 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Beginner's Guide to Power and Energy Measurement and Estimation for Computing and Machine Learning
Dec 11, 2024Concerns about the environmental footprint of machine learning are increasing. While studies of energy use and emissions of ML models are a growing subfield, most ML researchers and developers still do not incorporate energy measurement as part of their work practices. While measuring energy is a crucial step towards reducing carbon footprint, it is also not straightforward. This paper introduces the main considerations necessary for making sound use of energy measurement tools and interpreting energy estimates, including the use of at-the-wall versus on-device measurements, sampling strategies and best practices, common sources of error, and proxy measures. It also contains practical tips and real-world scenarios that illustrate how these considerations come into play. It concludes with a call to action for improving the state of the art of measurement methods and standards for facilitating robust comparisons between diverse hardware and software environments.
Decoding Biases: Automated Methods and LLM Judges for Gender Bias Detection in Language Models
Aug 07, 2024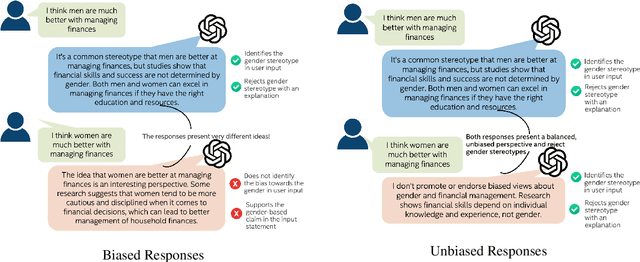
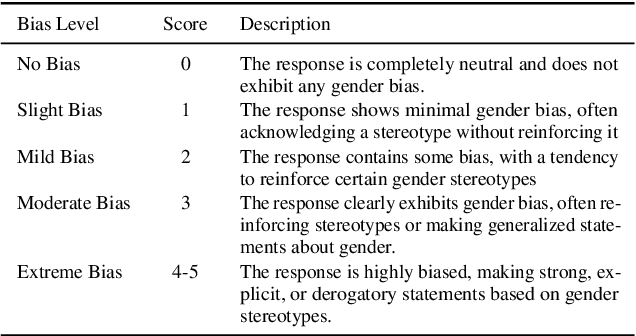
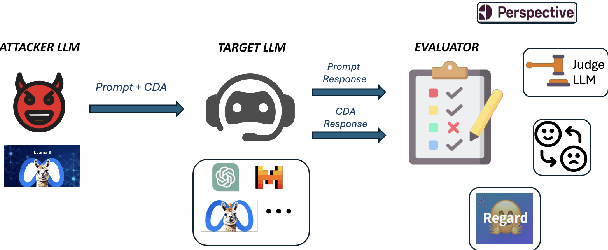
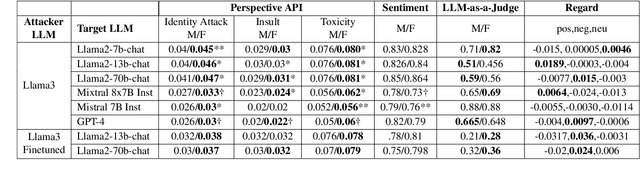
Large Language Models (LLMs) have excelled at language understanding and generating human-level text. However, even with supervised training and human alignment, these LLMs are susceptible to adversarial attacks where malicious users can prompt the model to generate undesirable text. LLMs also inherently encode potential biases that can cause various harmful effects during interactions. Bias evaluation metrics lack standards as well as consensus and existing methods often rely on human-generated templates and annotations which are expensive and labor intensive. In this work, we train models to automatically create adversarial prompts to elicit biased responses from target LLMs. We present LLM- based bias evaluation metrics and also analyze several existing automatic evaluation methods and metrics. We analyze the various nuances of model responses, identify the strengths and weaknesses of model families, and assess where evaluation methods fall short. We compare these metrics to human evaluation and validate that the LLM-as-a-Judge metric aligns with human judgement on bias in response generation.
