud loss outperforms all baselines and gives overall good results despite the inherent ambiguity due to monocular data.