 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConvolutional Neural Networks Can (Meta-)Learn the Same-Different Relation
Apr 01, 2025While convolutional neural networks (CNNs) have come to match and exceed human performance in many settings, the tasks these models optimize for are largely constrained to the level of individual objects, such as classification and captioning. Humans remain vastly superior to CNNs in visual tasks involving relations, including the ability to identify two objects as `same' or `different'. A number of studies have shown that while CNNs can be coaxed into learning the same-different relation in some settings, they tend to generalize poorly to other instances of this relation. In this work we show that the same CNN architectures that fail to generalize the same-different relation with conventional training are able to succeed when trained via meta-learning, which explicitly encourages abstraction and generalization across tasks.
Understanding the Limits of Vision Language Models Through the Lens of the Binding Problem
Oct 31, 2024



Recent work has documented striking heterogeneity in the performance of state-of-the-art vision language models (VLMs), including both multimodal language models and text-to-image models. These models are able to describe and generate a diverse array of complex, naturalistic images, yet they exhibit surprising failures on basic multi-object reasoning tasks -- such as counting, localization, and simple forms of visual analogy -- that humans perform with near perfect accuracy. To better understand this puzzling pattern of successes and failures, we turn to theoretical accounts of the binding problem in cognitive science and neuroscience, a fundamental problem that arises when a shared set of representational resources must be used to represent distinct entities (e.g., to represent multiple objects in an image), necessitating the use of serial processing to avoid interference. We find that many of the puzzling failures of state-of-the-art VLMs can be explained as arising due to the binding problem, and that these failure modes are strikingly similar to the limitations exhibited by rapid, feedforward processing in the human brain.
The Reasonable Person Standard for AI
Jun 07, 2024As AI systems are increasingly incorporated into domains where human behavior has set the norm, a challenge for AI governance and AI alignment research is to regulate their behavior in a way that is useful and constructive for society. One way to answer this question is to ask: how do we govern the human behavior that the models are emulating? To evaluate human behavior, the American legal system often uses the "Reasonable Person Standard." The idea of "reasonable" behavior comes up in nearly every area of law. The legal system often judges the actions of parties with respect to what a reasonable person would have done under similar circumstances. This paper argues that the reasonable person standard provides useful guidelines for the type of behavior we should develop, probe, and stress-test in models. It explains how reasonableness is defined and used in key areas of the law using illustrative cases, how the reasonable person standard could apply to AI behavior in each of these areas and contexts, and how our societal understanding of "reasonable" behavior provides useful technical goals for AI researchers.
DOCCI: Descriptions of Connected and Contrasting Images
Apr 30, 2024



