 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContext Matters: Recovering Human Semantic Structure from Machine Learning Analysis of Large-Scale Text Corpora
Nov 04, 2019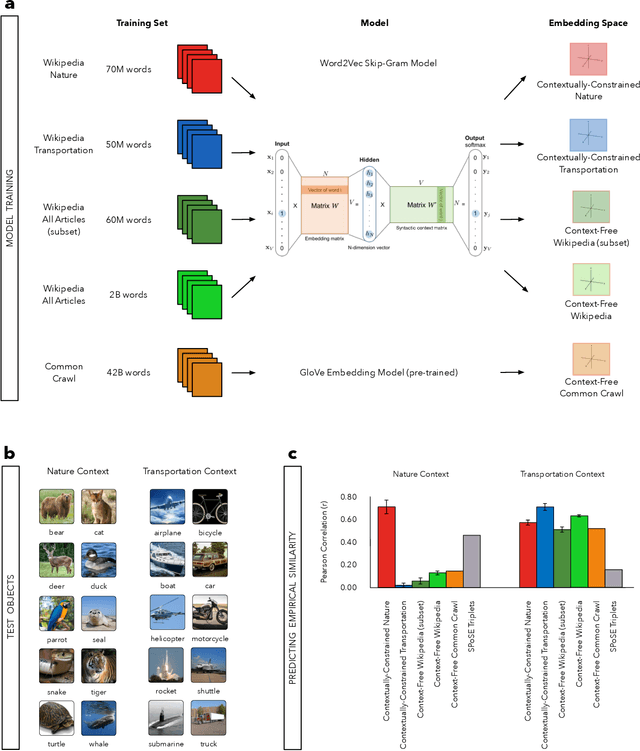
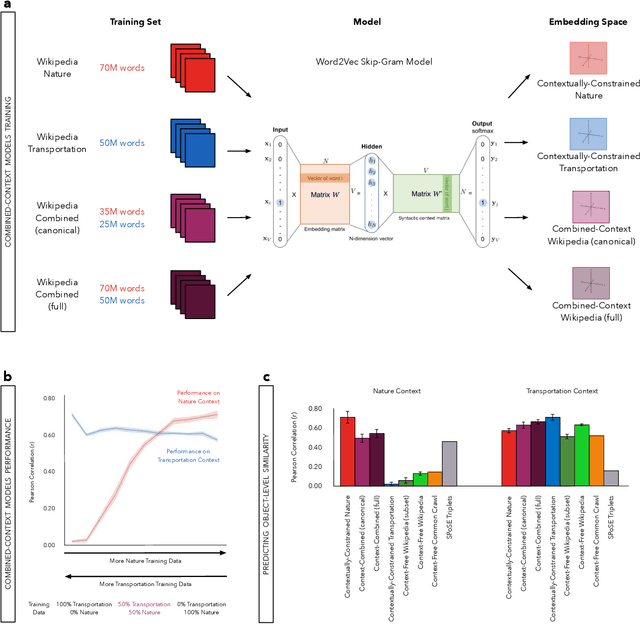
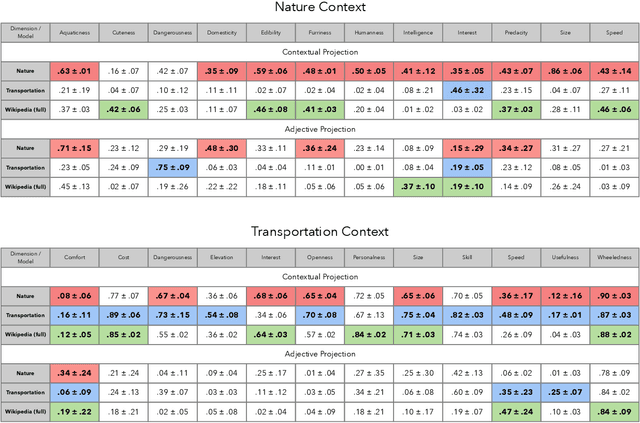
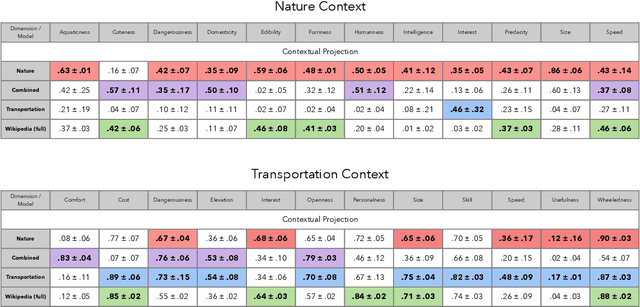
Understanding how human semantic knowledge is organized and how people use it to judge fundamental relationships, such as similarity between concepts, has proven difficult. Theoretical models have consistently failed to provide accurate predictions of human judgments, as has the application of machine learning algorithms to large-scale, text-based corpora (embedding spaces). Based on the hypothesis that context plays a critical role in human cognition, we show that generating embedding spaces using contextually-constrained text corpora greatly improves their ability to predict human judgments. Additionally, we introduce a novel context-based method for extracting interpretable feature information (e.g., size) from embedding spaces. Our findings suggest that contextually-constraining large-scale text corpora, coupled with applying state-of-the-art machine learning algorithms, may improve the correspondence between representations derived using such methods and those underlying human semantic structure. This promises to provide novel insight into human similarity judgments and designing algorithms that can interact effectively with human semantic knowledge.