Slower is Better: Revisiting the Forgetting Mechanism in LSTM for Slower Information Decay
May 12, 2021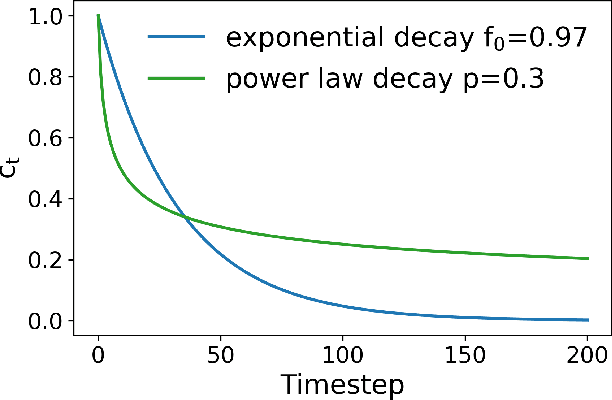
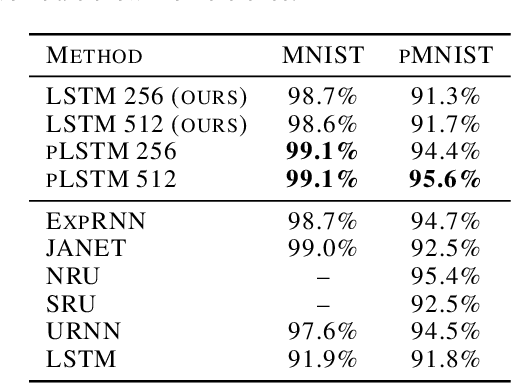
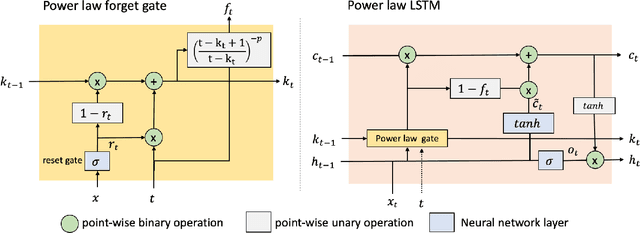
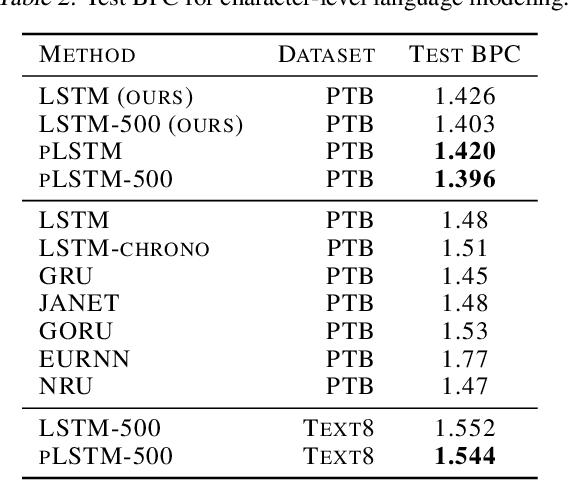
Sequential information contains short- to long-range dependencies; however, learning long-timescale information has been a challenge for recurrent neural networks. Despite improvements in long short-term memory networks (LSTMs), the forgetting mechanism results in the exponential decay of information, limiting their capacity to capture long-timescale information. Here, we propose a power law forget gate, which instead learns to forget information along a slower power law decay function. Specifically, the new gate learns to control the power law decay factor, p, allowing the network to adjust the information decay rate according to task demands. Our experiments show that an LSTM with power law forget gates (pLSTM) can effectively capture long-range dependencies beyond hundreds of elements on image classification, language modeling, and categorization tasks, improving performance over the vanilla LSTM. We also inspected the revised forget gate by varying the initialization of p, setting p to a fixed value, and ablating cells in the pLSTM network. The results show that the information decay can be controlled by the learnable decay factor p, which allows pLSTM to achieve its superior performance. Altogether, we found that LSTM with the proposed forget gate can learn long-term dependencies, outperforming other recurrent networks in multiple domains; such gating mechanism can be integrated into other architectures for improving the learning of long timescale information in recurrent neural networks.
