 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAI-enhanced semantic feature norms for 786 concepts
May 15, 2025Semantic feature norms have been foundational in the study of human conceptual knowledge, yet traditional methods face trade-offs between concept/feature coverage and verifiability of quality due to the labor-intensive nature of norming studies. Here, we introduce a novel approach that augments a dataset of human-generated feature norms with responses from large language models (LLMs) while verifying the quality of norms against reliable human judgments. We find that our AI-enhanced feature norm dataset, NOVA: Norms Optimized Via AI, shows much higher feature density and overlap among concepts while outperforming a comparable human-only norm dataset and word-embedding models in predicting people's semantic similarity judgments. Taken together, we demonstrate that human conceptual knowledge is richer than captured in previous norm datasets and show that, with proper validation, LLMs can serve as powerful tools for cognitive science research.
Understanding the Limits of Vision Language Models Through the Lens of the Binding Problem
Oct 31, 2024



Recent work has documented striking heterogeneity in the performance of state-of-the-art vision language models (VLMs), including both multimodal language models and text-to-image models. These models are able to describe and generate a diverse array of complex, naturalistic images, yet they exhibit surprising failures on basic multi-object reasoning tasks -- such as counting, localization, and simple forms of visual analogy -- that humans perform with near perfect accuracy. To better understand this puzzling pattern of successes and failures, we turn to theoretical accounts of the binding problem in cognitive science and neuroscience, a fundamental problem that arises when a shared set of representational resources must be used to represent distinct entities (e.g., to represent multiple objects in an image), necessitating the use of serial processing to avoid interference. We find that many of the puzzling failures of state-of-the-art VLMs can be explained as arising due to the binding problem, and that these failure modes are strikingly similar to the limitations exhibited by rapid, feedforward processing in the human brain.
Human-Like Geometric Abstraction in Large Pre-trained Neural Networks
Feb 06, 2024
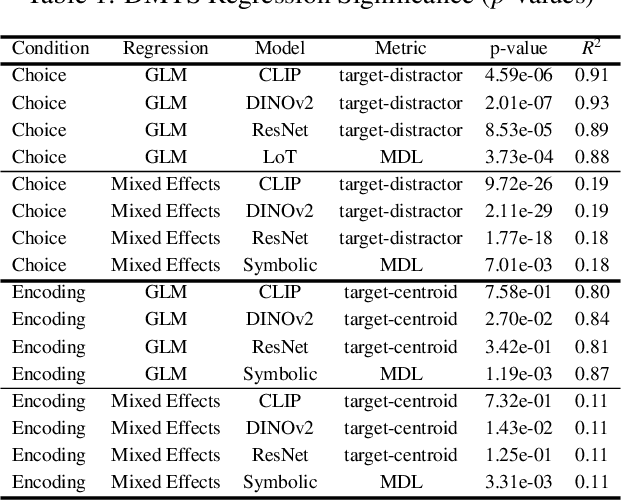


Humans possess a remarkable capacity to recognize and manipulate abstract structure, which is especially apparent in the domain of geometry. Recent research in cognitive science suggests neural networks do not share this capacity, concluding that human geometric abilities come from discrete symbolic structure in human mental representations. However, progress in artificial intelligence (AI) suggests that neural networks begin to demonstrate more human-like reasoning after scaling up standard architectures in both model size and amount of training data. In this study, we revisit empirical results in cognitive science on geometric visual processing and identify three key biases in geometric visual processing: a sensitivity towards complexity, regularity, and the perception of parts and relations. We test tasks from the literature that probe these biases in humans and find that large pre-trained neural network models used in AI demonstrate more human-like abstract geometric processing.
Deep Learning for Suicide and Depression Identification with Unsupervised Label Correction
Feb 18, 2021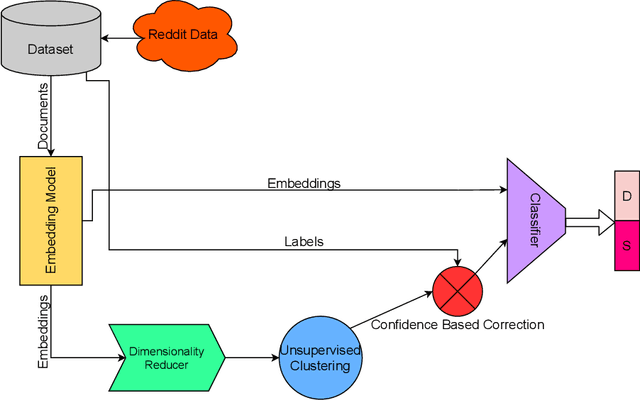
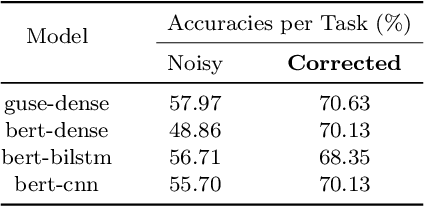


