 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQPM: Discrete Optimization for Globally Interpretable Image Classification
Feb 27, 2025

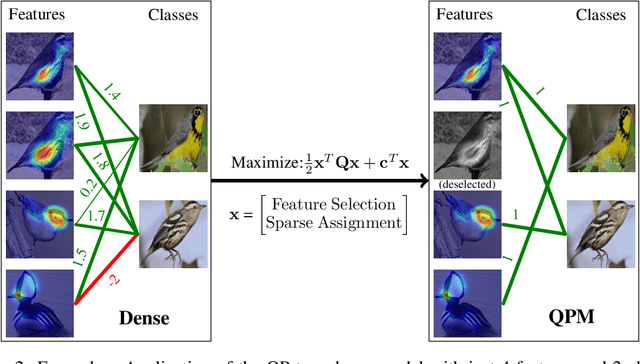
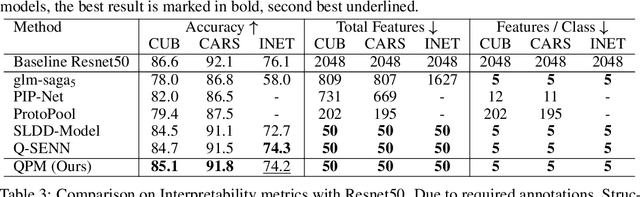
Understanding the classifications of deep neural networks, e.g. used in safety-critical situations, is becoming increasingly important. While recent models can locally explain a single decision, to provide a faithful global explanation about an accurate model's general behavior is a more challenging open task. Towards that goal, we introduce the Quadratic Programming Enhanced Model (QPM), which learns globally interpretable class representations. QPM represents every class with a binary assignment of very few, typically 5, features, that are also assigned to other classes, ensuring easily comparable contrastive class representations. This compact binary assignment is found using discrete optimization based on predefined similarity measures and interpretability constraints. The resulting optimal assignment is used to fine-tune the diverse features, so that each of them becomes the shared general concept between the assigned classes. Extensive evaluations show that QPM delivers unprecedented global interpretability across small and large-scale datasets while setting the state of the art for the accuracy of interpretable models.
A Beginner's Guide to Power and Energy Measurement and Estimation for Computing and Machine Learning
Dec 11, 2024Concerns about the environmental footprint of machine learning are increasing. While studies of energy use and emissions of ML models are a growing subfield, most ML researchers and developers still do not incorporate energy measurement as part of their work practices. While measuring energy is a crucial step towards reducing carbon footprint, it is also not straightforward. This paper introduces the main considerations necessary for making sound use of energy measurement tools and interpreting energy estimates, including the use of at-the-wall versus on-device measurements, sampling strategies and best practices, common sources of error, and proxy measures. It also contains practical tips and real-world scenarios that illustrate how these considerations come into play. It concludes with a call to action for improving the state of the art of measurement methods and standards for facilitating robust comparisons between diverse hardware and software environments.
QA-TOOLBOX: Conversational Question-Answering for process task guidance in manufacturing
Dec 03, 2024



In this work we explore utilizing LLMs for data augmentation for manufacturing task guidance system. The dataset consists of representative samples of interactions with technicians working in an advanced manufacturing setting. The purpose of this work to explore the task, data augmentation for the supported tasks and evaluating the performance of the existing LLMs. We observe that that task is complex requiring understanding from procedure specification documents, actions and objects sequenced temporally. The dataset consists of 200,000+ question/answer pairs that refer to the spec document and are grounded in narrations and/or video demonstrations. We compared the performance of several popular open-sourced LLMs by developing a baseline using each LLM and then compared the responses in a reference-free setting using LLM-as-a-judge and compared the ratings with crowd-workers whilst validating the ratings with experts.
Unsupervised Welding Defect Detection Using Audio And Video
Sep 03, 2024In this work we explore the application of AI to robotic welding. Robotic welding is a widely used technology in many industries, but robots currently do not have the capability to detect welding defects which get introduced due to various reasons in the welding process. We describe how deep-learning methods can be applied to detect weld defects in real-time by recording the welding process with microphones and a camera. Our findings are based on a large database with more than 4000 welding samples we collected which covers different weld types, materials and various defect categories. All deep learning models are trained in an unsupervised fashion because the space of possible defects is large and the defects in our data may contain biases. We demonstrate that a reliable real-time detection of most categories of weld defects is feasible both from audio and video, with improvements achieved by combining both modalities. Specifically, the multi-modal approach achieves an average Area-under-ROC-Curve (AUC) of 0.92 over all eleven defect types in our data. We conclude the paper with an analysis of the results by defect type and a discussion of future work.
Human in the loop approaches in multi-modal conversational task guidance system development
Nov 03, 2022