Vision-language datasets are vital for both text-to-image (T2I) and image-to-text (I2T) research. However, current datasets lack descriptions with fine-grained detail that would allow for richer associations to be learned by models. To fill the gap, we introduce Descriptions of Connected and Contrasting Images (DOCCI), a dataset with long, human-annotated English descriptions for 15k images that were taken, curated and donated by a single researcher intent on capturing key challenges such as spatial relations, counting, text rendering, world knowledge, and more. We instruct human annotators to create comprehensive descriptions for each image; these average 136 words in length and are crafted to clearly distinguish each image from those that are related or similar. Each description is highly compositional and typically encompasses multiple challenges. Through both quantitative and qualitative analyses, we demonstrate that DOCCI serves as an effective training resource for image-to-text generation -- a PaLI 5B model finetuned on DOCCI shows equal or superior results compared to highly-performant larger models like LLaVA-1.5 7B and InstructBLIP 7B. Furthermore, we show that DOCCI is a useful testbed for text-to-image generation, highlighting the limitations of current text-to-image models in capturing long descriptions and fine details.
Concept Alignment
Jan 09, 2024Discussion of AI alignment (alignment between humans and AI systems) has focused on value alignment, broadly referring to creating AI systems that share human values. We argue that before we can even attempt to align values, it is imperative that AI systems and humans align the concepts they use to understand the world. We integrate ideas from philosophy, cognitive science, and deep learning to explain the need for concept alignment, not just value alignment, between humans and machines. We summarize existing accounts of how humans and machines currently learn concepts, and we outline opportunities and challenges in the path towards shared concepts. Finally, we explain how we can leverage the tools already being developed in cognitive science and AI research to accelerate progress towards concept alignment.
Getting aligned on representational alignment
Nov 02, 2023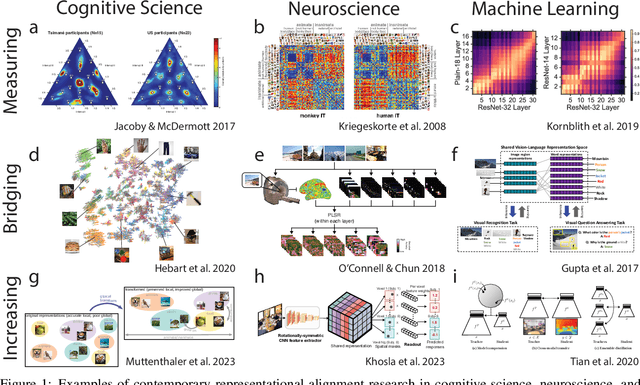
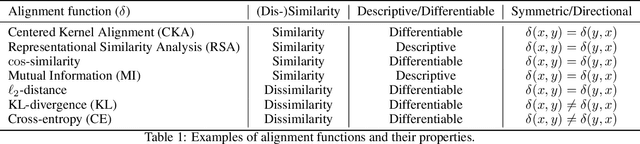
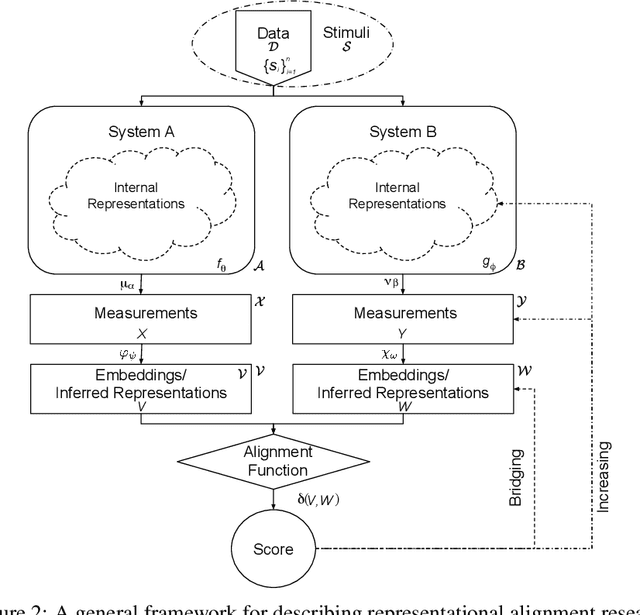
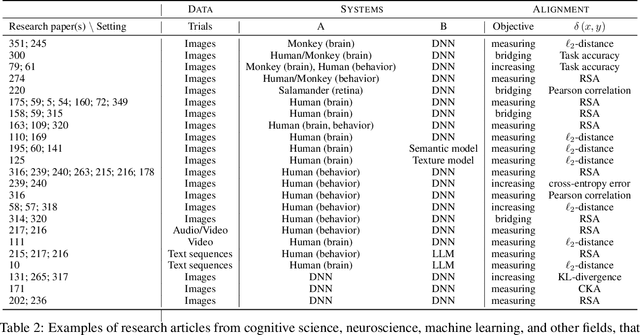
Biological and artificial information processing systems form representations that they can use to categorize, reason, plan, navigate, and make decisions. How can we measure the extent to which the representations formed by these diverse systems agree? Do similarities in representations then translate into similar behavior? How can a system's representations be modified to better match those of another system? These questions pertaining to the study of representational alignment are at the heart of some of the most active research areas in cognitive science, neuroscience, and machine learning. For example, cognitive scientists measure the representational alignment of multiple individuals to identify shared cognitive priors, neuroscientists align fMRI responses from multiple individuals into a shared representational space for group-level analyses, and ML researchers distill knowledge from teacher models into student models by increasing their alignment. Unfortunately, there is limited knowledge transfer between research communities interested in representational alignment, so progress in one field often ends up being rediscovered independently in another. Thus, greater cross-field communication would be advantageous. To improve communication between these fields, we propose a unifying framework that can serve as a common language between researchers studying representational alignment. We survey the literature from all three fields and demonstrate how prior work fits into this framework. Finally, we lay out open problems in representational alignment where progress can benefit all three of these fields. We hope that our work can catalyze cross-disciplinary collaboration and accelerate progress for all communities studying and developing information processing systems. We note that this is a working paper and encourage readers to reach out with their suggestions for future revisions.
Concept Alignment as a Prerequisite for Value Alignment
Oct 30, 2023



Value alignment is essential for building AI systems that can safely and reliably interact with people. However, what a person values -- and is even capable of valuing -- depends on the concepts that they are currently using to understand and evaluate what happens in the world. The dependence of values on concepts means that concept alignment is a prerequisite for value alignment -- agents need to align their representation of a situation with that of humans in order to successfully align their values. Here, we formally analyze the concept alignment problem in the inverse reinforcement learning setting, show how neglecting concept alignment can lead to systematic value mis-alignment, and describe an approach that helps minimize such failure modes by jointly reasoning about a person's concepts and values. Additionally, we report experimental results with human participants showing that humans reason about the concepts used by an agent when acting intentionally, in line with our joint reasoning model.