Early detection of suicidal ideation in depressed individuals can allow for adequate medical attention and support, which in many cases is life-saving. Recent NLP research focuses on classifying, from a given piece of text, if an individual is suicidal or clinically healthy. However, there have been no major attempts to differentiate between depression and suicidal ideation, which is an important clinical challenge. Due to the scarce availability of EHR data, suicide notes, or other similar verified sources, web query data has emerged as a promising alternative. Online sources, such as Reddit, allow for anonymity that prompts honest disclosure of symptoms, making it a plausible source even in a clinical setting. However, these online datasets also result in lower performance, which can be attributed to the inherent noise in web-scraped labels, which necessitates a noise-removal process. Thus, we propose SDCNL, a suicide versus depression classification method through a deep learning approach. We utilize online content from Reddit to train our algorithm, and to verify and correct noisy labels, we propose a novel unsupervised label correction method which, unlike previous work, does not require prior noise distribution information. Our extensive experimentation with multiple deep word embedding models and classifiers display the strong performance of the method in anew, challenging classification application. We make our code and dataset available at https://github.com/ayaanzhaque/SDCNL
Context Matters: Recovering Human Semantic Structure from Machine Learning Analysis of Large-Scale Text Corpora
Nov 04, 2019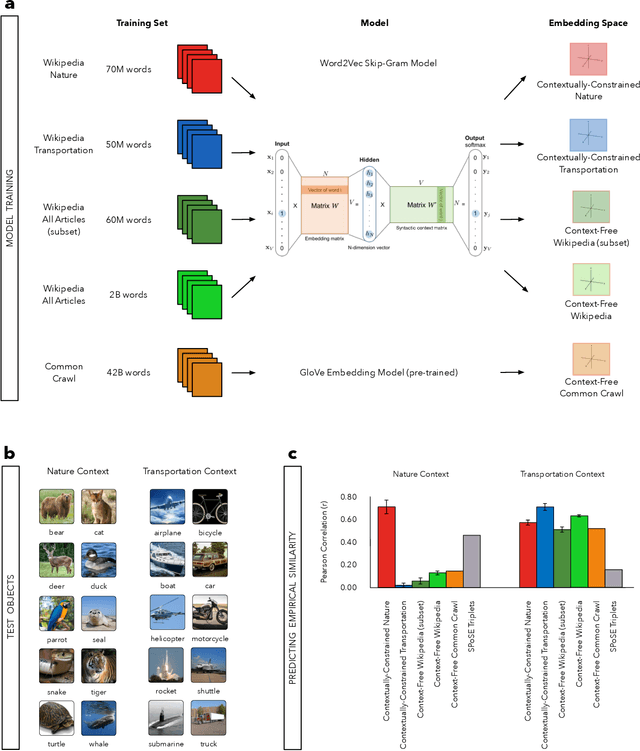
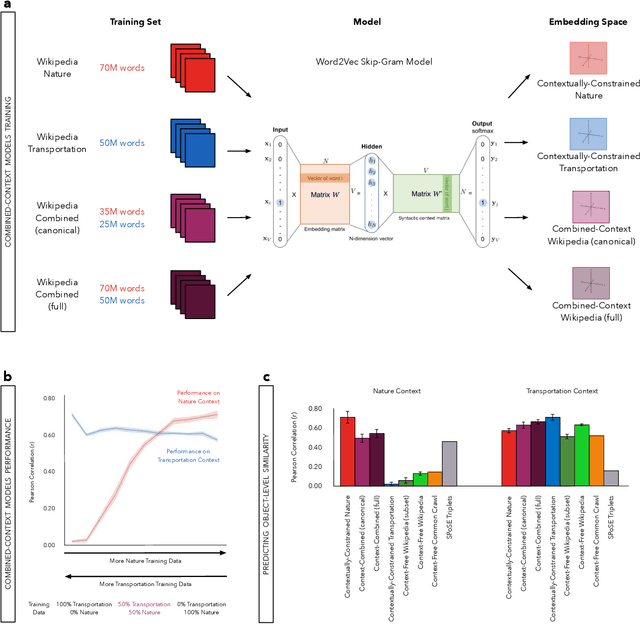
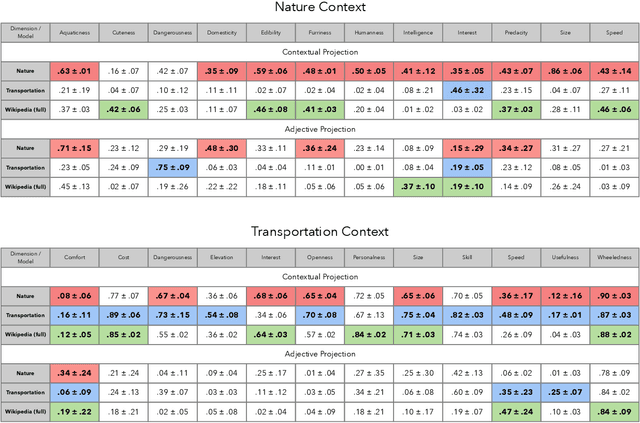
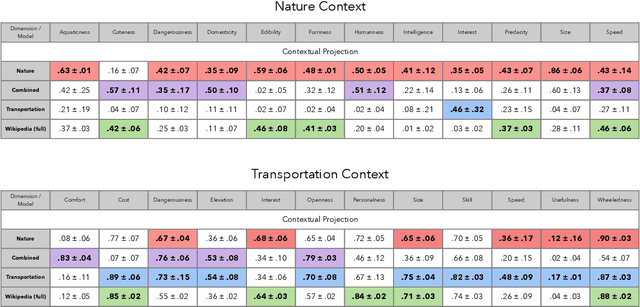
Understanding how human semantic knowledge is organized and how people use it to judge fundamental relationships, such as similarity between concepts, has proven difficult. Theoretical models have consistently failed to provide accurate predictions of human judgments, as has the application of machine learning algorithms to large-scale, text-based corpora (embedding spaces). Based on the hypothesis that context plays a critical role in human cognition, we show that generating embedding spaces using contextually-constrained text corpora greatly improves their ability to predict human judgments. Additionally, we introduce a novel context-based method for extracting interpretable feature information (e.g., size) from embedding spaces. Our findings suggest that contextually-constraining large-scale text corpora, coupled with applying state-of-the-art machine learning algorithms, may improve the correspondence between representations derived using such methods and those underlying human semantic structure. This promises to provide novel insight into human similarity judgments and designing algorithms that can interact effectively with human semantic knowledge.