Development of task guidance systems for aiding humans in a situated task remains a challenging problem. The role of search (information retrieval) and conversational systems for task guidance has immense potential to help the task performers achieve various goals. However, there are several technical challenges that need to be addressed to deliver such conversational systems, where common supervised approaches fail to deliver the expected results in terms of overall performance, user experience and adaptation to realistic conditions. In this preliminary work we first highlight some of the challenges involved during the development of such systems. We then provide an overview of existing datasets available and highlight their limitations. We finally develop a model-in-the-loop wizard-of-oz based data collection tool and perform a pilot experiment.
Distill and Collect for Semi-Supervised Temporal Action Segmentation
Nov 03, 2022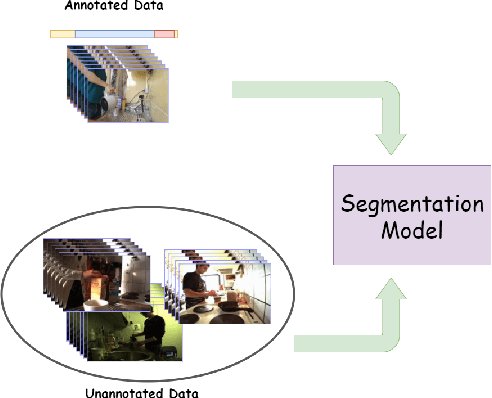
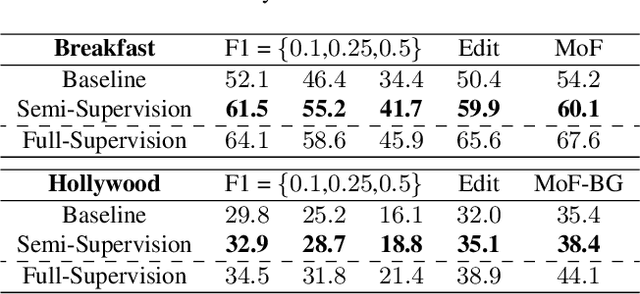
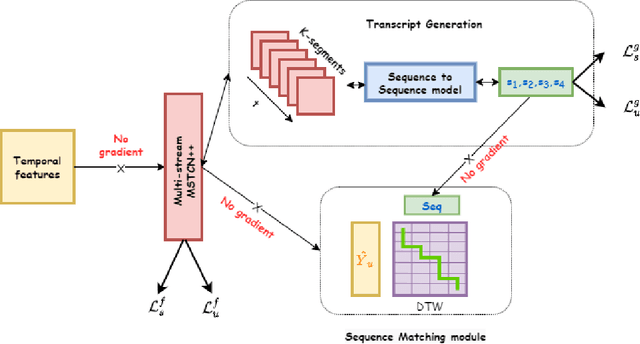

Recent temporal action segmentation approaches need frame annotations during training to be effective. These annotations are very expensive and time-consuming to obtain. This limits their performances when only limited annotated data is available. In contrast, we can easily collect a large corpus of in-domain unannotated videos by scavenging through the internet. Thus, this paper proposes an approach for the temporal action segmentation task that can simultaneously leverage knowledge from annotated and unannotated video sequences. Our approach uses multi-stream distillation that repeatedly refines and finally combines their frame predictions. Our model also predicts the action order, which is later used as a temporal constraint while estimating frames labels to counter the lack of supervision for unannotated videos. In the end, our evaluation of the proposed approach on two different datasets demonstrates its capability to achieve comparable performance to the full supervision despite limited annotation.
Hierarchical Graph-RNNs for Action Detection of Multiple Activities
Jan 21, 2021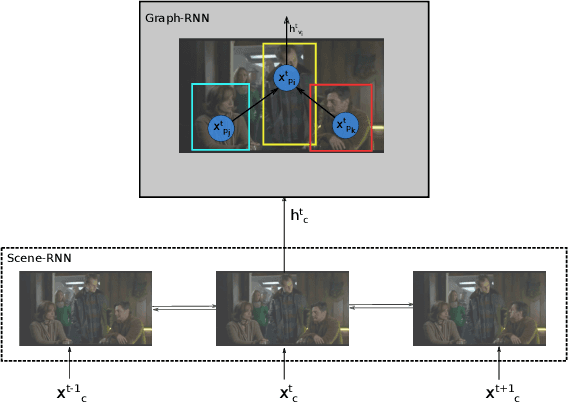



