 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Action Segmentation from Timestamp Supervision
Oct 12, 2022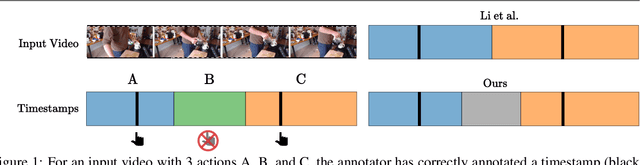
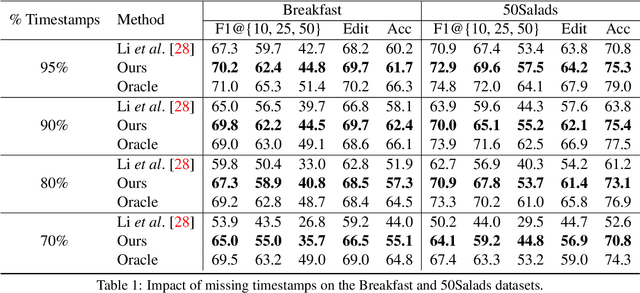
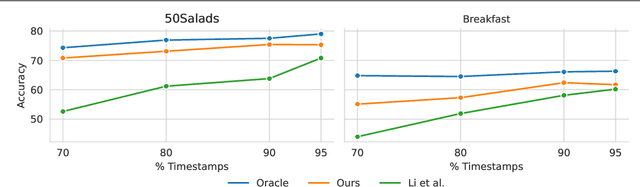
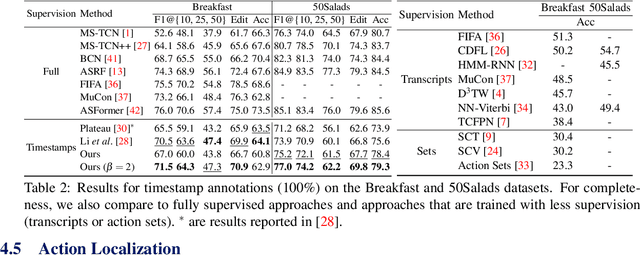
Action segmentation is the task of predicting an action label for each frame of an untrimmed video. As obtaining annotations to train an approach for action segmentation in a fully supervised way is expensive, various approaches have been proposed to train action segmentation models using different forms of weak supervision, e.g., action transcripts, action sets, or more recently timestamps. Timestamp supervision is a promising type of weak supervision as obtaining one timestamp per action is less expensive than annotating all frames, but it provides more information than other forms of weak supervision. However, previous works assume that every action instance is annotated with a timestamp, which is a restrictive assumption since it assumes that annotators do not miss any action. In this work, we relax this restrictive assumption and take missing annotations for some action instances into account. We show that our approach is more robust to missing annotations compared to other approaches and various baselines.
