 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Evaluating Weakly Supervised Action Segmentation Methods
Paper and Code
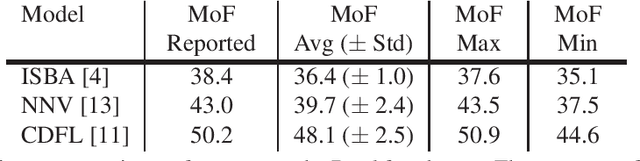
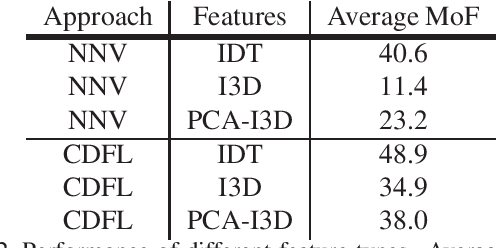

Action segmentation is the task of temporally segmenting every frame of an untrimmed video. Weakly supervised approaches to action segmentation, especially from transcripts have been of considerable interest to the computer vision community. In this work, we focus on two aspects of the use and evaluation of weakly supervised action segmentation approaches that are often overlooked: the performance variance over multiple training runs and the impact of selecting feature extractors for this task. To tackle the first problem, we train each method on the Breakfast dataset 5 times and provide average and standard deviation of the results. Our experiments show that the standard deviation over these repetitions is between 1 and 2.5% and significantly affects the comparison between different approaches. Furthermore, our investigation on feature extraction shows that, for the studied weakly-supervised action segmentation methods, higher-level I3D features perform worse than classical IDT features.