 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeakly Supervised Action Segmentation Using Mutual Consistency
Paper and Code
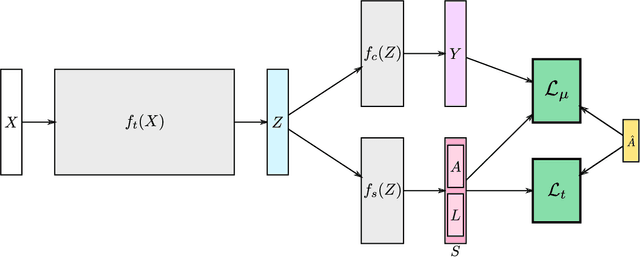

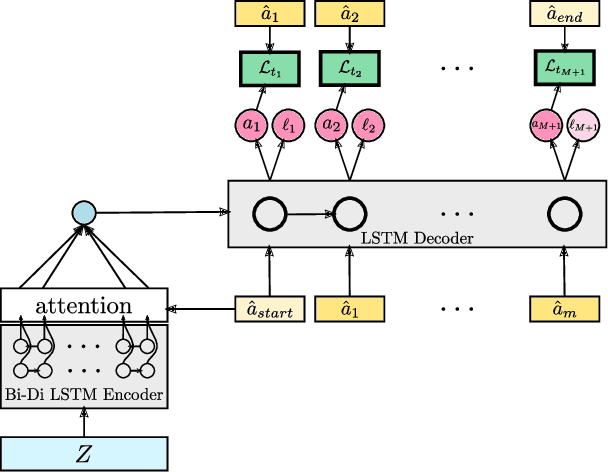
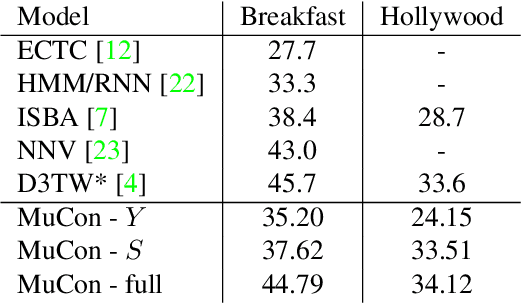
Action segmentation is the task of predicting the actions in each frame of a video. Because of the high cost of preparing training videos with full supervision for action segmentation, weakly supervised approaches which are able to learn only from transcripts are very appealing. In this paper, we propose a new approach for weakly supervised action segmentation based on a two branch network. The two branches of our network predict two redundant but different representations for action segmentation. During training we introduce a new mutual consistency loss (MuCon) that enforces that these two representations are consistent. Using MuCon and a transcript prediction loss, our network achieves state-of-the-art results for action segmentation and action alignment while being fully differentiable and faster to train since it does not require a costly alignment step during training.