FIFA: Fast Inference Approximation for Action Segmentation
Aug 09, 2021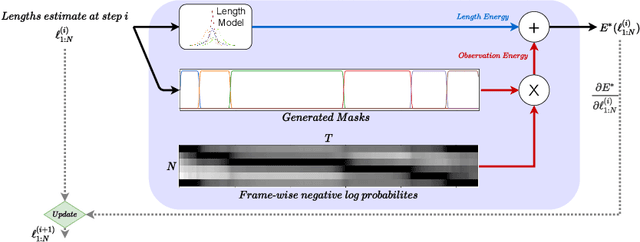
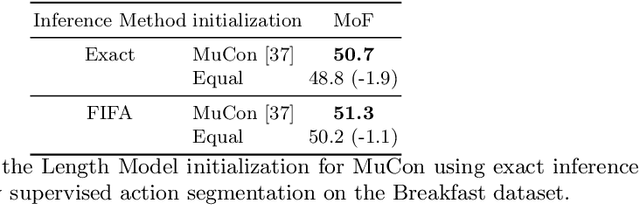
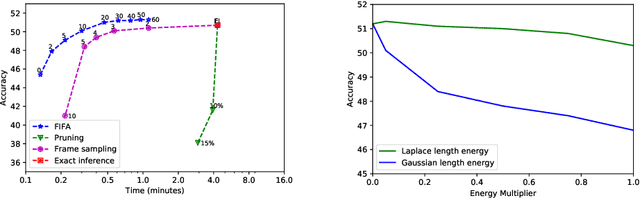
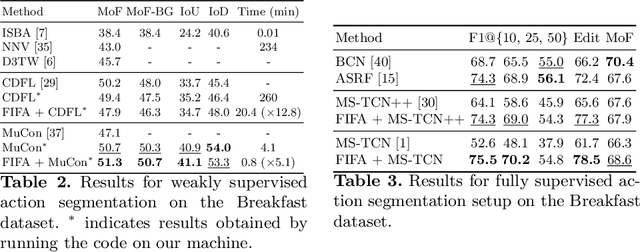
We introduce FIFA, a fast approximate inference method for action segmentation and alignment. Unlike previous approaches, FIFA does not rely on expensive dynamic programming for inference. Instead, it uses an approximate differentiable energy function that can be minimized using gradient-descent. FIFA is a general approach that can replace exact inference improving its speed by more than 5 times while maintaining its performance. FIFA is an anytime inference algorithm that provides a better speed vs. accuracy trade-off compared to exact inference. We apply FIFA on top of state-of-the-art approaches for weakly supervised action segmentation and alignment as well as fully supervised action segmentation. FIFA achieves state-of-the-art results on most metrics on two action segmentation datasets.
Hierarchical Graph-RNNs for Action Detection of Multiple Activities
Jan 21, 2021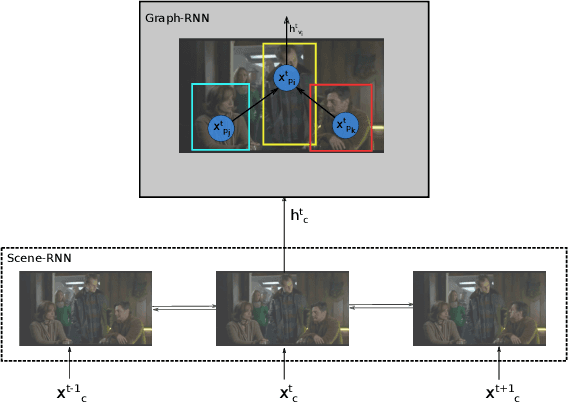



In this paper, we propose an approach that spatially localizes the activities in a video frame where each person can perform multiple activities at the same time. Our approach takes the temporal scene context as well as the relations of the actions of detected persons into account. While the temporal context is modeled by a temporal recurrent neural network (RNN), the relations of the actions are modeled by a graph RNN. Both networks are trained together and the proposed approach achieves state of the art results on the AVA dataset.
On Evaluating Weakly Supervised Action Segmentation Methods
May 21, 2020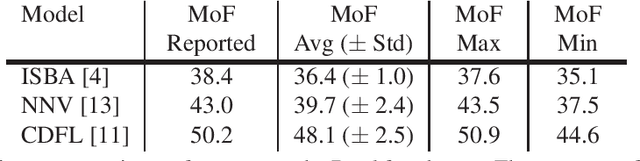
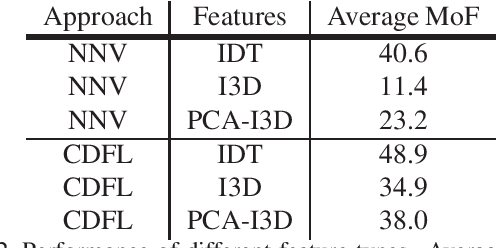

Action segmentation is the task of temporally segmenting every frame of an untrimmed video. Weakly supervised approaches to action segmentation, especially from transcripts have been of considerable interest to the computer vision community. In this work, we focus on two aspects of the use and evaluation of weakly supervised action segmentation approaches that are often overlooked: the performance variance over multiple training runs and the impact of selecting feature extractors for this task. To tackle the first problem, we train each method on the Breakfast dataset 5 times and provide average and standard deviation of the results. Our experiments show that the standard deviation over these repetitions is between 1 and 2.5% and significantly affects the comparison between different approaches. Furthermore, our investigation on feature extraction shows that, for the studied weakly-supervised action segmentation methods, higher-level I3D features perform worse than classical IDT features.