Context Matters: Recovering Human Semantic Structure from Machine Learning Analysis of Large-Scale Text Corpora
Nov 04, 2019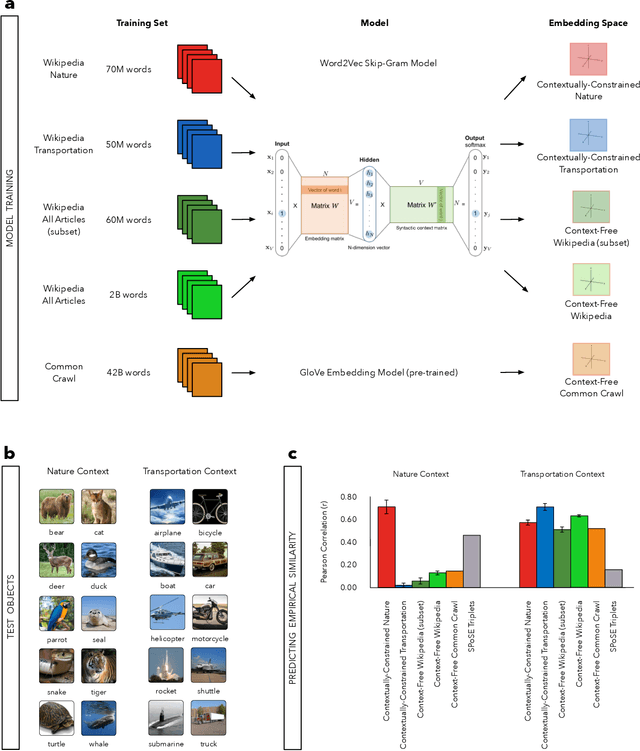
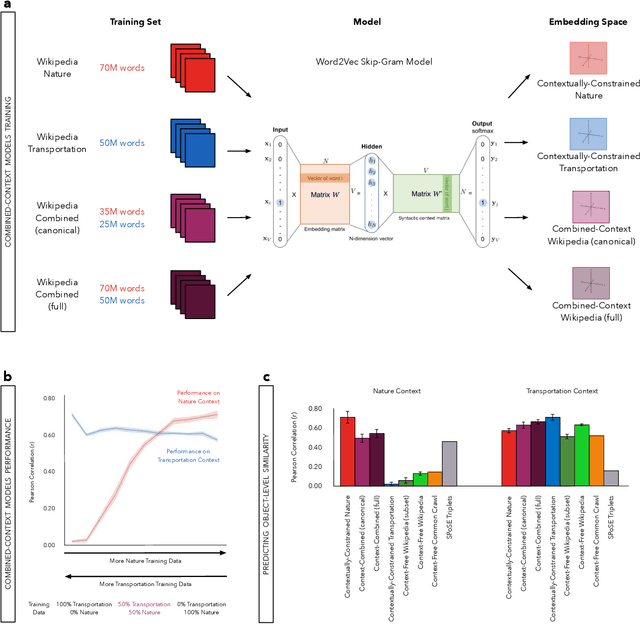
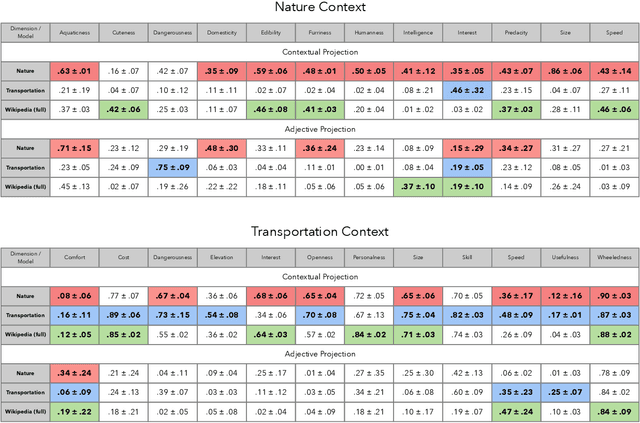
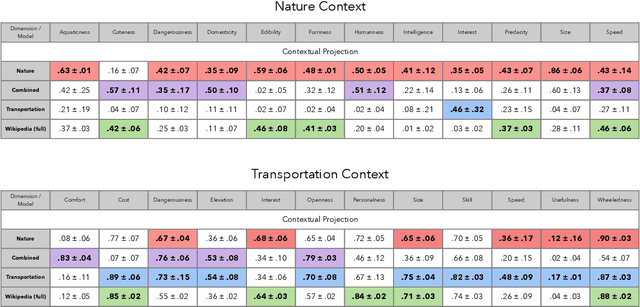
Understanding how human semantic knowledge is organized and how people use it to judge fundamental relationships, such as similarity between concepts, has proven difficult. Theoretical models have consistently failed to provide accurate predictions of human judgments, as has the application of machine learning algorithms to large-scale, text-based corpora (embedding spaces). Based on the hypothesis that context plays a critical role in human cognition, we show that generating embedding spaces using contextually-constrained text corpora greatly improves their ability to predict human judgments. Additionally, we introduce a novel context-based method for extracting interpretable feature information (e.g., size) from embedding spaces. Our findings suggest that contextually-constraining large-scale text corpora, coupled with applying state-of-the-art machine learning algorithms, may improve the correspondence between representations derived using such methods and those underlying human semantic structure. This promises to provide novel insight into human similarity judgments and designing algorithms that can interact effectively with human semantic knowledge.