In this paper, we propose an approach that spatially localizes the activities in a video frame where each person can perform multiple activities at the same time. Our approach takes the temporal scene context as well as the relations of the actions of detected persons into account. While the temporal context is modeled by a temporal recurrent neural network (RNN), the relations of the actions are modeled by a graph RNN. Both networks are trained together and the proposed approach achieves state of the art results on the AVA dataset.
Discovering Multi-Label Actor-Action Association in a Weakly Supervised Setting
Jan 21, 2021
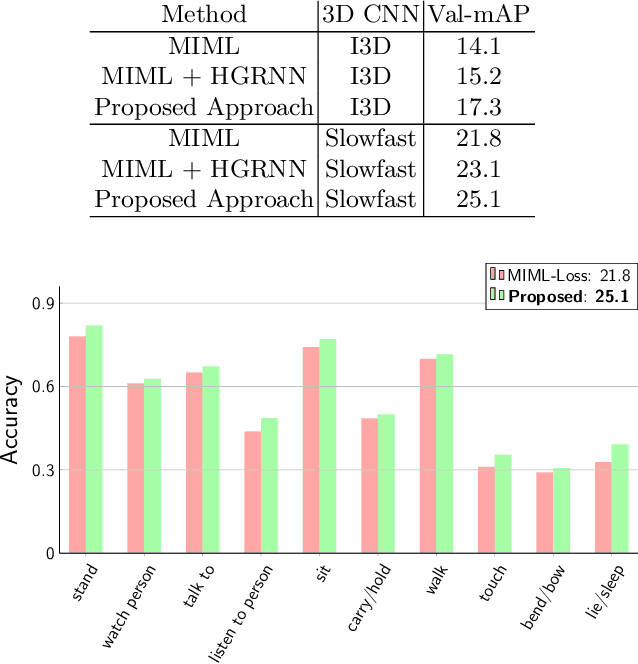

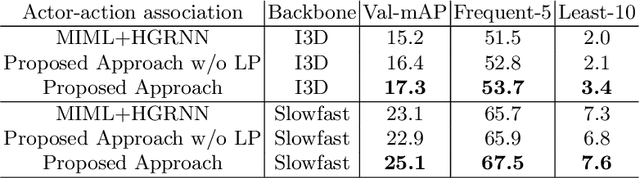
Since collecting and annotating data for spatio-temporal action detection is very expensive, there is a need to learn approaches with less supervision. Weakly supervised approaches do not require any bounding box annotations and can be trained only from labels that indicate whether an action occurs in a video clip. Current approaches, however, cannot handle the case when there are multiple persons in a video that perform multiple actions at the same time. In this work, we address this very challenging task for the first time. We propose a baseline based on multi-instance and multi-label learning. Furthermore, we propose a novel approach that uses sets of actions as representation instead of modeling individual action classes. Since computing, the probabilities for the full power set becomes intractable as the number of action classes increases, we assign an action set to each detected person under the constraint that the assignment is consistent with the annotation of the video clip. We evaluate the proposed approach on the challenging AVA dataset where the proposed approach outperforms the MIML baseline and is competitive to fully supervised approaches.
Structural Recurrent Neural Network (SRNN) for Group Activity Analysis
Feb 06, 2018
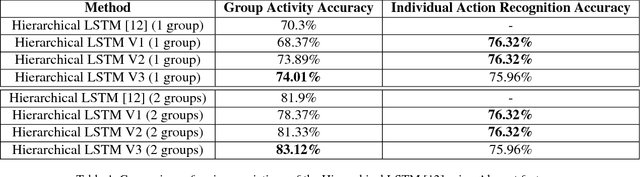
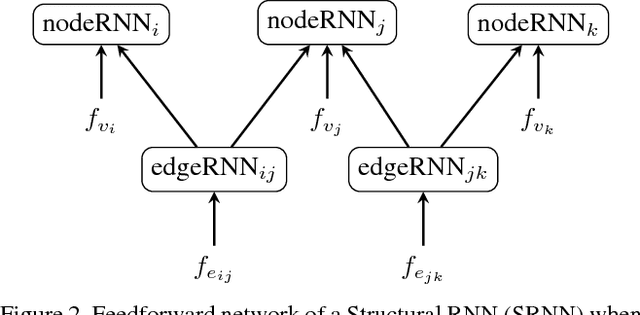
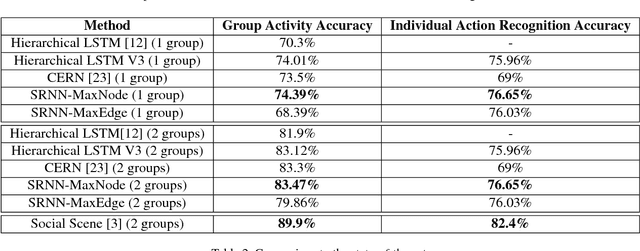
A group of persons can be analyzed at various semantic levels such as individual actions, their interactions, and the activity of the entire group. In this paper, we propose a structural recurrent neural network (SRNN) that uses a series of interconnected RNNs to jointly capture the actions of individuals, their interactions, as well as the group activity. While previous structural recurrent neural networks assumed that the number of nodes and edges is constant, we use a grid pooling layer to address the fact that the number of individuals in a group can vary. We evaluate two variants of the structural recurrent neural network on the Volleyball Dataset.