Weakly Supervised Action Segmentation Using Mutual Consistency
Apr 05, 2019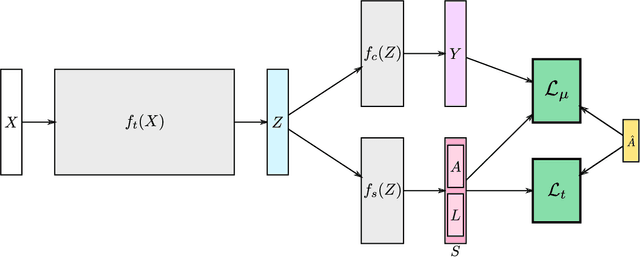

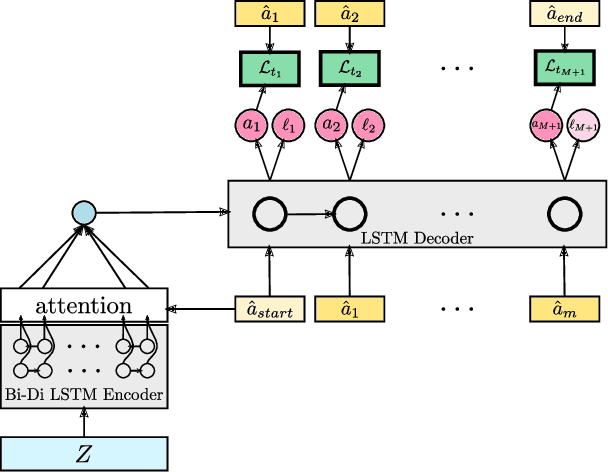
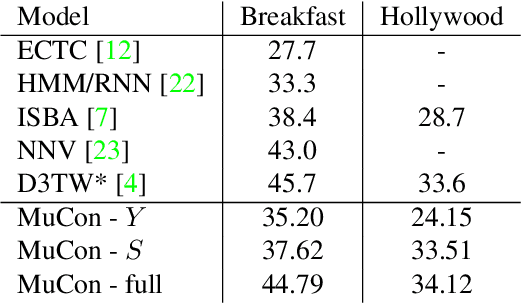
Action segmentation is the task of predicting the actions in each frame of a video. Because of the high cost of preparing training videos with full supervision for action segmentation, weakly supervised approaches which are able to learn only from transcripts are very appealing. In this paper, we propose a new approach for weakly supervised action segmentation based on a two branch network. The two branches of our network predict two redundant but different representations for action segmentation. During training we introduce a new mutual consistency loss (MuCon) that enforces that these two representations are consistent. Using MuCon and a transcript prediction loss, our network achieves state-of-the-art results for action segmentation and action alignment while being fully differentiable and faster to train since it does not require a costly alignment step during training.
What Object Should I Use? - Task Driven Object Detection
Apr 05, 2019


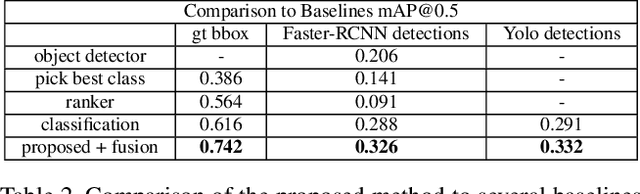
When humans have to solve everyday tasks, they simply pick the objects that are most suitable. While the question which object should one use for a specific task sounds trivial for humans, it is very difficult to answer for robots or other autonomous systems. This issue, however, is not addressed by current benchmarks for object detection that focus on detecting object categories. We therefore introduce the COCO-Tasks dataset which comprises about 40,000 images where the most suitable objects for 14 tasks have been annotated. We furthermore propose an approach that detects the most suitable objects for a given task. The approach builds on a Gated Graph Neural Network to exploit the appearance of each object as well as the global context of all present objects in the scene. In our experiments, we show that the proposed approach outperforms other approaches that are evaluated on the dataset like classification or ranking approaches.
Deep Relative Attributes
Sep 13, 2016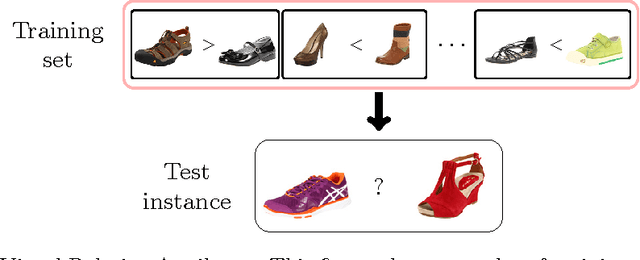
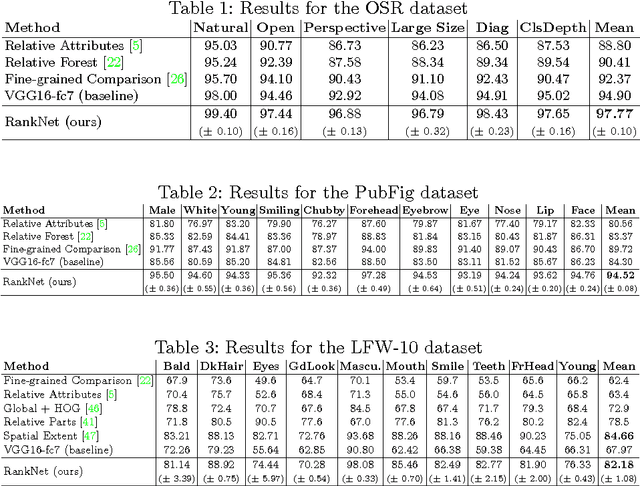
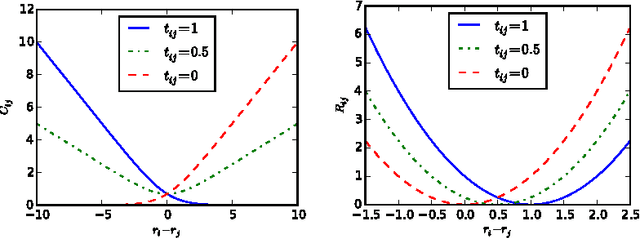
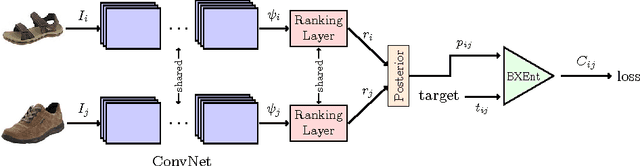
Visual attributes are great means of describing images or scenes, in a way both humans and computers understand. In order to establish a correspondence between images and to be able to compare the strength of each property between images, relative attributes were introduced. However, since their introduction, hand-crafted and engineered features were used to learn increasingly complex models for the problem of relative attributes. This limits the applicability of those methods for more realistic cases. We introduce a deep neural network architecture for the task of relative attribute prediction. A convolutional neural network (ConvNet) is adopted to learn the features by including an additional layer (ranking layer) that learns to rank the images based on these features. We adopt an appropriate ranking loss to train the whole network in an end-to-end fashion. Our proposed method outperforms the baseline and state-of-the-art methods in relative attribute prediction on various coarse and fine-grained datasets. Our qualitative results along with the visualization of the saliency maps show that the network is able to learn effective features for each specific attribute. Source code of the proposed method is available at https://github.com/yassersouri/ghiaseddin.